 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubleDiffusion: Combining Heat Diffusion with Denoising Diffusion for Generative Learning on 3D Meshes
Jan 06, 2025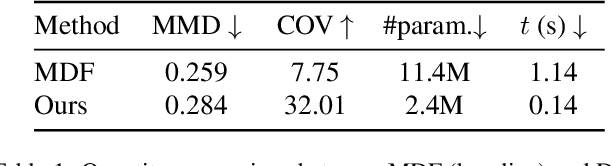

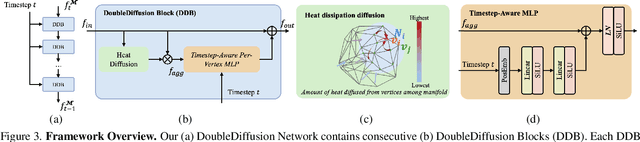

This paper proposes DoubleDiffusion, a novel framework that combines heat dissipation diffusion and denoising diffusion for direct generative learning on 3D mesh surfaces. Our approach addresses the challenges of generating continuous signal distributions residing on a curve manifold surface. Unlike previous methods that rely on unrolling 3D meshes into 2D or adopting field representations, DoubleDiffusion leverages the Laplacian-Beltrami operator to process features respecting the mesh structure. This combination enables effective geometry-aware signal diffusion across the underlying geometry. As shown in Fig.~\ref{fig:teaser}, we demonstrate that DoubleDiffusion has the ability to generate RGB signal distributions on complex 3D mesh surfaces and achieves per-category shape-conditioned texture generation across different shape geometry. Our work contributes a new direction in diffusion-based generative modeling on 3D surfaces, with potential applications in the field of 3D asset generation.
JADE: Joint-aware Latent Diffusion for 3D Human Generative Modeling
Dec 29, 2024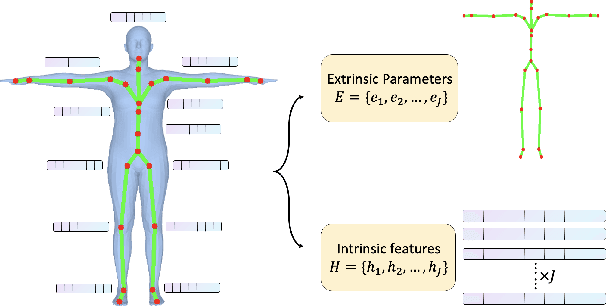
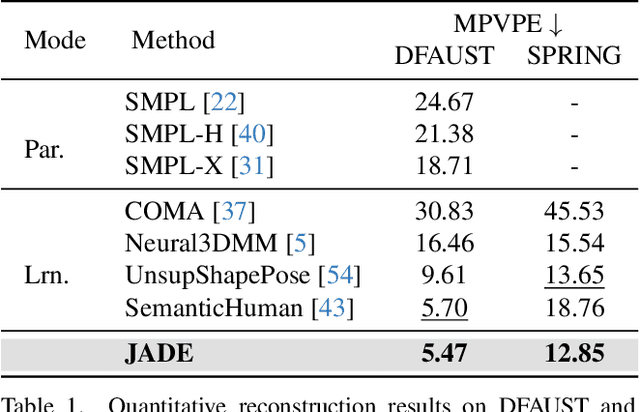
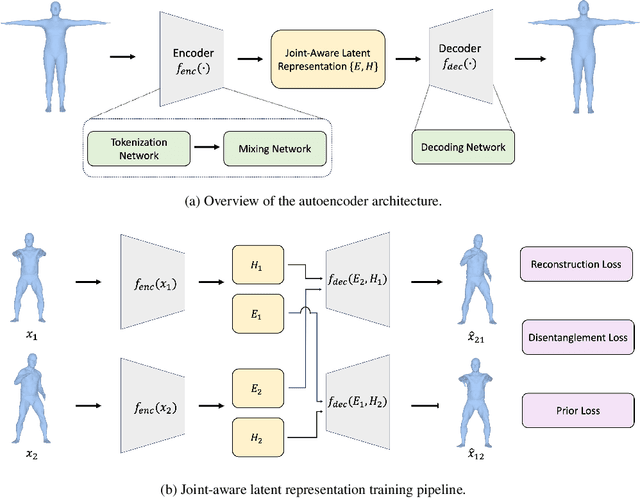
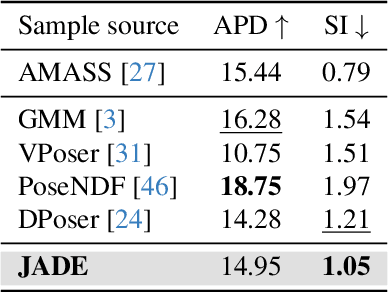
Generative modeling of 3D human bodies have been studied extensively in computer vision. The core is to design a compact latent representation that is both expressive and semantically interpretable, yet existing approaches struggle to achieve both requirements. In this work, we introduce JADE, a generative framework that learns the variations of human shapes with fined-grained control. Our key insight is a joint-aware latent representation that decomposes human bodies into skeleton structures, modeled by joint positions, and local surface geometries, characterized by features attached to each joint. This disentangled latent space design enables geometric and semantic interpretation, facilitating users with flexible controllability. To generate coherent and plausible human shapes under our proposed decomposition, we also present a cascaded pipeline where two diffusions are employed to model the distribution of skeleton structures and local surface geometries respectively. Extensive experiments are conducted on public datasets, where we demonstrate the effectiveness of JADE framework in multiple tasks in terms of autoencoding reconstruction accuracy, editing controllability and generation quality compared with existing methods.
DPBridge: Latent Diffusion Bridge for Dense Prediction
Dec 29, 2024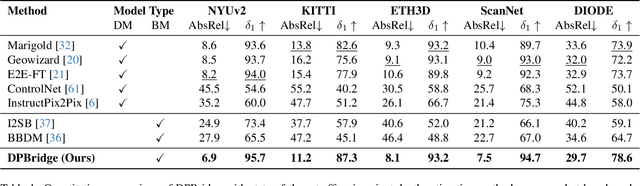
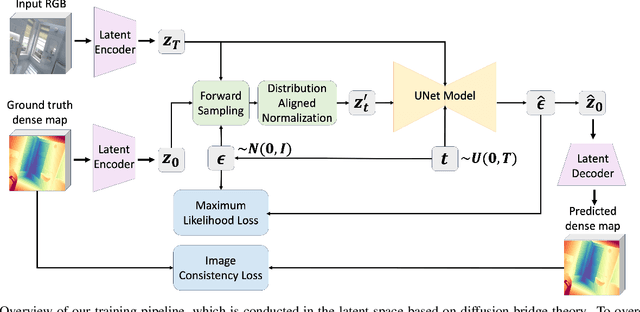
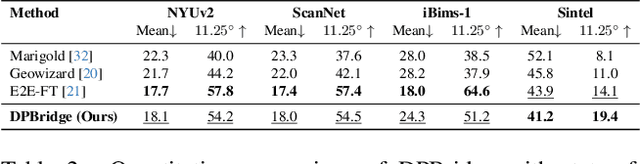

Diffusion models have demonstrated remarkable success in dense prediction problems, which aims to model per-pixel relationship between RGB images and dense signal maps, thanks to their ability to effectively capture complex data distributions. However, initiating the reverse sampling trajectory from uninformative noise prior introduces limitations such as degraded performance and slow inference speed. In this work, we propose DPBridge, a generative framework that formulates dense prediction tasks as image-conditioned generation problems and establishes a direct mapping between input image and its corresponding dense map based on fully-tractable diffusion bridge process. This approach addresses aforementioned limitations in conventional diffusion-based solutions. In addition, we introduce finetuning strategies to adapt our model from pretrained image diffusion backbone, leveraging its rich visual prior knowledge to facilitate both efficient training and robust generalization ability. Experimental results shows that our DPBridge can achieve competitive performance compared to both feed-forward and diffusion-based approaches across various benchmarks, highlighting its effectiveness and adaptability.
3D Human Pose Analysis via Diffusion Synthesis
Jan 17, 2024



Diffusion models have demonstrated remarkable success in generative modeling. In this paper, we propose PADS (Pose Analysis by Diffusion Synthesis), a novel framework designed to address various challenges in 3D human pose analysis through a unified pipeline. Central to PADS are two distinctive strategies: i) learning a task-agnostic pose prior using a diffusion synthesis process to effectively capture the kinematic constraints in human pose data, and ii) unifying multiple pose analysis tasks like estimation, completion, denoising, etc, as instances of inverse problems. The learned pose prior will be treated as a regularization imposing on task-specific constraints, guiding the optimization process through a series of conditional denoising steps. PADS represents the first diffusion-based framework for tackling general 3D human pose analysis within the inverse problem framework. Its performance has been validated on different benchmarks, signaling the adaptability and robustness of this pipeline.
Unsupervised 3D Pose Estimation with Non-Rigid Structure-from-Motion Modeling
Aug 18, 2023Most of the previous 3D human pose estimation work relied on the powerful memory capability of the network to obtain suitable 2D-3D mappings from the training data. Few works have studied the modeling of human posture deformation in motion. In this paper, we propose a new modeling method for human pose deformations and design an accompanying diffusion-based motion prior. Inspired by the field of non-rigid structure-from-motion, we divide the task of reconstructing 3D human skeletons in motion into the estimation of a 3D reference skeleton, and a frame-by-frame skeleton deformation. A mixed spatial-temporal NRSfMformer is used to simultaneously estimate the 3D reference skeleton and the skeleton deformation of each frame from 2D observations sequence, and then sum them to obtain the pose of each frame. Subsequently, a loss term based on the diffusion model is used to ensure that the pipeline learns the correct prior motion knowledge. Finally, we have evaluated our proposed method on mainstream datasets and obtained superior results outperforming the state-of-the-art.