 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRainbow Delay Compensation: A Multi-Agent Reinforcement Learning Framework for Mitigating Delayed Observation
May 06, 2025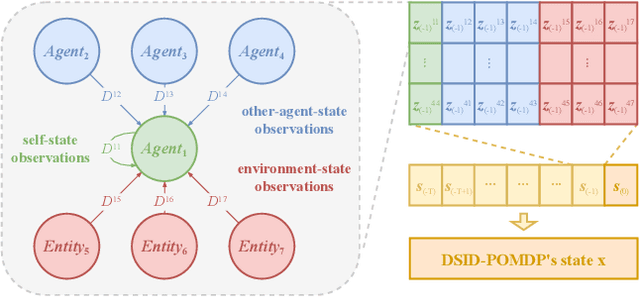

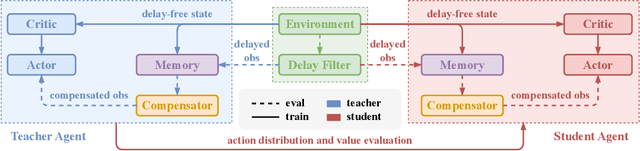
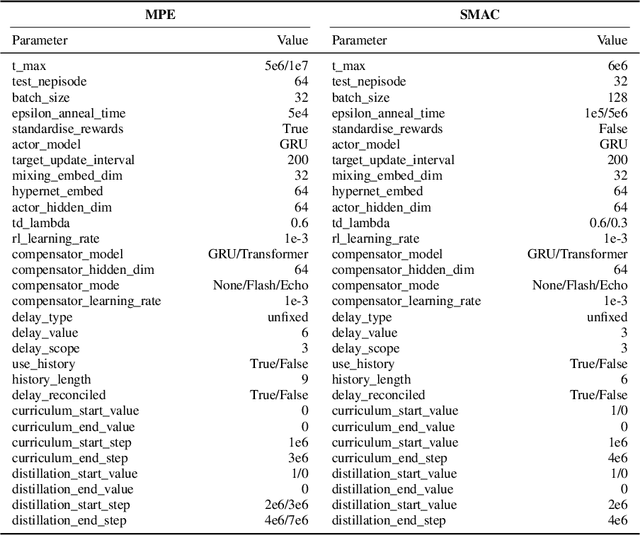
In real-world multi-agent systems (MASs), observation delays are ubiquitous, preventing agents from making decisions based on the environment's true state. An individual agent's local observation often consists of multiple components from other agents or dynamic entities in the environment. These discrete observation components with varying delay characteristics pose significant challenges for multi-agent reinforcement learning (MARL). In this paper, we first formulate the decentralized stochastic individual delay partially observable Markov decision process (DSID-POMDP) by extending the standard Dec-POMDP. We then propose the Rainbow Delay Compensation (RDC), a MARL training framework for addressing stochastic individual delays, along with recommended implementations for its constituent modules. We implement the DSID-POMDP's observation generation pattern using standard MARL benchmarks, including MPE and SMAC. Experiments demonstrate that baseline MARL methods suffer severe performance degradation under fixed and unfixed delays. The RDC-enhanced approach mitigates this issue, remarkably achieving ideal delay-free performance in certain delay scenarios while maintaining generalization capability. Our work provides a novel perspective on multi-agent delayed observation problems and offers an effective solution framework.
Automatic Text Pronunciation Correlation Generation and Application for Contextual Biasing
Jan 01, 2025



Effectively distinguishing the pronunciation correlations between different written texts is a significant issue in linguistic acoustics. Traditionally, such pronunciation correlations are obtained through manually designed pronunciation lexicons. In this paper, we propose a data-driven method to automatically acquire these pronunciation correlations, called automatic text pronunciation correlation (ATPC). The supervision required for this method is consistent with the supervision needed for training end-to-end automatic speech recognition (E2E-ASR) systems, i.e., speech and corresponding text annotations. First, the iteratively-trained timestamp estimator (ITSE) algorithm is employed to align the speech with their corresponding annotated text symbols. Then, a speech encoder is used to convert the speech into speech embeddings. Finally, we compare the speech embeddings distances of different text symbols to obtain ATPC. Experimental results on Mandarin show that ATPC enhances E2E-ASR performance in contextual biasing and holds promise for dialects or languages lacking artificial pronunciation lexicons.
QTypeMix: Enhancing Multi-Agent Cooperative Strategies through Heterogeneous and Homogeneous Value Decomposition
Aug 12, 2024In multi-agent cooperative tasks, the presence of heterogeneous agents is familiar. Compared to cooperation among homogeneous agents, collaboration requires considering the best-suited sub-tasks for each agent. However, the operation of multi-agent systems often involves a large amount of complex interaction information, making it more challenging to learn heterogeneous strategies. Related multi-agent reinforcement learning methods sometimes use grouping mechanisms to form smaller cooperative groups or leverage prior domain knowledge to learn strategies for different roles. In contrast, agents should learn deeper role features without relying on additional information. Therefore, we propose QTypeMix, which divides the value decomposition process into homogeneous and heterogeneous stages. QTypeMix learns to extract type features from local historical observations through the TE loss. In addition, we introduce advanced network structures containing attention mechanisms and hypernets to enhance the representation capability and achieve the value decomposition process. The results of testing the proposed method on 14 maps from SMAC and SMACv2 show that QTypeMix achieves state-of-the-art performance in tasks of varying difficulty.
Improving Streaming End-to-End ASR on Transformer-based Causal Models with Encoder States Revision Strategies
Jul 06, 2022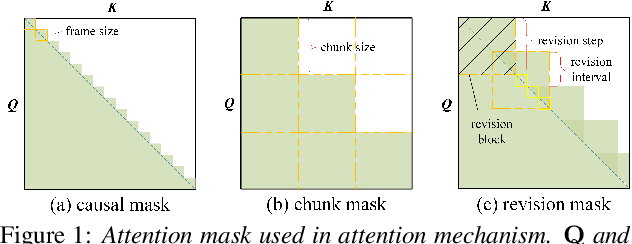
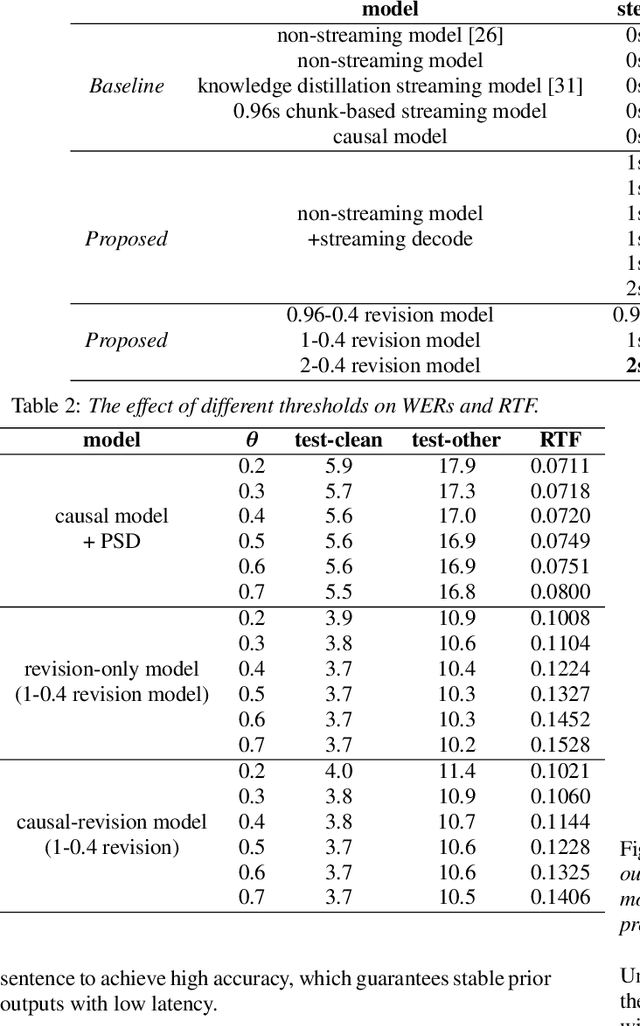
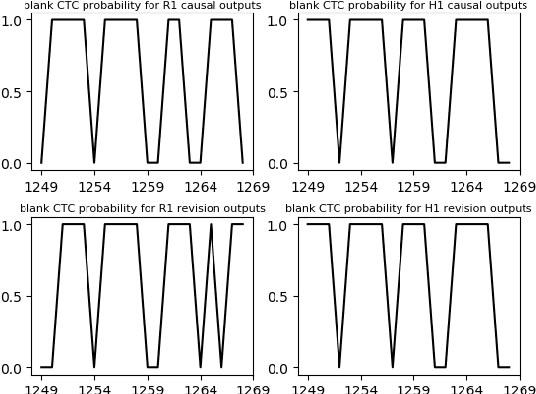
There is often a trade-off between performance and latency in streaming automatic speech recognition (ASR). Traditional methods such as look-ahead and chunk-based methods, usually require information from future frames to advance recognition accuracy, which incurs inevitable latency even if the computation is fast enough. A causal model that computes without any future frames can avoid this latency, but its performance is significantly worse than traditional methods. In this paper, we propose corresponding revision strategies to improve the causal model. Firstly, we introduce a real-time encoder states revision strategy to modify previous states. Encoder forward computation starts once the data is received and revises the previous encoder states after several frames, which is no need to wait for any right context. Furthermore, a CTC spike position alignment decoding algorithm is designed to reduce time costs brought by the revision strategy. Experiments are all conducted on Librispeech datasets. Fine-tuning on the CTC-based wav2vec2.0 model, our best method can achieve 3.7/9.2 WERs on test-clean/other sets, which is also competitive with the chunk-based methods and the knowledge distillation methods.
Improved Conformer-based End-to-End Speech Recognition Using Neural Architecture Search
Apr 13, 2021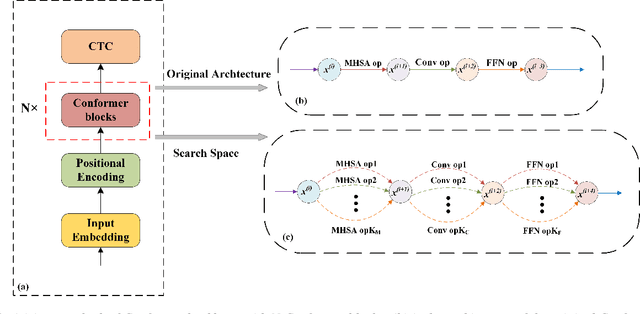


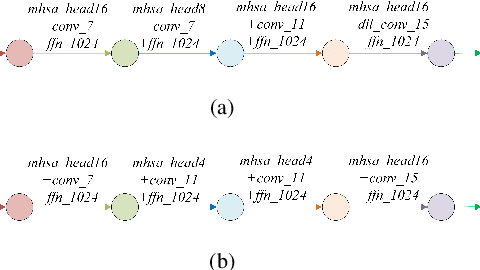
Recently neural architecture search(NAS) has been successfully used in image classification, natural language processing, and automatic speech recognition(ASR) tasks for finding the state-of-the-art(SOTA) architectures than those human-designed architectures. NAS can derive a SOTA and data-specific architecture over validation data from a pre-defined search space with a search algorithm. Inspired by the success of NAS in ASR tasks, we propose a NAS-based ASR framework containing one search space and one differentiable search algorithm called Differentiable Architecture Search(DARTS). Our search space follows the convolution-augmented transformer(Conformer) backbone, which is a more expressive ASR architecture than those used in existing NAS-based ASR frameworks. To improve the performance of our method, a regulation method called Dynamic Search Schedule(DSS) is employed. On a widely used Mandarin benchmark AISHELL-1, our best-searched architecture outperforms the baseline Conform model significantly with about 11% CER relative improvement, and our method is proved to be pretty efficient by the search cost comparisons.