 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSTBench: Beyond Semantic Evaluation for Speech Translation
May 29, 2026Speech translation systems increasingly span speech-to-text translation (S2TT), speech-to-speech translation (S2ST), offline translation, and streaming generation, producing outputs that differ in modality, speech realization, and timing behavior. Existing evaluation practices assess important aspects such as translation quality, speech quality, and temporal quality, but these aspects are often evaluated under separate protocols, making it difficult to compare heterogeneous systems comprehensively. To address this gap, we present OpenSTBench, a unified multidimensional evaluation framework that organizes heterogeneous speech translation outputs into a shared evaluation format. OpenSTBench supports both S2TT and S2ST systems in offline and streaming settings, and jointly evaluates translation quality, speech quality, speaker preservation, emotion and paralinguistic fidelity, temporal consistency, and latency. Through experiments on representative speech translation systems, we show that systems with strong translation quality can still differ substantially in speech quality, as well as in temporal quality. OpenSTBench provides a reproducible protocol for analyzing these cross-dimensional differences and supporting application-oriented comparison of speech translation systems. The code and datasets are available at https://github.com/sjtuayj/OpenSTBench.
UNIQUE: Universal Top-k Sparse Attention for Training-free Inference and Sparsity-aware Training
May 26, 2026Long-context inference in large language models (LLMs) is bottlenecked by the linear growth of the self-attention key-value (KV) cache. Top-k sparse attention alleviates this by loading only a small fraction of the KV cache, but accurately and cheaply estimating cache importance, for both training-free use and sparsity-aware training, remains challenging. This paper proposes UNIQUE, a universal top-k sparse attention framework that addresses both requirements and stays consistently effective across LLM modalities. UNIQUE operates at the granularity of KV pages and estimates per-page importance with a simple yet accurate score combining the mean of the page's keys as a representative vector with their standard deviation as an offset term. To further close the train-inference gap, this paper introduces a soft-mask sparsity-aware training scheme that uses the top-k score boundary as a per-query threshold and a sigmoid soft mask around it, requiring neither auxiliary losses nor architectural changes. Experiments on text and speech LLMs show that UNIQUE preserves task performance on long-context benchmarks such as LongBench Pro and on long-form speech recognition, while delivering up to 11.4x attention-kernel speedup over FlashInfer dense attention and at least 5.3x end-to-end decoding speedup over a vLLM-based dense model.
Speech LLMs are Contextual Reasoning Transcribers
Apr 01, 2026Despite extensions to speech inputs, effectively leveraging the rich knowledge and contextual understanding of large language models (LLMs) in automatic speech recognition (ASR) remains non-trivial, as the task primarily involves direct speech-to-text mapping. To address this, this paper proposes chain-of-thought ASR (CoT-ASR), which constructs a reasoning chain that enables LLMs to first analyze the input speech and generate contextual analysis, thereby fully exploiting their generative capabilities. With this contextual reasoning, CoT-ASR then performs more informed speech recognition and completes both reasoning and transcription in a single pass. Moreover, CoT-ASR naturally supports user-guided transcription: while designed to self-generate reasoning, it can also seamlessly incorporate user-provided context to guide transcription, further extending ASR functionality. To reduce the modality gap, this paper introduces a CTC-guided Modality Adapter, which uses CTC non-blank token probabilities to weight LLM embeddings, efficiently aligning speech encoder outputs with the LLM's textual latent space. Experiments show that, compared to standard LLM-based ASR, CoT-ASR achieves a relative reduction of 8.7% in word error rate (WER) and 16.9% in entity error rate (EER).
SimulS2S-LLM: Unlocking Simultaneous Inference of Speech LLMs for Speech-to-Speech Translation
Apr 22, 2025



Simultaneous speech translation (SST) outputs translations in parallel with streaming speech input, balancing translation quality and latency. While large language models (LLMs) have been extended to handle the speech modality, streaming remains challenging as speech is prepended as a prompt for the entire generation process. To unlock LLM streaming capability, this paper proposes SimulS2S-LLM, which trains speech LLMs offline and employs a test-time policy to guide simultaneous inference. SimulS2S-LLM alleviates the mismatch between training and inference by extracting boundary-aware speech prompts that allows it to be better matched with text input data. SimulS2S-LLM achieves simultaneous speech-to-speech translation (Simul-S2ST) by predicting discrete output speech tokens and then synthesising output speech using a pre-trained vocoder. An incremental beam search is designed to expand the search space of speech token prediction without increasing latency. Experiments on the CVSS speech data show that SimulS2S-LLM offers a better translation quality-latency trade-off than existing methods that use the same training data, such as improving ASR-BLEU scores by 3 points at similar latency.
Transducer-Llama: Integrating LLMs into Streamable Transducer-based Speech Recognition
Dec 21, 2024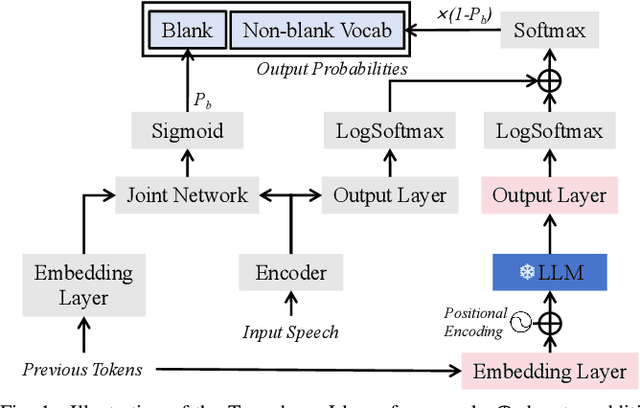
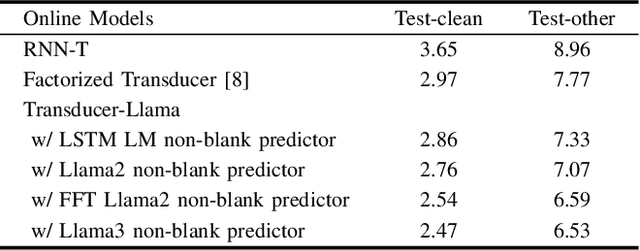
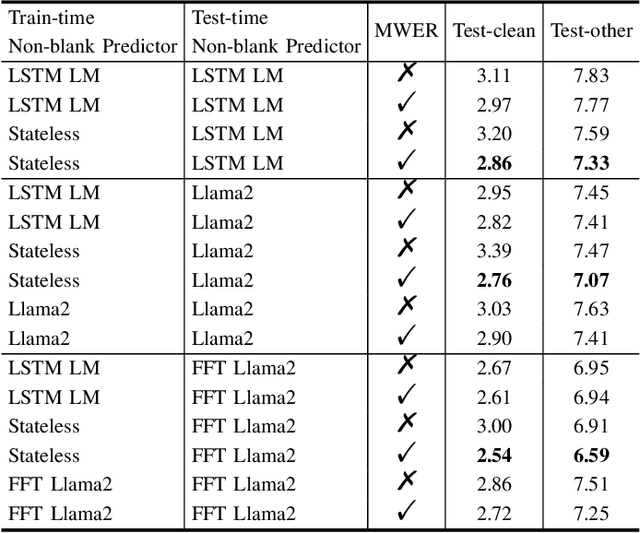
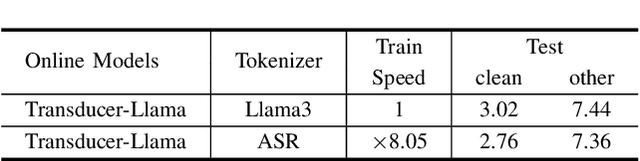
While large language models (LLMs) have been applied to automatic speech recognition (ASR), the task of making the model streamable remains a challenge. This paper proposes a novel model architecture, Transducer-Llama, that integrates LLMs into a Factorized Transducer (FT) model, naturally enabling streaming capabilities. Furthermore, given that the large vocabulary of LLMs can cause data sparsity issue and increased training costs for spoken language systems, this paper introduces an efficient vocabulary adaptation technique to align LLMs with speech system vocabularies. The results show that directly optimizing the FT model with a strong pre-trained LLM-based predictor using the RNN-T loss yields some but limited improvements over a smaller pre-trained LM predictor. Therefore, this paper proposes a weak-to-strong LM swap strategy, using a weak LM predictor during RNN-T loss training and then replacing it with a strong LLM. After LM replacement, the minimum word error rate (MWER) loss is employed to finetune the integration of the LLM predictor with the Transducer-Llama model. Experiments on the LibriSpeech and large-scale multi-lingual LibriSpeech corpora show that the proposed streaming Transducer-Llama approach gave a 17% relative WER reduction (WERR) over a strong FT baseline and a 32% WERR over an RNN-T baseline.
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
Oct 09, 2024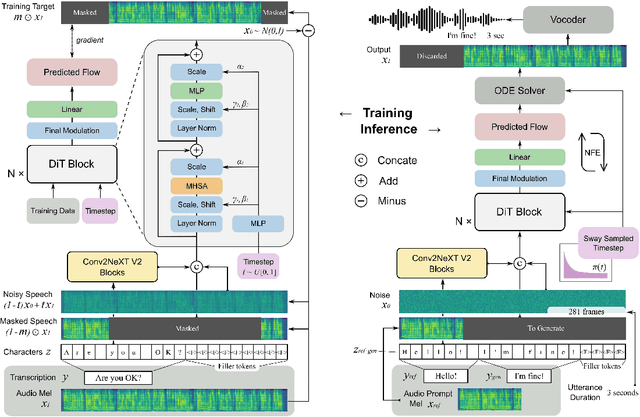
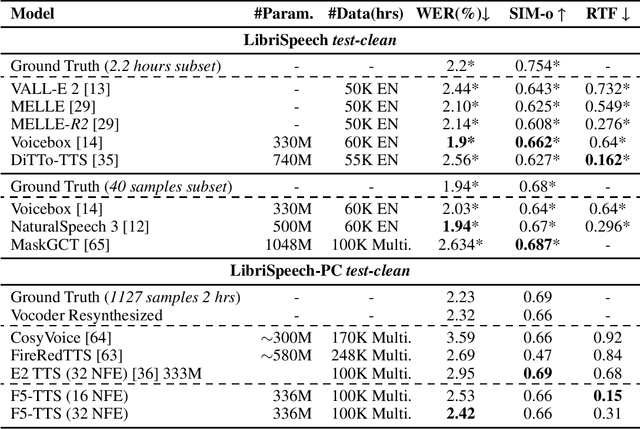
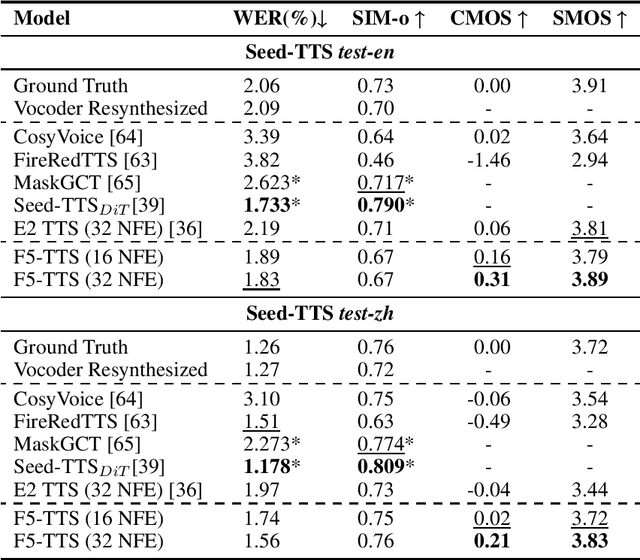
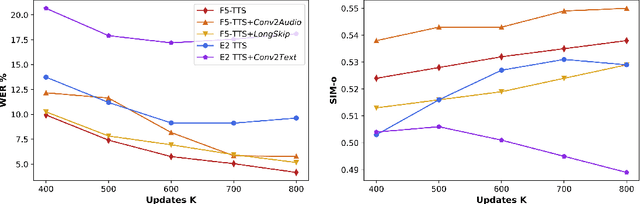
This paper introduces F5-TTS, a fully non-autoregressive text-to-speech system based on flow matching with Diffusion Transformer (DiT). Without requiring complex designs such as duration model, text encoder, and phoneme alignment, the text input is simply padded with filler tokens to the same length as input speech, and then the denoising is performed for speech generation, which was originally proved feasible by E2 TTS. However, the original design of E2 TTS makes it hard to follow due to its slow convergence and low robustness. To address these issues, we first model the input with ConvNeXt to refine the text representation, making it easy to align with the speech. We further propose an inference-time Sway Sampling strategy, which significantly improves our model's performance and efficiency. This sampling strategy for flow step can be easily applied to existing flow matching based models without retraining. Our design allows faster training and achieves an inference RTF of 0.15, which is greatly improved compared to state-of-the-art diffusion-based TTS models. Trained on a public 100K hours multilingual dataset, our Fairytaler Fakes Fluent and Faithful speech with Flow matching (F5-TTS) exhibits highly natural and expressive zero-shot ability, seamless code-switching capability, and speed control efficiency. Demo samples can be found at https://SWivid.github.io/F5-TTS. We release all code and checkpoints to promote community development.
CoT-ST: Enhancing LLM-based Speech Translation with Multimodal Chain-of-Thought
Sep 29, 2024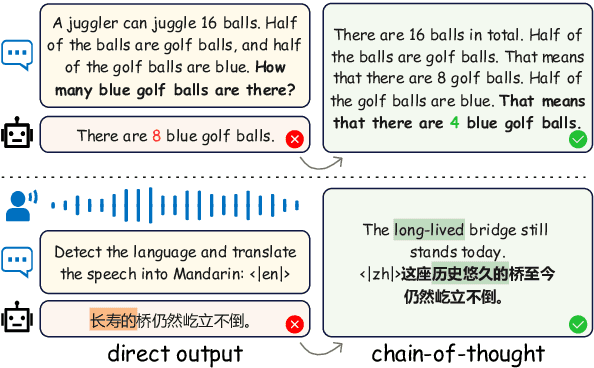

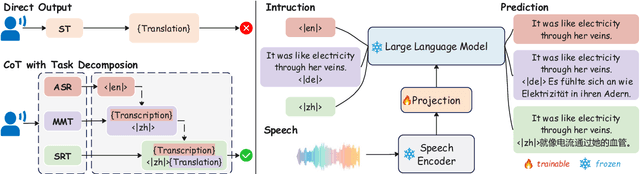
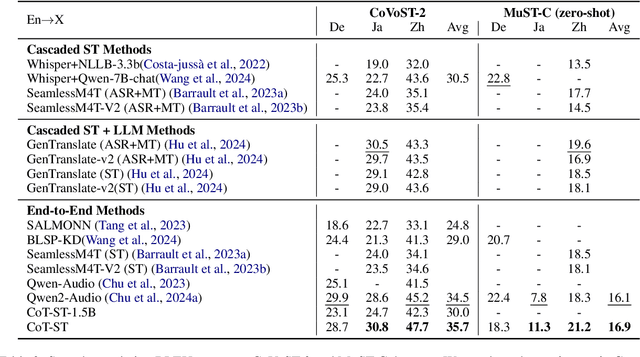
Speech Language Models (SLMs) have demonstrated impressive performance on speech translation tasks. However, existing research primarily focuses on direct instruction fine-tuning and often overlooks the inherent reasoning capabilities of SLMs. In this paper, we introduce a three-stage training framework designed to activate the chain-of-thought (CoT) capabilities of SLMs. We propose CoT-ST, a speech translation model that utilizes multimodal CoT to decompose speech translation into sequential steps of speech recognition and translation. We validated the effectiveness of our method on two datasets: the CoVoST-2 dataset and MuST-C dataset. The experimental results demonstrate that CoT-ST outperforms previous state-of-the-art methods, achieving higher BLEU scores (CoVoST-2 en-ja: 30.5->30.8, en-zh: 45.2->47.7, MuST-C en-zh: 19.6->21.2). This work is open sourced at https://github.com/X-LANCE/SLAM-LLM/tree/main/examples/st_covost2 .
Label-Synchronous Neural Transducer for E2E Simultaneous Speech Translation
Jun 06, 2024



While the neural transducer is popular for online speech recognition, simultaneous speech translation (SST) requires both streaming and re-ordering capabilities. This paper presents the LS-Transducer-SST, a label-synchronous neural transducer for SST, which naturally possesses these two properties. The LS-Transducer-SST dynamically decides when to emit translation tokens based on an Auto-regressive Integrate-and-Fire (AIF) mechanism. A latency-controllable AIF is also proposed, which can control the quality-latency trade-off either only during decoding, or it can be used in both decoding and training. The LS-Transducer-SST can naturally utilise monolingual text-only data via its prediction network which helps alleviate the key issue of data sparsity for E2E SST. During decoding, a chunk-based incremental joint decoding technique is designed to refine and expand the search space. Experiments on the Fisher-CallHome Spanish (Es-En) and MuST-C En-De data show that the LS-Transducer-SST gives a better quality-latency trade-off than existing popular methods. For example, the LS-Transducer-SST gives a 3.1/2.9 point BLEU increase (Es-En/En-De) relative to CAAT at a similar latency and a 1.4 s reduction in average lagging latency with similar BLEU scores relative to Wait-k.
Wav2Prompt: End-to-End Speech Prompt Generation and Tuning For LLM in Zero and Few-shot Learning
Jun 01, 2024



Wav2Prompt is proposed which allows straightforward integration between spoken input and a text-based large language model (LLM). Wav2Prompt uses a simple training process with only the same data used to train an automatic speech recognition (ASR) model. After training, Wav2Prompt learns continuous representations from speech and uses them as LLM prompts. To avoid task over-fitting issues found in prior work and preserve the emergent abilities of LLMs, Wav2Prompt takes LLM token embeddings as the training targets and utilises a continuous integrate-and-fire mechanism for explicit speech-text alignment. Therefore, a Wav2Prompt-LLM combination can be applied to zero-shot spoken language tasks such as speech translation (ST), speech understanding (SLU), speech question answering (SQA) and spoken-query-based QA (SQQA). It is shown that for these zero-shot tasks, Wav2Prompt performs similarly to an ASR-LLM cascade and better than recent prior work. If relatively small amounts of task-specific paired data are available in few-shot scenarios, the Wav2Prompt-LLM combination can be end-to-end (E2E) fine-tuned. The Wav2Prompt-LLM combination then yields greatly improved results relative to an ASR-LLM cascade for the above tasks. For instance, for English-French ST with the BLOOMZ-7B1 LLM, a Wav2Prompt-LLM combination gave a 8.5 BLEU point increase over an ASR-LLM cascade.
FastInject: Injecting Unpaired Text Data into CTC-based ASR training
Dec 14, 2023Recently, connectionist temporal classification (CTC)-based end-to-end (E2E) automatic speech recognition (ASR) models have achieved impressive results, especially with the development of self-supervised learning. However, E2E ASR models trained on paired speech-text data often suffer from domain shifts from training to testing. To alleviate this issue, this paper proposes a flat-start joint training method, named FastInject, which efficiently injects multi-domain unpaired text data into CTC-based ASR training. To maintain training efficiency, text units are pre-upsampled, and their representations are fed into the CTC model along with speech features. To bridge the modality gap between speech and text, an attention-based modality matching mechanism (AM3) is proposed, which retains the E2E flat-start training. Experiments show that the proposed FastInject gave a 22\% relative WER reduction (WERR) for intra-domain Librispeech-100h data and 20\% relative WERR on out-of-domain test sets.