 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Speech Tokenizers with Diffusion Autoencoders
Feb 06, 2026Speech tokenizers are foundational to speech language models, yet existing approaches face two major challenges: (1) balancing trade-offs between encoding semantics for understanding and acoustics for reconstruction, and (2) achieving low bit rates and low token rates. We propose Speech Diffusion Tokenizer (SiTok), a diffusion autoencoder that jointly learns semantic-rich representations through supervised learning and enables high-fidelity audio reconstruction with diffusion. We scale SiTok to 1.6B parameters and train it on 2 million hours of speech. Experiments show that SiTok outperforms strong baselines on understanding, reconstruction and generation tasks, at an extremely low token rate of $12.5$ Hz and a bit-rate of 200 bits-per-second.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Transducer-Llama: Integrating LLMs into Streamable Transducer-based Speech Recognition
Dec 21, 2024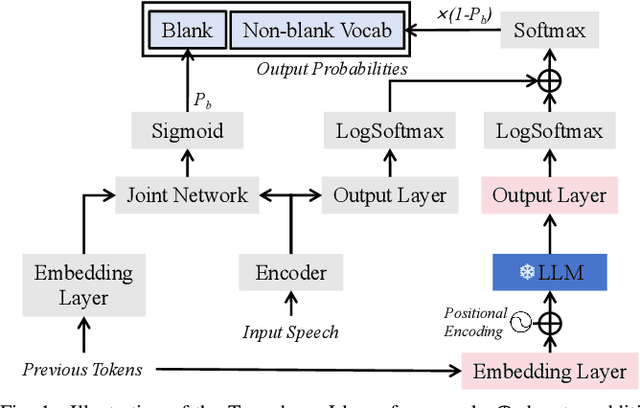
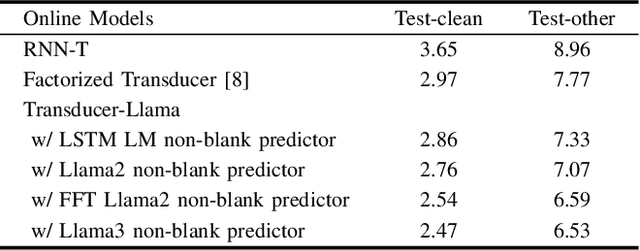
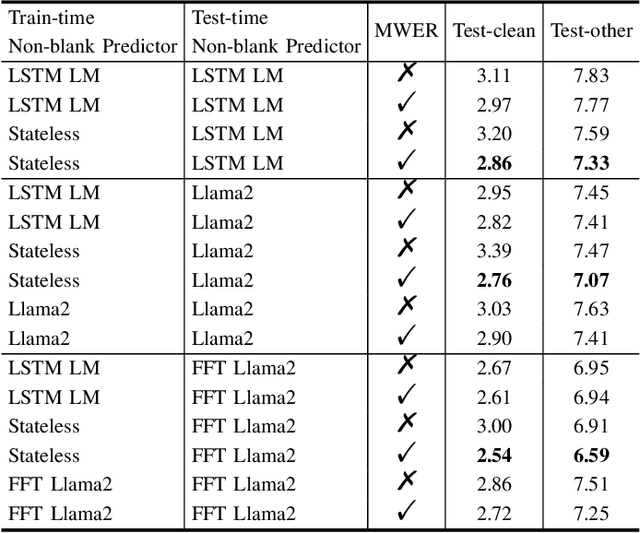
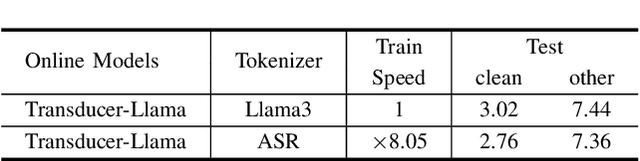
While large language models (LLMs) have been applied to automatic speech recognition (ASR), the task of making the model streamable remains a challenge. This paper proposes a novel model architecture, Transducer-Llama, that integrates LLMs into a Factorized Transducer (FT) model, naturally enabling streaming capabilities. Furthermore, given that the large vocabulary of LLMs can cause data sparsity issue and increased training costs for spoken language systems, this paper introduces an efficient vocabulary adaptation technique to align LLMs with speech system vocabularies. The results show that directly optimizing the FT model with a strong pre-trained LLM-based predictor using the RNN-T loss yields some but limited improvements over a smaller pre-trained LM predictor. Therefore, this paper proposes a weak-to-strong LM swap strategy, using a weak LM predictor during RNN-T loss training and then replacing it with a strong LLM. After LM replacement, the minimum word error rate (MWER) loss is employed to finetune the integration of the LLM predictor with the Transducer-Llama model. Experiments on the LibriSpeech and large-scale multi-lingual LibriSpeech corpora show that the proposed streaming Transducer-Llama approach gave a 17% relative WER reduction (WERR) over a strong FT baseline and a 32% WERR over an RNN-T baseline.
Get Large Language Models Ready to Speak: A Late-fusion Approach for Speech Generation
Oct 27, 2024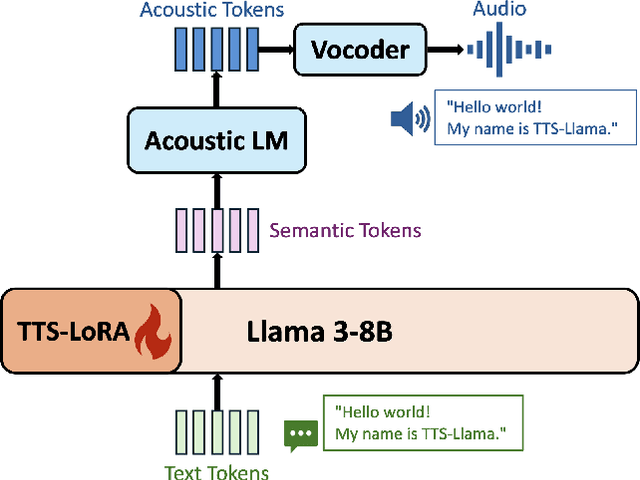
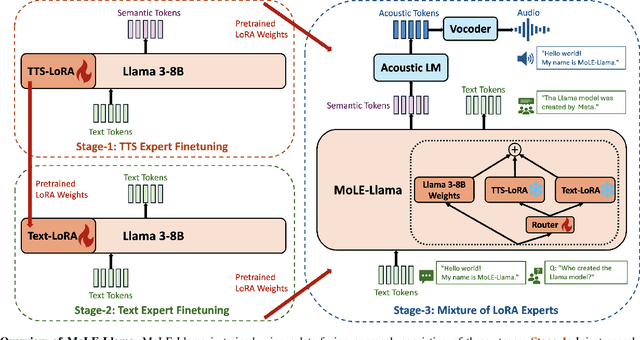
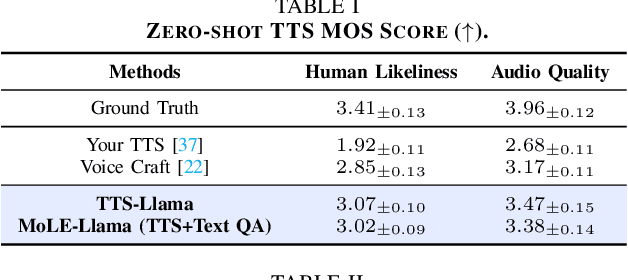
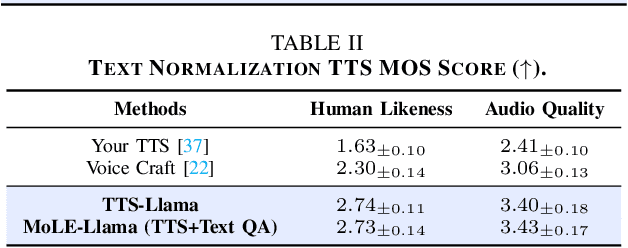
Large language models (LLMs) have revolutionized natural language processing (NLP) with impressive performance across various text-based tasks. However, the extension of text-dominant LLMs to with speech generation tasks remains under-explored. In this work, we introduce a text-to-speech (TTS) system powered by a fine-tuned Llama model, named TTS-Llama, that achieves state-of-the-art speech synthesis performance. Building on TTS-Llama, we further propose MoLE-Llama, a text-and-speech multimodal LLM developed through purely late-fusion parameter-efficient fine-tuning (PEFT) and a mixture-of-expert architecture. Extensive empirical results demonstrate MoLE-Llama's competitive performance on both text-only question-answering (QA) and TTS tasks, mitigating catastrophic forgetting issue in either modality. Finally, we further explore MoLE-Llama in text-in-speech-out QA tasks, demonstrating its great potential as a multimodal dialog system capable of speech generation.
Effective internal language model training and fusion for factorized transducer model
Apr 02, 2024


The internal language model (ILM) of the neural transducer has been widely studied. In most prior work, it is mainly used for estimating the ILM score and is subsequently subtracted during inference to facilitate improved integration with external language models. Recently, various of factorized transducer models have been proposed, which explicitly embrace a standalone internal language model for non-blank token prediction. However, even with the adoption of factorized transducer models, limited improvement has been observed compared to shallow fusion. In this paper, we propose a novel ILM training and decoding strategy for factorized transducer models, which effectively combines the blank, acoustic and ILM scores. Our experiments show a 17% relative improvement over the standard decoding method when utilizing a well-trained ILM and the proposed decoding strategy on LibriSpeech datasets. Furthermore, when compared to a strong RNN-T baseline enhanced with external LM fusion, the proposed model yields a 5.5% relative improvement on general-sets and an 8.9% WER reduction for rare words. The proposed model can achieve superior performance without relying on external language models, rendering it highly efficient for production use-cases. To further improve the performance, we propose a novel and memory-efficient ILM-fusion-aware minimum word error rate (MWER) training method which improves ILM integration significantly.
Towards General-Purpose Speech Abilities for Large Language Models Using Unpaired Data
Nov 12, 2023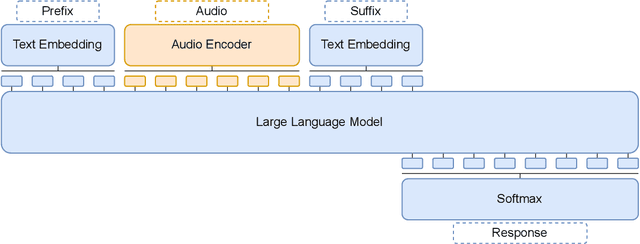

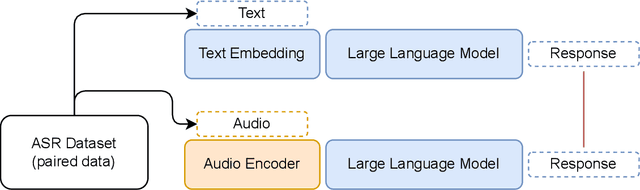
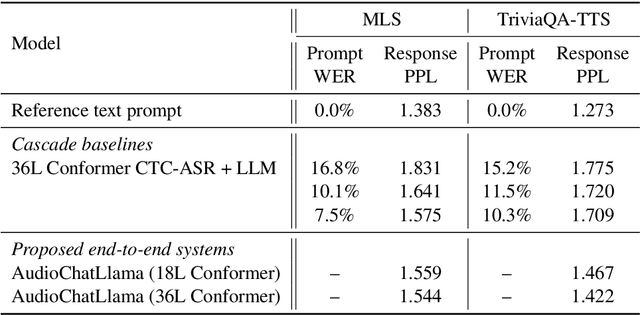
In this work, we extend the instruction-tuned Llama-2 model with end-to-end general-purpose speech processing and reasoning abilities while maintaining the wide range of LLM capabilities, without using any carefully curated paired data. The proposed model can utilize audio prompts as a replacement for text and sustain a conversation. Such a model also has extended cross-modal capabilities such as being able to perform speech question answering, speech translation, and audio summarization amongst many other closed and open-domain tasks. This is unlike prior approaches in speech, in which LLMs are extended to handle audio for a limited number of pre-designated tasks. Experiments show that our end-to-end approach is on par with or outperforms a cascaded system (speech recognizer + LLM) in terms of modeling the response to a prompt. Furthermore, unlike a cascade, our approach shows the ability to interchange text and audio modalities and utilize the prior context in a conversation to provide better results.
TODM: Train Once Deploy Many Efficient Supernet-Based RNN-T Compression For On-device ASR Models
Sep 05, 2023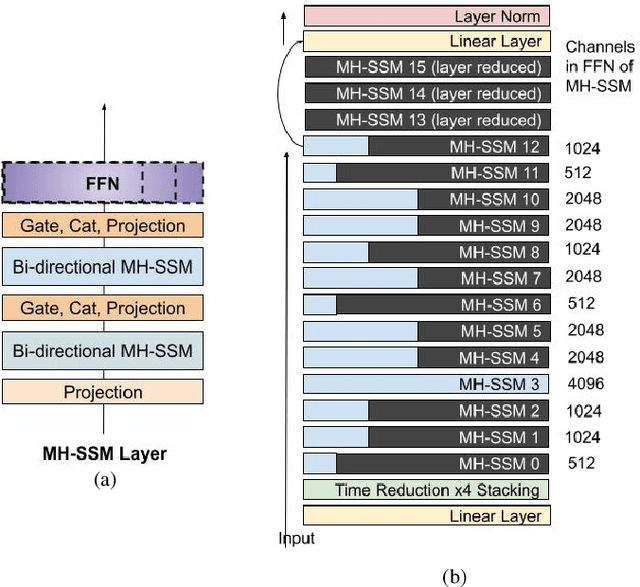
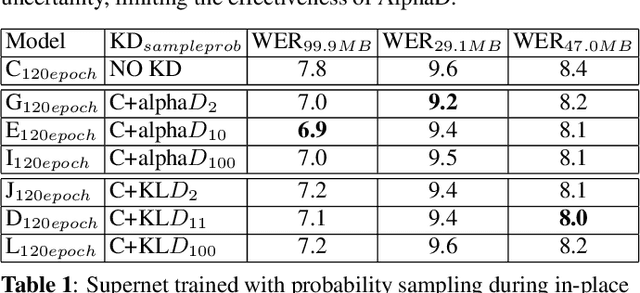
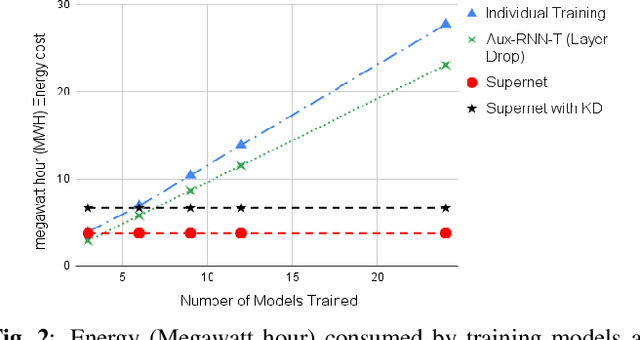
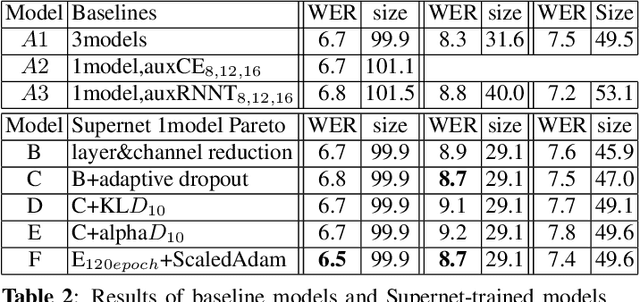
Automatic Speech Recognition (ASR) models need to be optimized for specific hardware before they can be deployed on devices. This can be done by tuning the model's hyperparameters or exploring variations in its architecture. Re-training and re-validating models after making these changes can be a resource-intensive task. This paper presents TODM (Train Once Deploy Many), a new approach to efficiently train many sizes of hardware-friendly on-device ASR models with comparable GPU-hours to that of a single training job. TODM leverages insights from prior work on Supernet, where Recurrent Neural Network Transducer (RNN-T) models share weights within a Supernet. It reduces layer sizes and widths of the Supernet to obtain subnetworks, making them smaller models suitable for all hardware types. We introduce a novel combination of three techniques to improve the outcomes of the TODM Supernet: adaptive dropouts, an in-place Alpha-divergence knowledge distillation, and the use of ScaledAdam optimizer. We validate our approach by comparing Supernet-trained versus individually tuned Multi-Head State Space Model (MH-SSM) RNN-T using LibriSpeech. Results demonstrate that our TODM Supernet either matches or surpasses the performance of manually tuned models by up to a relative of 3% better in word error rate (WER), while efficiently keeping the cost of training many models at a small constant.
Prompting Large Language Models with Speech Recognition Abilities
Jul 21, 2023
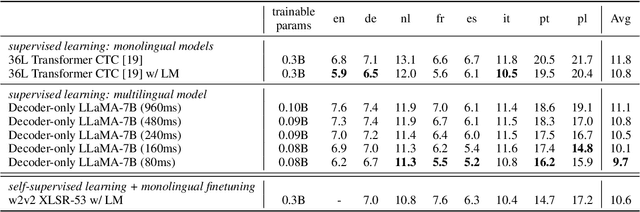
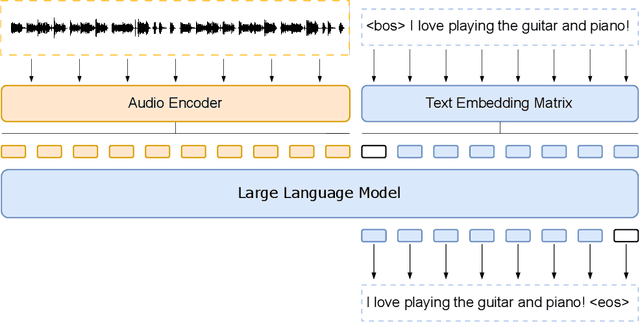

Large language models have proven themselves highly flexible, able to solve a wide range of generative tasks, such as abstractive summarization and open-ended question answering. In this paper we extend the capabilities of LLMs by directly attaching a small audio encoder allowing it to perform speech recognition. By directly prepending a sequence of audial embeddings to the text token embeddings, the LLM can be converted to an automatic speech recognition (ASR) system, and be used in the exact same manner as its textual counterpart. Experiments on Multilingual LibriSpeech (MLS) show that incorporating a conformer encoder into the open sourced LLaMA-7B allows it to outperform monolingual baselines by 18% and perform multilingual speech recognition despite LLaMA being trained overwhelmingly on English text. Furthermore, we perform ablation studies to investigate whether the LLM can be completely frozen during training to maintain its original capabilities, scaling up the audio encoder, and increasing the audio encoder striding to generate fewer embeddings. The results from these studies show that multilingual ASR is possible even when the LLM is frozen or when strides of almost 1 second are used in the audio encoder opening up the possibility for LLMs to operate on long-form audio.
Multi-Head State Space Model for Speech Recognition
May 25, 2023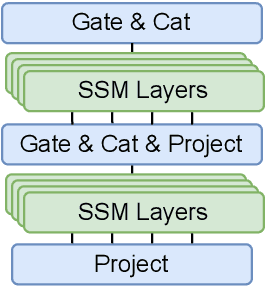
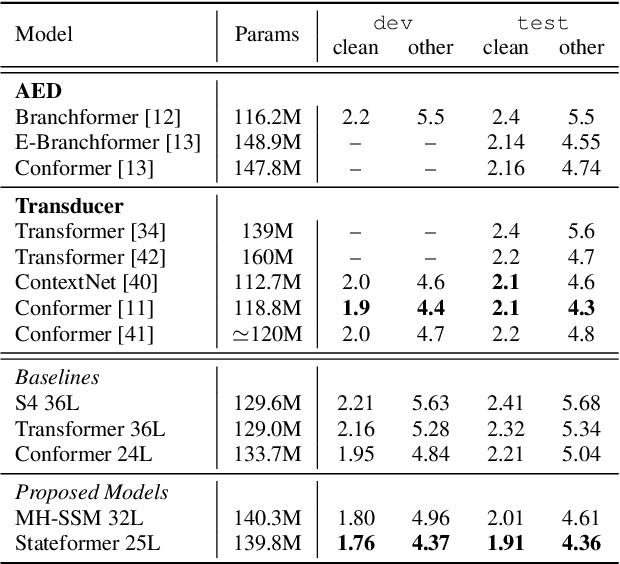
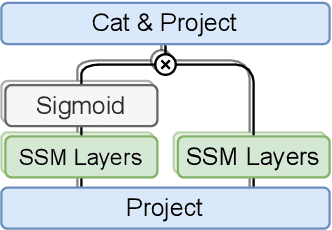
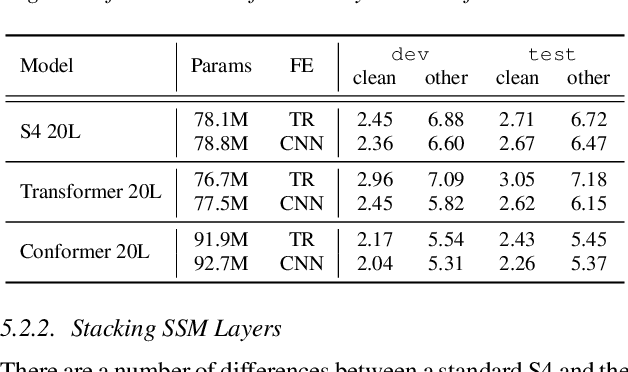
State space models (SSMs) have recently shown promising results on small-scale sequence and language modelling tasks, rivalling and outperforming many attention-based approaches. In this paper, we propose a multi-head state space (MH-SSM) architecture equipped with special gating mechanisms, where parallel heads are taught to learn local and global temporal dynamics on sequence data. As a drop-in replacement for multi-head attention in transformer encoders, this new model significantly outperforms the transformer transducer on the LibriSpeech speech recognition corpus. Furthermore, we augment the transformer block with MH-SSMs layers, referred to as the Stateformer, achieving state-of-the-art performance on the LibriSpeech task, with word error rates of 1.76\%/4.37\% on the development and 1.91\%/4.36\% on the test sets without using an external language model.
Dynamic Speech Endpoint Detection with Regression Targets
Oct 25, 2022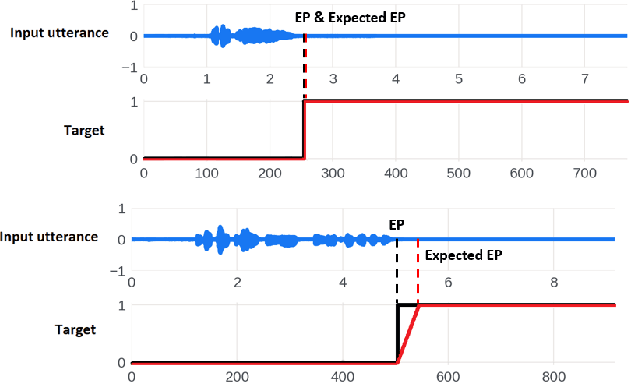

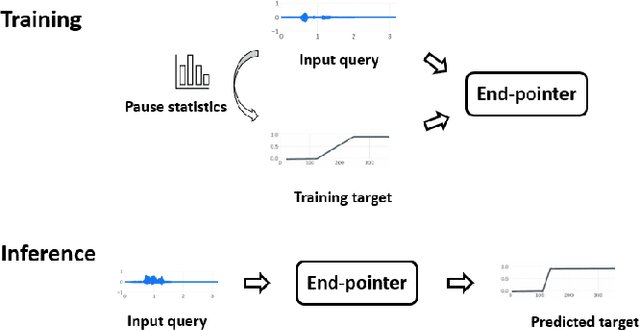

Interactive voice assistants have been widely used as input interfaces in various scenarios, e.g. on smart homes devices, wearables and on AR devices. Detecting the end of a speech query, i.e. speech end-pointing, is an important task for voice assistants to interact with users. Traditionally, speech end-pointing is based on pure classification methods along with arbitrary binary targets. In this paper, we propose a novel regression-based speech end-pointing model, which enables an end-pointer to adjust its detection behavior based on context of user queries. Specifically, we present a pause modeling method and show its effectiveness for dynamic end-pointing. Based on our experiments with vendor-collected smartphone and wearables speech queries, our strategy shows a better trade-off between endpointing latency and accuracy, compared to the traditional classification-based method. We further discuss the benefits of this model and generalization of the framework in the paper.