 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting In-Person Conversations in Noisy Real-World Environments with Smartwatch Audio and Motion Sensing
Jul 16, 2025



Social interactions play a crucial role in shaping human behavior, relationships, and societies. It encompasses various forms of communication, such as verbal conversation, non-verbal gestures, facial expressions, and body language. In this work, we develop a novel computational approach to detect a foundational aspect of human social interactions, in-person verbal conversations, by leveraging audio and inertial data captured with a commodity smartwatch in acoustically-challenging scenarios. To evaluate our approach, we conducted a lab study with 11 participants and a semi-naturalistic study with 24 participants. We analyzed machine learning and deep learning models with 3 different fusion methods, showing the advantages of fusing audio and inertial data to consider not only verbal cues but also non-verbal gestures in conversations. Furthermore, we perform a comprehensive set of evaluations across activities and sampling rates to demonstrate the benefits of multimodal sensing in specific contexts. Overall, our framework achieved 82.0$\pm$3.0% macro F1-score when detecting conversations in the lab and 77.2$\pm$1.8% in the semi-naturalistic setting.
Transformation of audio embeddings into interpretable, concept-based representations
Apr 18, 2025Advancements in audio neural networks have established state-of-the-art results on downstream audio tasks. However, the black-box structure of these models makes it difficult to interpret the information encoded in their internal audio representations. In this work, we explore the semantic interpretability of audio embeddings extracted from these neural networks by leveraging CLAP, a contrastive learning model that brings audio and text into a shared embedding space. We implement a post-hoc method to transform CLAP embeddings into concept-based, sparse representations with semantic interpretability. Qualitative and quantitative evaluations show that the concept-based representations outperform or match the performance of original audio embeddings on downstream tasks while providing interpretability. Additionally, we demonstrate that fine-tuning the concept-based representations can further improve their performance on downstream tasks. Lastly, we publish three audio-specific vocabularies for concept-based interpretability of audio embeddings.
Development and Evaluation of Three Chatbots for Postpartum Mood and Anxiety Disorders
Aug 14, 2023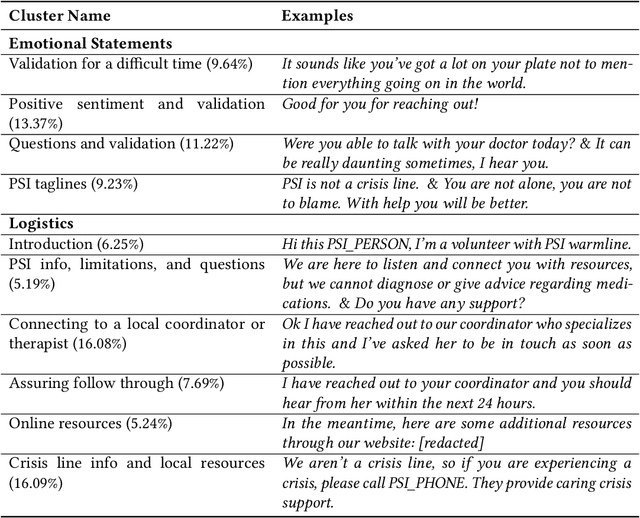
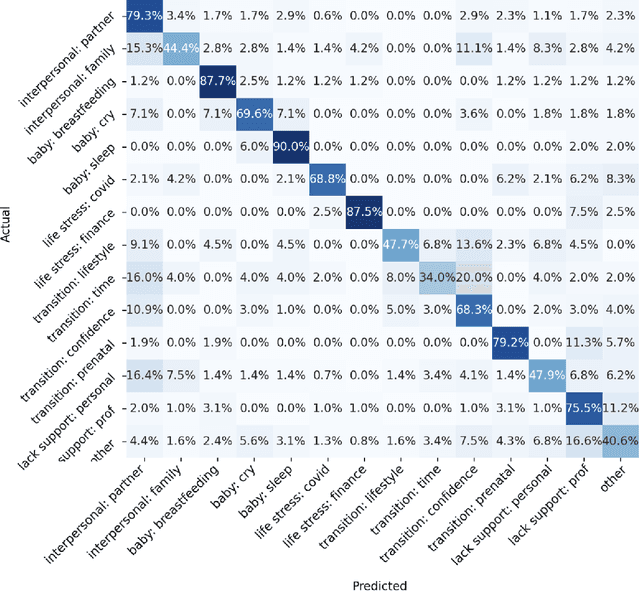
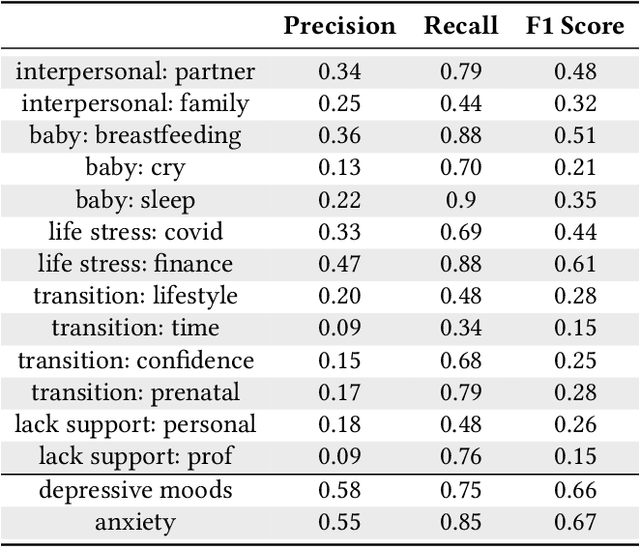
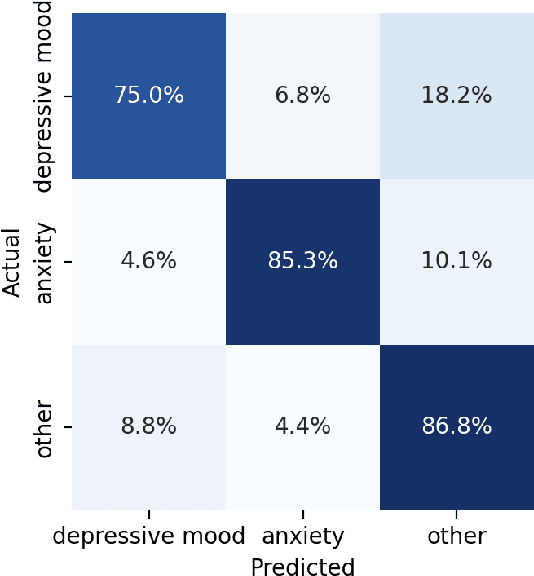
In collaboration with Postpartum Support International (PSI), a non-profit organization dedicated to supporting caregivers with postpartum mood and anxiety disorders, we developed three chatbots to provide context-specific empathetic support to postpartum caregivers, leveraging both rule-based and generative models. We present and evaluate the performance of our chatbots using both machine-based metrics and human-based questionnaires. Overall, our rule-based model achieves the best performance, with outputs that are close to ground truth reference and contain the highest levels of empathy. Human users prefer the rule-based chatbot over the generative chatbot for its context-specific and human-like replies. Our generative chatbot also produced empathetic responses and was described by human users as engaging. However, limitations in the training dataset often result in confusing or nonsensical responses. We conclude by discussing practical benefits of rule-based vs. generative models for supporting individuals with mental health challenges. In light of the recent surge of ChatGPT and BARD, we also discuss the possibilities and pitfalls of large language models for digital mental healthcare.
Cheating off your neighbors: Improving activity recognition through corroboration
May 27, 2023Understanding the complexity of human activities solely through an individual's data can be challenging. However, in many situations, surrounding individuals are likely performing similar activities, while existing human activity recognition approaches focus almost exclusively on individual measurements and largely ignore the context of the activity. Consider two activities: attending a small group meeting and working at an office desk. From solely an individual's perspective, it can be difficult to differentiate between these activities as they may appear very similar, even though they are markedly different. Yet, by observing others nearby, it can be possible to distinguish between these activities. In this paper, we propose an approach to enhance the prediction accuracy of an individual's activities by incorporating insights from surrounding individuals. We have collected a real-world dataset from 20 participants with over 58 hours of data including activities such as attending lectures, having meetings, working in the office, and eating together. Compared to observing a single person in isolation, our proposed approach significantly improves accuracy. We regard this work as a first step in collaborative activity recognition, opening new possibilities for understanding human activity in group settings.
Understanding Postpartum Parents' Experiences via Two Digital Platforms
Dec 22, 2022
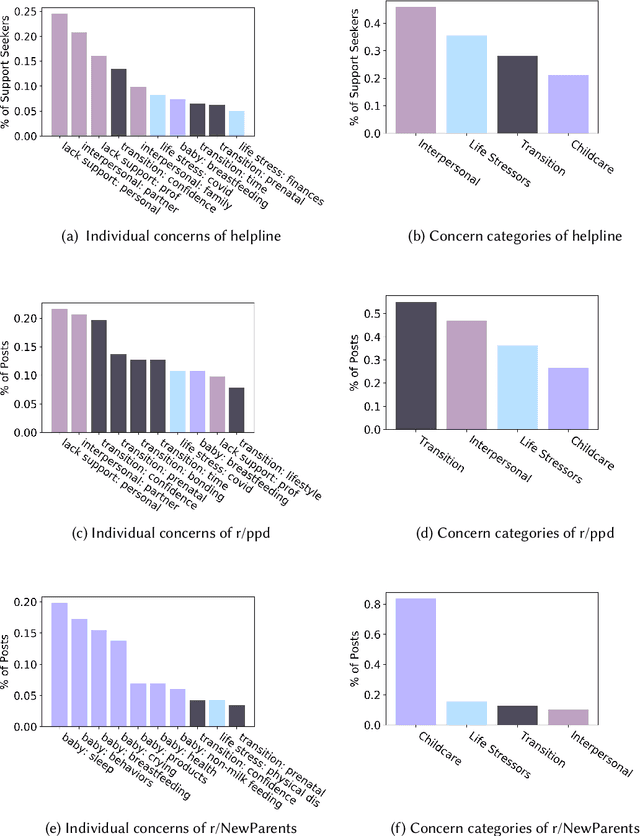
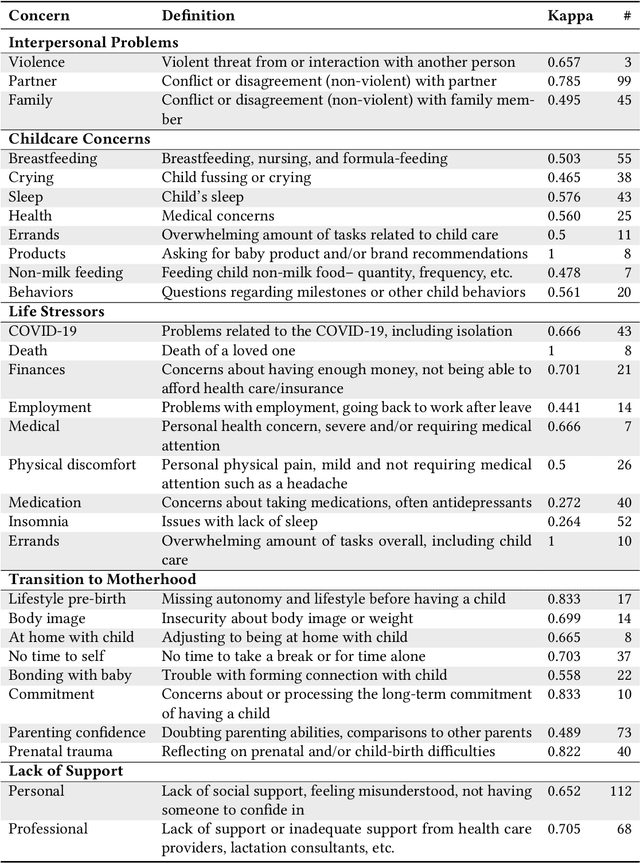

Digital platforms, including online forums and helplines, have emerged as avenues of support for caregivers suffering from postpartum mental health distress. Understanding support seekers' experiences as shared on these platforms could provide crucial insight into caregivers' needs during this vulnerable time. In the current work, we provide a descriptive analysis of the concerns, psychological states, and motivations shared by healthy and distressed postpartum support seekers on two digital platforms, a one-on-one digital helpline and a publicly available online forum. Using a combination of human annotations, dictionary models and unsupervised techniques, we find stark differences between the experiences of distressed and healthy mothers. Distressed mothers described interpersonal problems and a lack of support, with 8.60% - 14.56% reporting severe symptoms including suicidal ideation. In contrast, the majority of healthy mothers described childcare issues, such as questions about breastfeeding or sleeping, and reported no severe mental health concerns. Across the two digital platforms, we found that distressed mothers shared similar content. However, the patterns of speech and affect shared by distressed mothers differed between the helpline vs. the online forum, suggesting the design of these platforms may shape meaningful measures of their support-seeking experiences. Our results provide new insight into the experiences of caregivers suffering from postpartum mental health distress. We conclude by discussing methodological considerations for understanding content shared by support seekers and design considerations for the next generation of support tools for postpartum parents.
Dynamic Speech Endpoint Detection with Regression Targets
Oct 25, 2022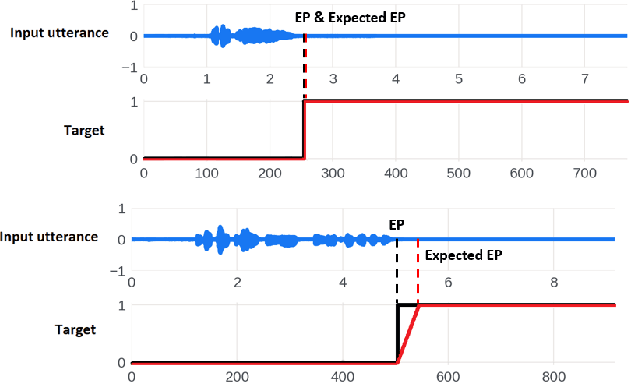

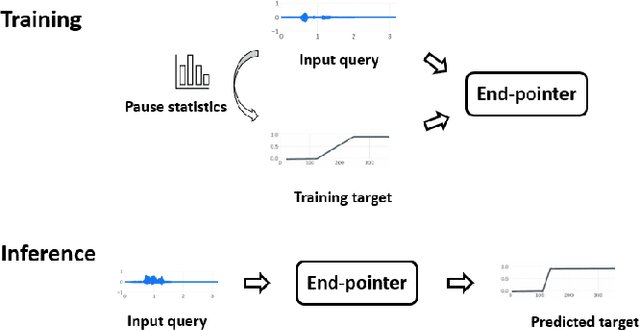

Interactive voice assistants have been widely used as input interfaces in various scenarios, e.g. on smart homes devices, wearables and on AR devices. Detecting the end of a speech query, i.e. speech end-pointing, is an important task for voice assistants to interact with users. Traditionally, speech end-pointing is based on pure classification methods along with arbitrary binary targets. In this paper, we propose a novel regression-based speech end-pointing model, which enables an end-pointer to adjust its detection behavior based on context of user queries. Specifically, we present a pause modeling method and show its effectiveness for dynamic end-pointing. Based on our experiments with vendor-collected smartphone and wearables speech queries, our strategy shows a better trade-off between endpointing latency and accuracy, compared to the traditional classification-based method. We further discuss the benefits of this model and generalization of the framework in the paper.
Lifelong Adaptive Machine Learning for Sensor-based Human Activity Recognition Using Prototypical Networks
Mar 11, 2022
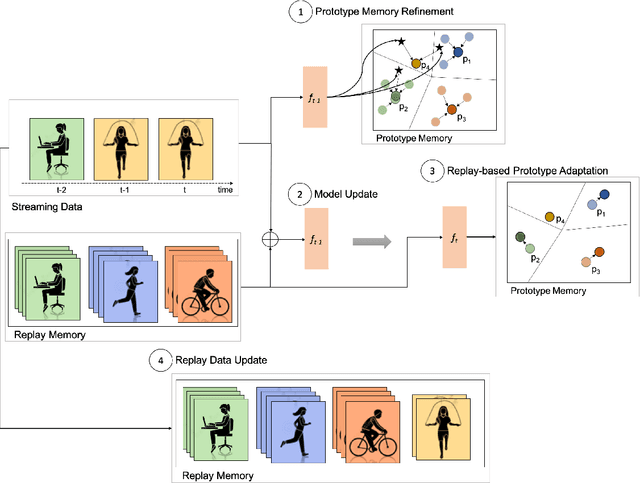
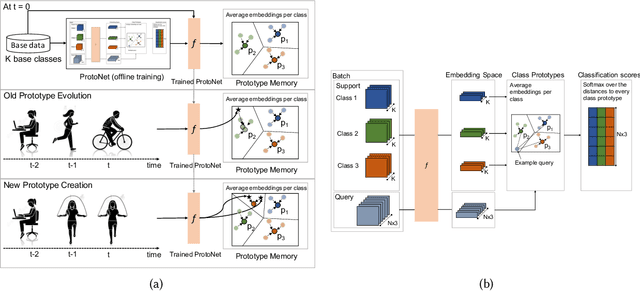

Continual learning, also known as lifelong learning, is an emerging research topic that has been attracting increasing interest in the field of machine learning. With human activity recognition (HAR) playing a key role in enabling numerous real-world applications, an essential step towards the long-term deployment of such recognition systems is to extend the activity model to dynamically adapt to changes in people's everyday behavior. Current research in continual learning applied to HAR domain is still under-explored with researchers exploring existing methods developed for computer vision in HAR. Moreover, analysis has so far focused on task-incremental or class-incremental learning paradigms where task boundaries are known. This impedes the applicability of such methods for real-world systems since data is presented in a randomly streaming fashion. To push this field forward, we build on recent advances in the area of continual machine learning and design a lifelong adaptive learning framework using Prototypical Networks, LAPNet-HAR, that processes sensor-based data streams in a task-free data-incremental fashion and mitigates catastrophic forgetting using experience replay and continual prototype adaptation. Online learning is further facilitated using contrastive loss to enforce inter-class separation. LAPNet-HAR is evaluated on 5 publicly available activity datasets in terms of the framework's ability to acquire new information while preserving previous knowledge. Our extensive empirical results demonstrate the effectiveness of LAPNet-HAR in task-free continual learning and uncover useful insights for future challenges.
HAR-GCNN: Deep Graph CNNs for Human Activity Recognition From Highly Unlabeled Mobile Sensor Data
Mar 07, 2022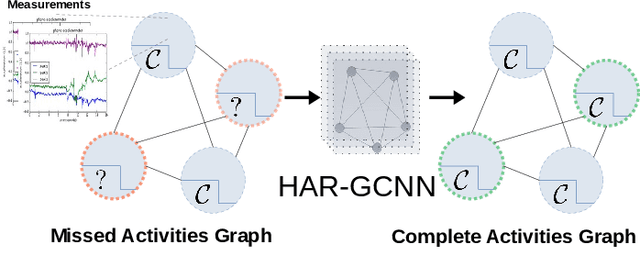
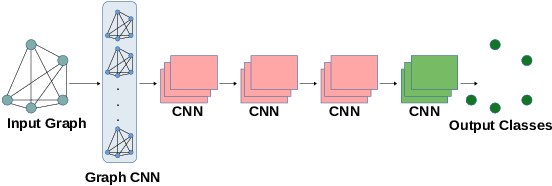
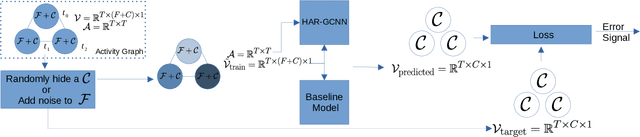
The problem of human activity recognition from mobile sensor data applies to multiple domains, such as health monitoring, personal fitness, daily life logging, and senior care. A critical challenge for training human activity recognition models is data quality. Acquiring balanced datasets containing accurate activity labels requires humans to correctly annotate and potentially interfere with the subjects' normal activities in real-time. Despite the likelihood of incorrect annotation or lack thereof, there is often an inherent chronology to human behavior. For example, we take a shower after we exercise. This implicit chronology can be used to learn unknown labels and classify future activities. In this work, we propose HAR-GCCN, a deep graph CNN model that leverages the correlation between chronologically adjacent sensor measurements to predict the correct labels for unclassified activities that have at least one activity label. We propose a new training strategy enforcing that the model predicts the missing activity labels by leveraging the known ones. HAR-GCCN shows superior performance relative to previously used baseline methods, improving classification accuracy by about 25% and up to 68% on different datasets. Code is available at \url{https://github.com/abduallahmohamed/HAR-GCNN}.
Transferring Voice Knowledge for Acoustic Event Detection: An Empirical Study
Oct 07, 2021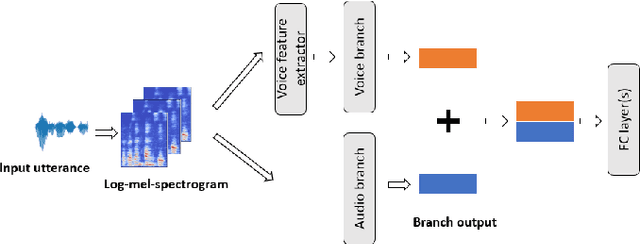
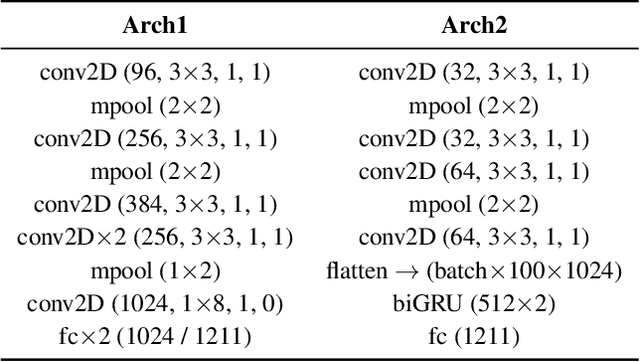
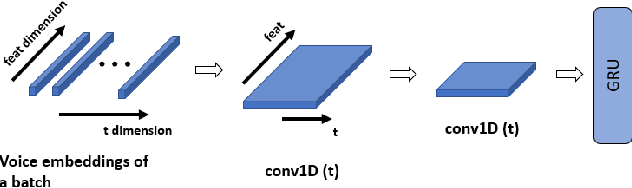
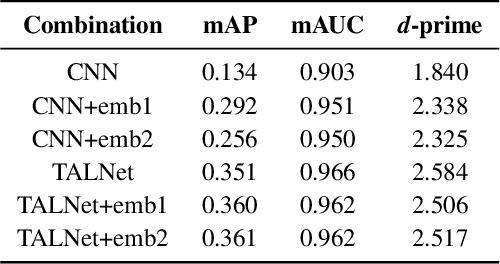
Detection of common events and scenes from audio is useful for extracting and understanding human contexts in daily life. Prior studies have shown that leveraging knowledge from a relevant domain is beneficial for a target acoustic event detection (AED) process. Inspired by the observation that many human-centered acoustic events in daily life involve voice elements, this paper investigates the potential of transferring high-level voice representations extracted from a public speaker dataset to enrich an AED pipeline. Towards this end, we develop a dual-branch neural network architecture for the joint learning of voice and acoustic features during an AED process and conduct thorough empirical studies to examine the performance on the public AudioSet [1] with different types of inputs. Our main observations are that: 1) Joint learning of audio and voice inputs improves the AED performance (mean average precision) for both a CNN baseline (0.292 vs 0.134 mAP) and a TALNet [2] baseline (0.361 vs 0.351 mAP); 2) Augmenting the extra voice features is critical to maximize the model performance with dual inputs.
Quantifying the Chaos Level of Infants' Environment via Unsupervised Learning
Dec 10, 2019


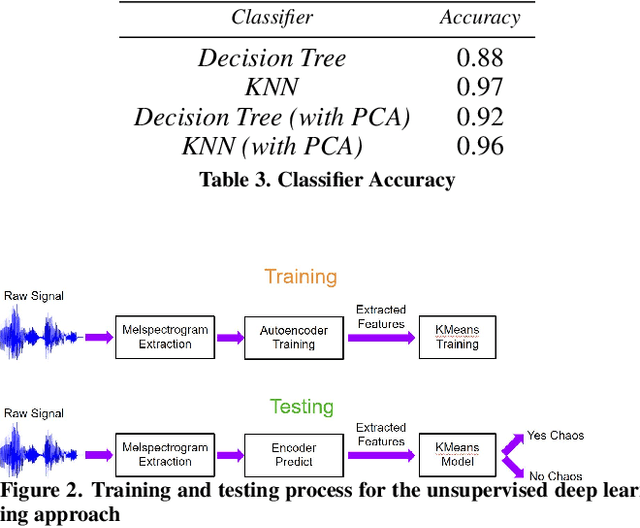
Acoustic environments vary dramatically within the home setting. They can be a source of comfort and tranquility or chaos that can lead to less optimal cognitive development in children. Research to date has only subjectively measured household chaos. In this work, we use three unsupervised machine learning techniques to quantify household chaos in infants' homes. These unsupervised techniques include hierarchical clustering using K-Means, clustering using self-organizing map (SOM) and deep learning. We evaluated these techniques using data from 9 participants which is a total of 197 hours. Results show that these techniques are promising to quantify household chaos.