 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Causal Framework to Evaluate Racial Bias in Law Enforcement Systems
Feb 22, 2024We are interested in developing a data-driven method to evaluate race-induced biases in law enforcement systems. While the recent works have addressed this question in the context of police-civilian interactions using police stop data, they have two key limitations. First, bias can only be properly quantified if true criminality is accounted for in addition to race, but it is absent in prior works. Second, law enforcement systems are multi-stage and hence it is important to isolate the true source of bias within the "causal chain of interactions" rather than simply focusing on the end outcome; this can help guide reforms. In this work, we address these challenges by presenting a multi-stage causal framework incorporating criminality. We provide a theoretical characterization and an associated data-driven method to evaluate (a) the presence of any form of racial bias, and (b) if so, the primary source of such a bias in terms of race and criminality. Our framework identifies three canonical scenarios with distinct characteristics: in settings like (1) airport security, the primary source of observed bias against a race is likely to be bias in law enforcement against innocents of that race; (2) AI-empowered policing, the primary source of observed bias against a race is likely to be bias in law enforcement against criminals of that race; and (3) police-civilian interaction, the primary source of observed bias against a race could be bias in law enforcement against that race or bias from the general public in reporting against the other race. Through an extensive empirical study using police-civilian interaction data and 911 call data, we find an instance of such a counter-intuitive phenomenon: in New Orleans, the observed bias is against the majority race and the likely reason for it is the over-reporting (via 911 calls) of incidents involving the minority race by the general public.
Development and Evaluation of Three Chatbots for Postpartum Mood and Anxiety Disorders
Aug 14, 2023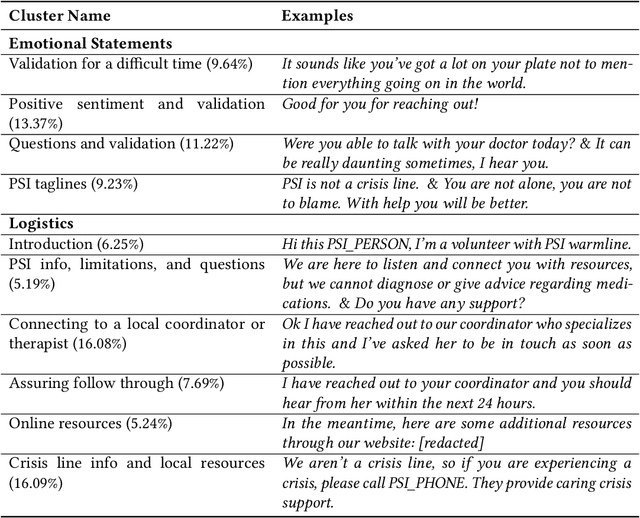
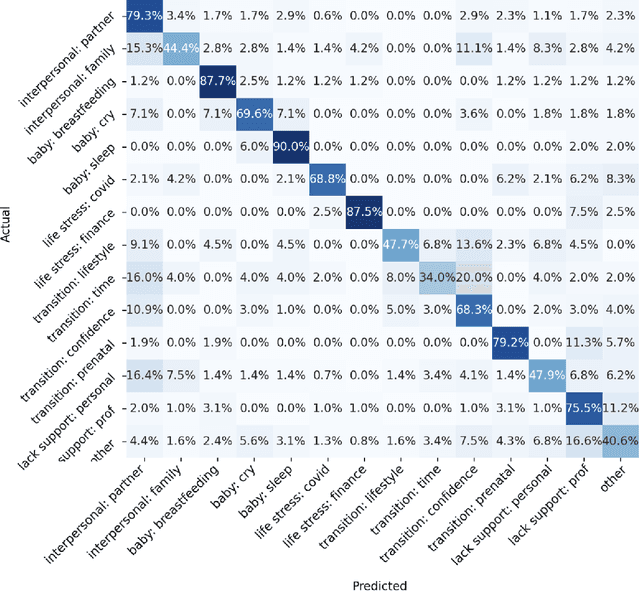
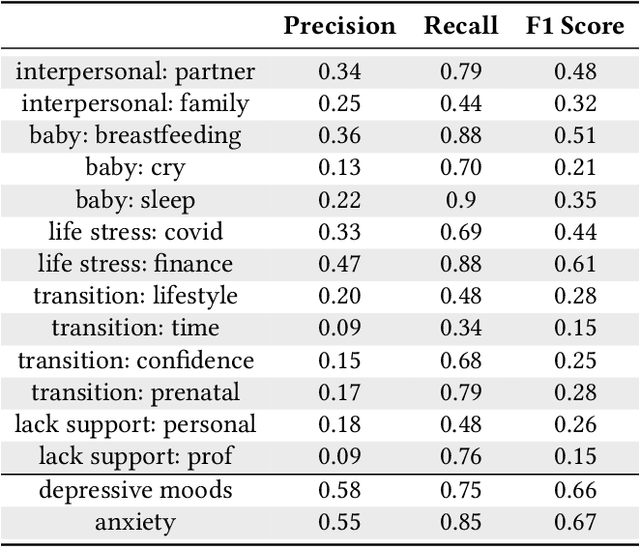
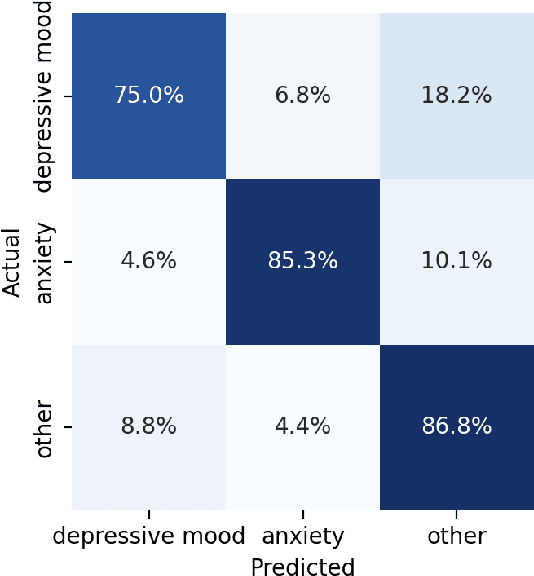
In collaboration with Postpartum Support International (PSI), a non-profit organization dedicated to supporting caregivers with postpartum mood and anxiety disorders, we developed three chatbots to provide context-specific empathetic support to postpartum caregivers, leveraging both rule-based and generative models. We present and evaluate the performance of our chatbots using both machine-based metrics and human-based questionnaires. Overall, our rule-based model achieves the best performance, with outputs that are close to ground truth reference and contain the highest levels of empathy. Human users prefer the rule-based chatbot over the generative chatbot for its context-specific and human-like replies. Our generative chatbot also produced empathetic responses and was described by human users as engaging. However, limitations in the training dataset often result in confusing or nonsensical responses. We conclude by discussing practical benefits of rule-based vs. generative models for supporting individuals with mental health challenges. In light of the recent surge of ChatGPT and BARD, we also discuss the possibilities and pitfalls of large language models for digital mental healthcare.