 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferring Voice Knowledge for Acoustic Event Detection: An Empirical Study
Paper and Code
Oct 07, 2021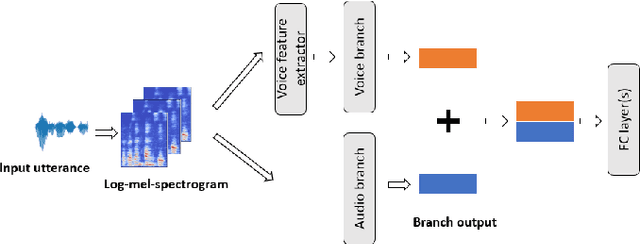
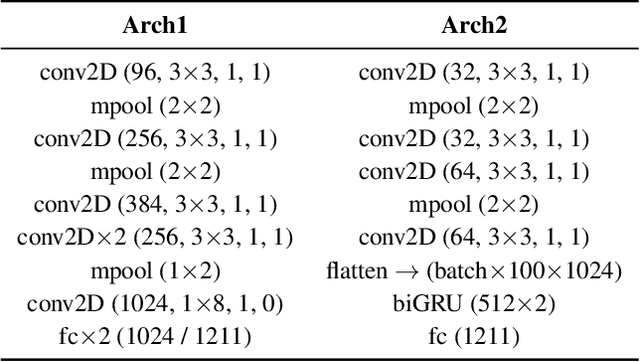
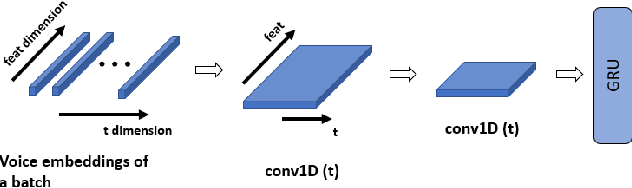
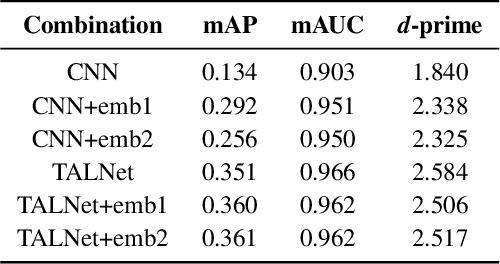
Detection of common events and scenes from audio is useful for extracting and understanding human contexts in daily life. Prior studies have shown that leveraging knowledge from a relevant domain is beneficial for a target acoustic event detection (AED) process. Inspired by the observation that many human-centered acoustic events in daily life involve voice elements, this paper investigates the potential of transferring high-level voice representations extracted from a public speaker dataset to enrich an AED pipeline. Towards this end, we develop a dual-branch neural network architecture for the joint learning of voice and acoustic features during an AED process and conduct thorough empirical studies to examine the performance on the public AudioSet [1] with different types of inputs. Our main observations are that: 1) Joint learning of audio and voice inputs improves the AED performance (mean average precision) for both a CNN baseline (0.292 vs 0.134 mAP) and a TALNet [2] baseline (0.361 vs 0.351 mAP); 2) Augmenting the extra voice features is critical to maximize the model performance with dual inputs.