 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRzenEmbed: Towards Comprehensive Multimodal Retrieval
Oct 31, 2025The rapid advancement of Multimodal Large Language Models (MLLMs) has extended CLIP-based frameworks to produce powerful, universal embeddings for retrieval tasks. However, existing methods primarily focus on natural images, offering limited support for other crucial visual modalities such as videos and visual documents. To bridge this gap, we introduce RzenEmbed, a unified framework to learn embeddings across a diverse set of modalities, including text, images, videos, and visual documents. We employ a novel two-stage training strategy to learn discriminative representations. The first stage focuses on foundational text and multimodal retrieval. In the second stage, we introduce an improved InfoNCE loss, incorporating two key enhancements. Firstly, a hardness-weighted mechanism guides the model to prioritize challenging samples by assigning them higher weights within each batch. Secondly, we implement an approach to mitigate the impact of false negatives and alleviate data noise. This strategy not only enhances the model's discriminative power but also improves its instruction-following capabilities. We further boost performance with learnable temperature parameter and model souping. RzenEmbed sets a new state-of-the-art on the MMEB benchmark. It not only achieves the best overall score but also outperforms all prior work on the challenging video and visual document retrieval tasks. Our models are available in https://huggingface.co/qihoo360/RzenEmbed.
Detecting In-Person Conversations in Noisy Real-World Environments with Smartwatch Audio and Motion Sensing
Jul 16, 2025



Social interactions play a crucial role in shaping human behavior, relationships, and societies. It encompasses various forms of communication, such as verbal conversation, non-verbal gestures, facial expressions, and body language. In this work, we develop a novel computational approach to detect a foundational aspect of human social interactions, in-person verbal conversations, by leveraging audio and inertial data captured with a commodity smartwatch in acoustically-challenging scenarios. To evaluate our approach, we conducted a lab study with 11 participants and a semi-naturalistic study with 24 participants. We analyzed machine learning and deep learning models with 3 different fusion methods, showing the advantages of fusing audio and inertial data to consider not only verbal cues but also non-verbal gestures in conversations. Furthermore, we perform a comprehensive set of evaluations across activities and sampling rates to demonstrate the benefits of multimodal sensing in specific contexts. Overall, our framework achieved 82.0$\pm$3.0% macro F1-score when detecting conversations in the lab and 77.2$\pm$1.8% in the semi-naturalistic setting.
FG-CLIP: Fine-Grained Visual and Textual Alignment
May 08, 2025



Contrastive Language-Image Pre-training (CLIP) excels in multimodal tasks such as image-text retrieval and zero-shot classification but struggles with fine-grained understanding due to its focus on coarse-grained short captions. To address this, we propose Fine-Grained CLIP (FG-CLIP), which enhances fine-grained understanding through three key innovations. First, we leverage large multimodal models to generate 1.6 billion long caption-image pairs for capturing global-level semantic details. Second, a high-quality dataset is constructed with 12 million images and 40 million region-specific bounding boxes aligned with detailed captions to ensure precise, context-rich representations. Third, 10 million hard fine-grained negative samples are incorporated to improve the model's ability to distinguish subtle semantic differences. Corresponding training methods are meticulously designed for these data. Extensive experiments demonstrate that FG-CLIP outperforms the original CLIP and other state-of-the-art methods across various downstream tasks, including fine-grained understanding, open-vocabulary object detection, image-text retrieval, and general multimodal benchmarks. These results highlight FG-CLIP's effectiveness in capturing fine-grained image details and improving overall model performance. The related data, code, and models are available at https://github.com/360CVGroup/FG-CLIP.
Dynamic Speech Endpoint Detection with Regression Targets
Oct 25, 2022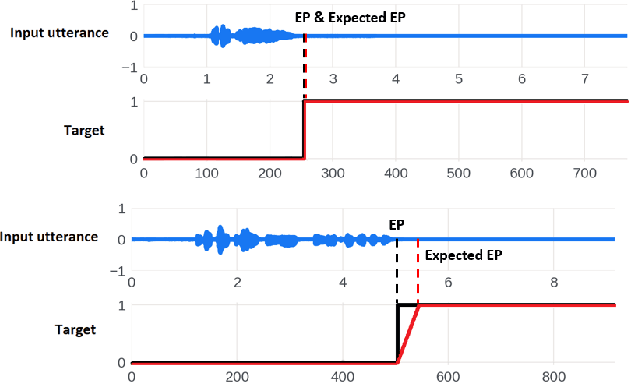

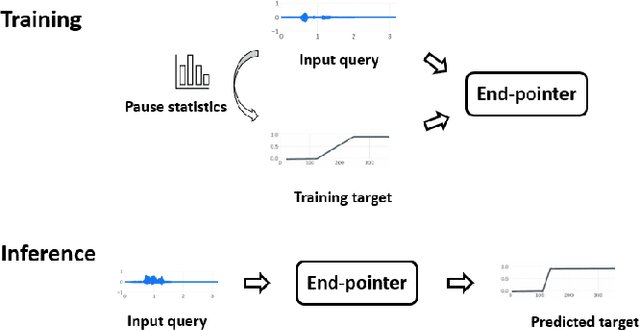

Interactive voice assistants have been widely used as input interfaces in various scenarios, e.g. on smart homes devices, wearables and on AR devices. Detecting the end of a speech query, i.e. speech end-pointing, is an important task for voice assistants to interact with users. Traditionally, speech end-pointing is based on pure classification methods along with arbitrary binary targets. In this paper, we propose a novel regression-based speech end-pointing model, which enables an end-pointer to adjust its detection behavior based on context of user queries. Specifically, we present a pause modeling method and show its effectiveness for dynamic end-pointing. Based on our experiments with vendor-collected smartphone and wearables speech queries, our strategy shows a better trade-off between endpointing latency and accuracy, compared to the traditional classification-based method. We further discuss the benefits of this model and generalization of the framework in the paper.
Transferring Voice Knowledge for Acoustic Event Detection: An Empirical Study
Oct 07, 2021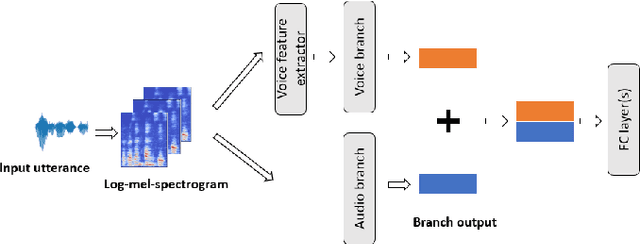
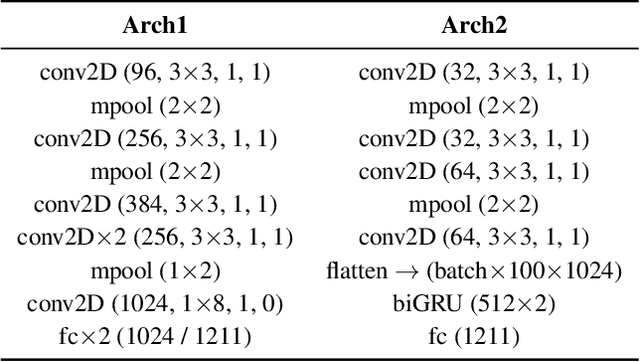
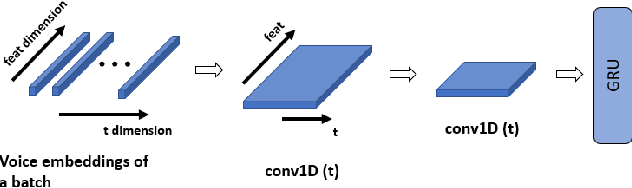
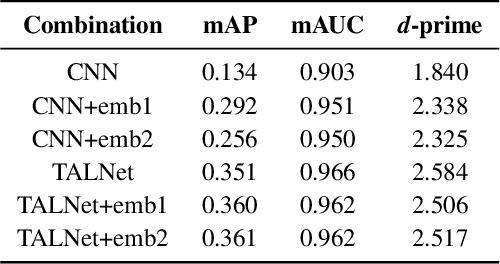
Detection of common events and scenes from audio is useful for extracting and understanding human contexts in daily life. Prior studies have shown that leveraging knowledge from a relevant domain is beneficial for a target acoustic event detection (AED) process. Inspired by the observation that many human-centered acoustic events in daily life involve voice elements, this paper investigates the potential of transferring high-level voice representations extracted from a public speaker dataset to enrich an AED pipeline. Towards this end, we develop a dual-branch neural network architecture for the joint learning of voice and acoustic features during an AED process and conduct thorough empirical studies to examine the performance on the public AudioSet [1] with different types of inputs. Our main observations are that: 1) Joint learning of audio and voice inputs improves the AED performance (mean average precision) for both a CNN baseline (0.292 vs 0.134 mAP) and a TALNet [2] baseline (0.361 vs 0.351 mAP); 2) Augmenting the extra voice features is critical to maximize the model performance with dual inputs.
Stochastic groundwater flow analysis in heterogeneous aquifer with modified neural architecture search (NAS) based physics-informed neural networks using transfer learning
Oct 03, 2020

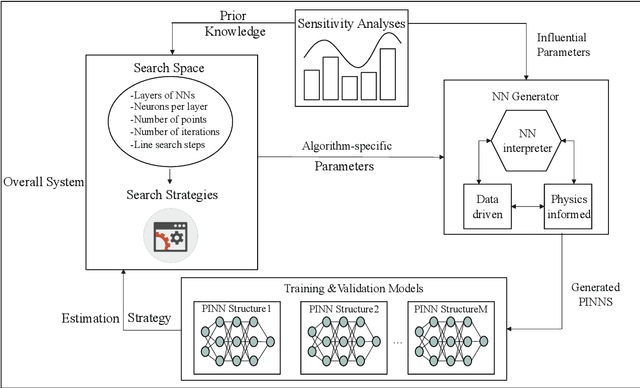
In this work, a modified neural architecture search method (NAS) based physics-informed deep learning model is presented to solve the groundwater flow problems in porous media. Monte Carlo method based on a randomized spectral representation is first employed to construct a stochastic model for simulation of flow through porous media. The desired hydraulic conductivity fields are assumed to be log-normally distributed with exponential and Gaussian correlations. To analyze the Darcy equation with the random hydraulic conductivity in this case when its intensity of fluctuations is small, the lowest-order perturbation theory is used to reduce the difficulty of calculations, by neglecting the higher-order nonlinear part. To solve the governing equations for groundwater flow problem, we build a modified NAS model based on physics-informed neural networks (PINNs) with transfer learning in this paper that will be able to fit different partial differential equations (PDEs) with less calculation. The performance estimation strategies adopted is constructed from an error estimation model using the method of manufactured solutions. Since the configuration selection of the neural network has a strong influence on the simulation results, we apply sensitivity analysis to obtain the prior knowledge of the PINNs model and narrow down the range of parameters for search space and use hyper-parameter optimization algorithms to further determine the values of the parameters. Further the NAS based PINNs model also saves the weights and biases of the most favorable architectures, which is then used in the fine-tuning process. The proposed NAS model based deep collocation method is verified to be effective and accurate through numerical examples in different dimensions using different manufactured solutions.
Cross-modal supervised learning for better acoustic representations
Jan 01, 2020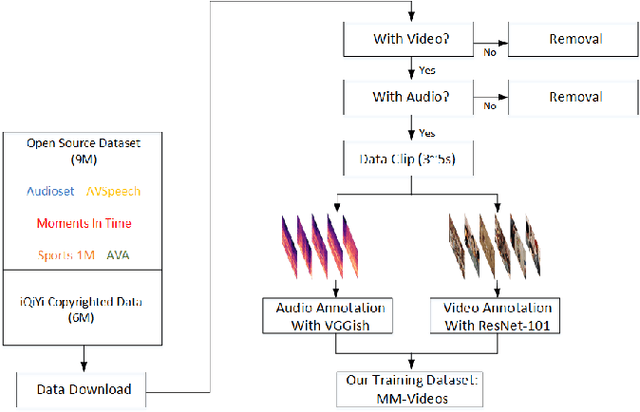
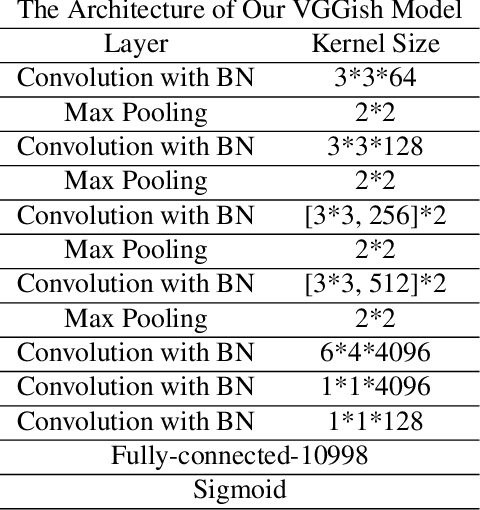
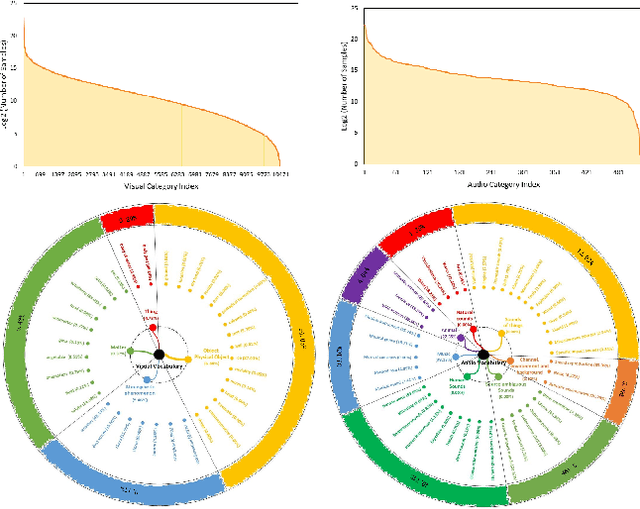
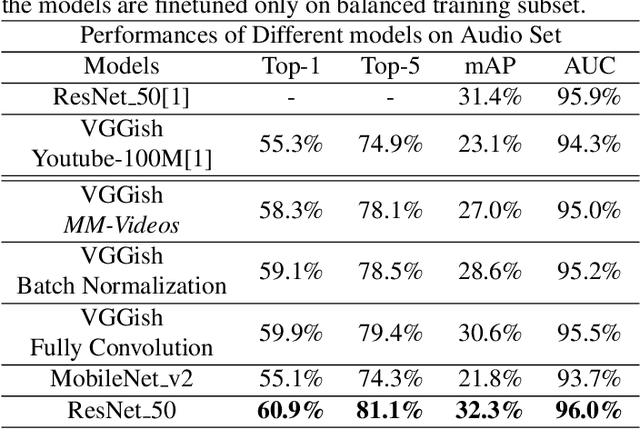
Obtaining large-scale human-labeled datasets to train acoustic representation models is a very challenging task. On the contrary, we can easily collect data with machine-generated labels. In this work, we propose to exploit machine-generated labels to learn better acoustic representations, based on the synchronization between vision and audio. Firstly, we collect a large-scale video dataset with 15 million samples, which totally last 16,320 hours. Each video is 3 to 5 seconds in length and annotated automatically by publicly available visual and audio classification models. Secondly, we train various classical convolutional neural networks (CNNs) including VGGish, ResNet 50 and Mobilenet v2. We also make several improvements to VGGish and achieve better results. Finally, we transfer our models on three external standard benchmarks for audio classification task, and achieve significant performance boost over the state-of-the-art results. Models and codes are available at: https://github.com/Deeperjia/vgg-like-audio-models.
AudioAR: Audio-Based Activity Recognition with Large-Scale Acoustic Embeddings from YouTube Videos
Oct 19, 2018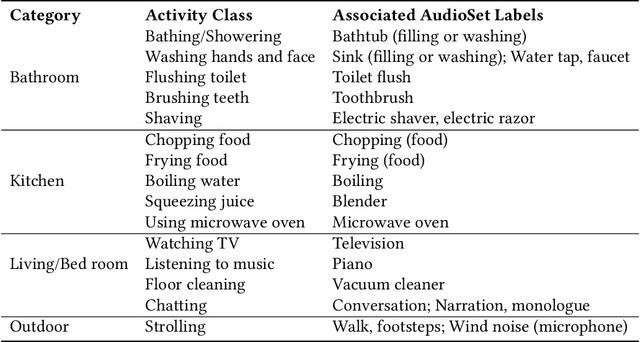
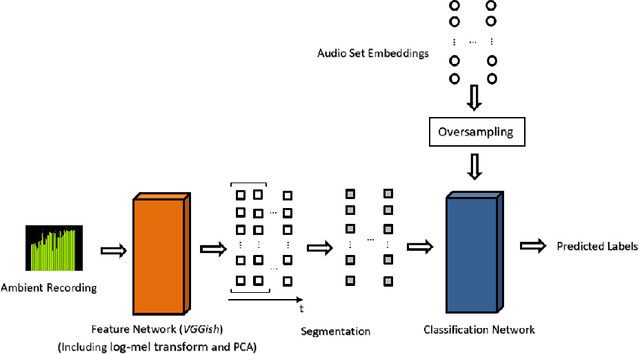


Activity sensing and recognition have been demonstrated to be critical in health care and smart home applications. Comparing to traditional methods such as using accelerometers or gyroscopes for activity recognition, acoustic-based methods can collect rich information of human activities together with the activity context, and therefore are more suitable for recognizing high-level compound activities. However, audio-based activity recognition in practice always suffers from the tedious and time-consuming process of collecting ground truth audio data from individual users. In this paper, we proposed a new mechanism of audio-based activity recognition that is entirely free from user training data by usage of millions of embedding features from general YouTube video sound clips. Based on combination of oversampling and deep learning approaches, our scheme does not require further feature extraction or outliers filtering for implementation. We developed our scheme for recognition of 15 common home-related activities and evaluated its performance under dedicated scenarios and in-the-wild scripted scenarios. In the dedicated recording test, our scheme yielded 81.1% overall accuracy and 80.0% overall F-score for all 15 activities. In the in-the-wild scripted tests, we obtained an averaged top-1 classification accuracy of 64.9% and an averaged top-3 classification accuracy of 80.6% for 4 subjects in actual home environment. Several design considerations including association between dataset labels and target activities, effects of segmentation size and privacy concerns were also discussed in the paper.