 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundary Content Graph Neural Network for Temporal Action Proposal Generation
Aug 04, 2020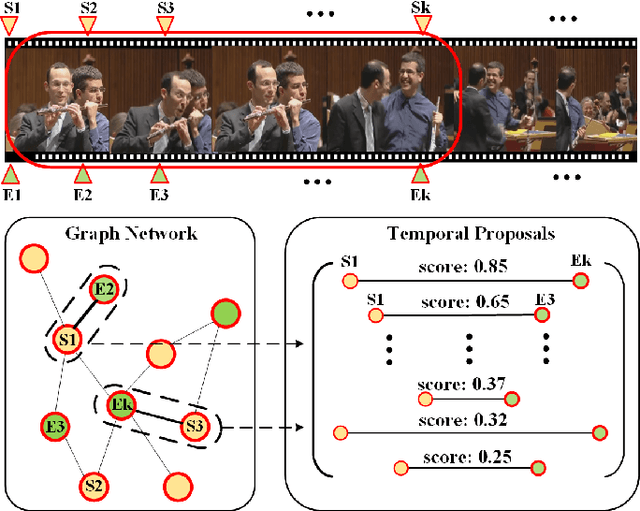

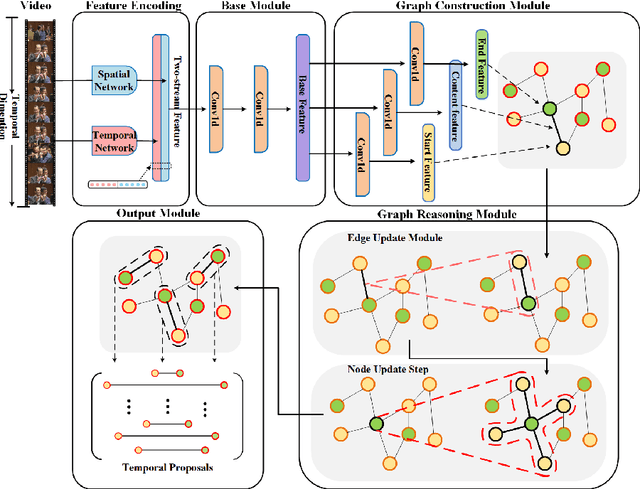
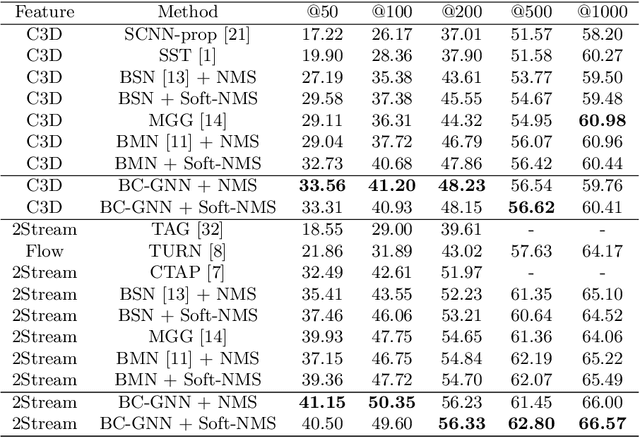
Temporal action proposal generation plays an important role in video action understanding, which requires localizing high-quality action content precisely. However, generating temporal proposals with both precise boundaries and high-quality action content is extremely challenging. To address this issue, we propose a novel Boundary Content Graph Neural Network (BC-GNN) to model the insightful relations between the boundary and action content of temporal proposals by the graph neural networks. In BC-GNN, the boundaries and content of temporal proposals are taken as the nodes and edges of the graph neural network, respectively, where they are spontaneously linked. Then a novel graph computation operation is proposed to update features of edges and nodes. After that, one updated edge and two nodes it connects are used to predict boundary probabilities and content confidence score, which will be combined to generate a final high-quality proposal. Experiments are conducted on two mainstream datasets: ActivityNet-1.3 and THUMOS14. Without the bells and whistles, BC-GNN outperforms previous state-of-the-art methods in both temporal action proposal and temporal action detection tasks.
Cross-modal supervised learning for better acoustic representations
Jan 01, 2020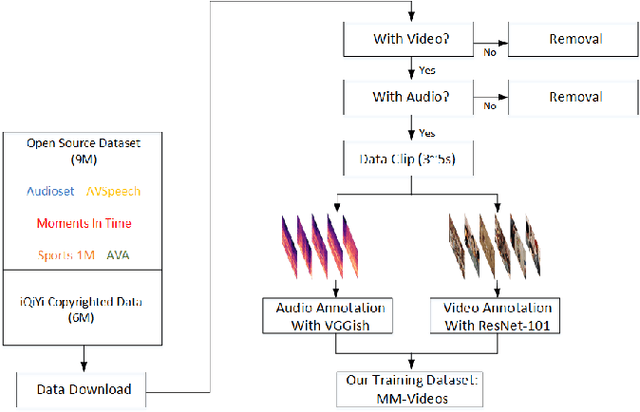
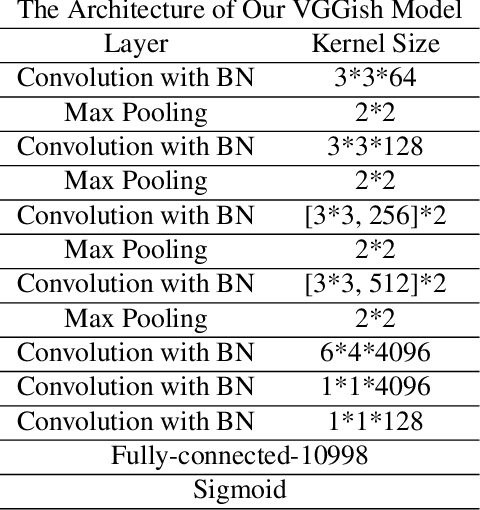
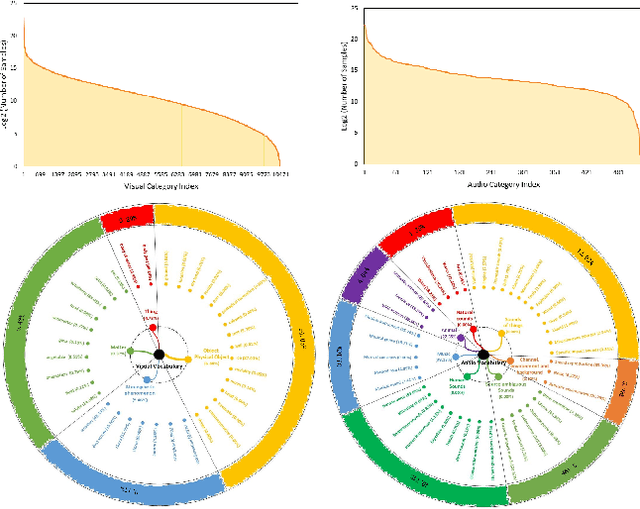
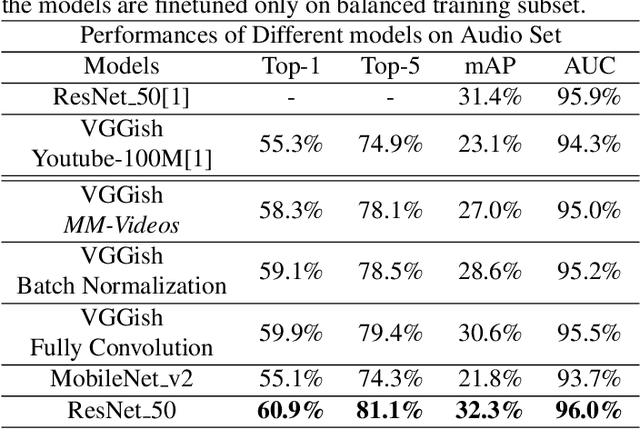
Obtaining large-scale human-labeled datasets to train acoustic representation models is a very challenging task. On the contrary, we can easily collect data with machine-generated labels. In this work, we propose to exploit machine-generated labels to learn better acoustic representations, based on the synchronization between vision and audio. Firstly, we collect a large-scale video dataset with 15 million samples, which totally last 16,320 hours. Each video is 3 to 5 seconds in length and annotated automatically by publicly available visual and audio classification models. Secondly, we train various classical convolutional neural networks (CNNs) including VGGish, ResNet 50 and Mobilenet v2. We also make several improvements to VGGish and achieve better results. Finally, we transfer our models on three external standard benchmarks for audio classification task, and achieve significant performance boost over the state-of-the-art results. Models and codes are available at: https://github.com/Deeperjia/vgg-like-audio-models.