 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSRM: Generative Speech Reward Model for Speech RLHF
Feb 14, 2026Recent advances in speech language models, such as GPT-4o Voice Mode and Gemini Live, have demonstrated promising speech generation capabilities. Nevertheless, the aesthetic naturalness of the synthesized audio still lags behind that of human speech. Enhancing generation quality requires a reliable evaluator of speech naturalness. However, existing naturalness evaluators typically regress raw audio to scalar scores, offering limited interpretability of the evaluation and moreover fail to generalize to speech across different taxonomies. Inspired by recent advances in generative reward modeling, we propose the Generative Speech Reward Model (GSRM), a reasoning-centric reward model tailored for speech. The GSRM is trained to decompose speech naturalness evaluation into an interpretable acoustic feature extraction stage followed by feature-grounded chain-of-thought reasoning, enabling explainable judgments. To achieve this, we curated a large-scale human feedback dataset comprising 31k expert ratings and an out-of-domain benchmark of real-world user-assistant speech interactions. Experiments show that GSRM substantially outperforms existing speech naturalness predictors, achieving model-human correlation of naturalness score prediction that approaches human inter-rater consistency. We further show how GSRM can improve the naturalness of speech LLM generations by serving as an effective verifier for online RLHF.
VowelPrompt: Hearing Speech Emotions from Text via Vowel-level Prosodic Augmentation
Feb 06, 2026Emotion recognition in speech presents a complex multimodal challenge, requiring comprehension of both linguistic content and vocal expressivity, particularly prosodic features such as fundamental frequency, intensity, and temporal dynamics. Although large language models (LLMs) have shown promise in reasoning over textual transcriptions for emotion recognition, they typically neglect fine-grained prosodic information, limiting their effectiveness and interpretability. In this work, we propose VowelPrompt, a linguistically grounded framework that augments LLM-based emotion recognition with interpretable, fine-grained vowel-level prosodic cues. Drawing on phonetic evidence that vowels serve as primary carriers of affective prosody, VowelPrompt extracts pitch-, energy-, and duration-based descriptors from time-aligned vowel segments, and converts these features into natural language descriptions for better interpretability. Such a design enables LLMs to jointly reason over lexical semantics and fine-grained prosodic variation. Moreover, we adopt a two-stage adaptation procedure comprising supervised fine-tuning (SFT) followed by Reinforcement Learning with Verifiable Reward (RLVR), implemented via Group Relative Policy Optimization (GRPO), to enhance reasoning capability, enforce structured output adherence, and improve generalization across domains and speaker variations. Extensive evaluations across diverse benchmark datasets demonstrate that VowelPrompt consistently outperforms state-of-the-art emotion recognition methods under zero-shot, fine-tuned, cross-domain, and cross-linguistic conditions, while enabling the generation of interpretable explanations that are jointly grounded in contextual semantics and fine-grained prosodic structure.
Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering
May 29, 2025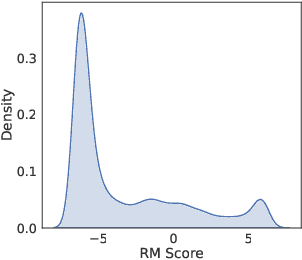
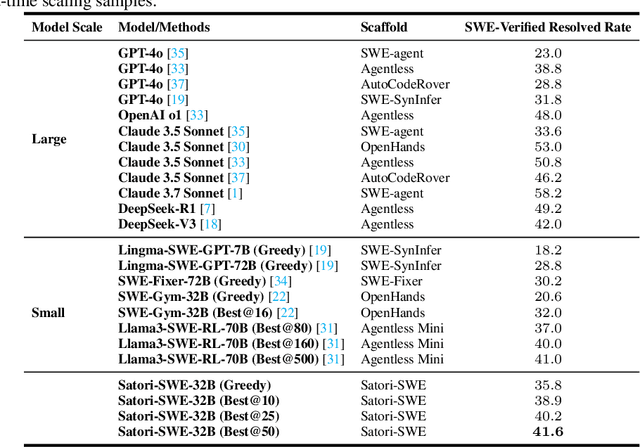
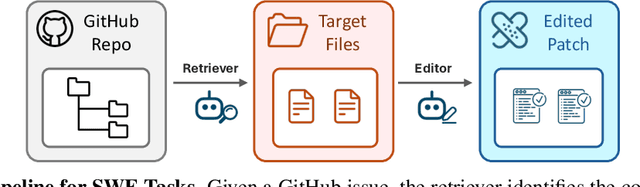

Language models (LMs) perform well on standardized coding benchmarks but struggle with real-world software engineering tasks such as resolving GitHub issues in SWE-Bench, especially when model parameters are less than 100B. While smaller models are preferable in practice due to their lower computational cost, improving their performance remains challenging. Existing approaches primarily rely on supervised fine-tuning (SFT) with high-quality data, which is expensive to curate at scale. An alternative is test-time scaling: generating multiple outputs, scoring them using a verifier, and selecting the best one. Although effective, this strategy often requires excessive sampling and costly scoring, limiting its practical application. We propose Evolutionary Test-Time Scaling (EvoScale), a sample-efficient method that treats generation as an evolutionary process. By iteratively refining outputs via selection and mutation, EvoScale shifts the output distribution toward higher-scoring regions, reducing the number of samples needed to find correct solutions. To reduce the overhead from repeatedly sampling and selection, we train the model to self-evolve using reinforcement learning (RL). Rather than relying on external verifiers at inference time, the model learns to self-improve the scores of its own generations across iterations. Evaluated on SWE-Bench-Verified, EvoScale enables our 32B model, Satori-SWE-32B, to match or exceed the performance of models with over 100B parameters while using a few samples. Code, data, and models will be fully open-sourced.
RL Tango: Reinforcing Generator and Verifier Together for Language Reasoning
May 21, 2025Reinforcement learning (RL) has recently emerged as a compelling approach for enhancing the reasoning capabilities of large language models (LLMs), where an LLM generator serves as a policy guided by a verifier (reward model). However, current RL post-training methods for LLMs typically use verifiers that are fixed (rule-based or frozen pretrained) or trained discriminatively via supervised fine-tuning (SFT). Such designs are susceptible to reward hacking and generalize poorly beyond their training distributions. To overcome these limitations, we propose Tango, a novel framework that uses RL to concurrently train both an LLM generator and a verifier in an interleaved manner. A central innovation of Tango is its generative, process-level LLM verifier, which is trained via RL and co-evolves with the generator. Importantly, the verifier is trained solely based on outcome-level verification correctness rewards without requiring explicit process-level annotations. This generative RL-trained verifier exhibits improved robustness and superior generalization compared to deterministic or SFT-trained verifiers, fostering effective mutual reinforcement with the generator. Extensive experiments demonstrate that both components of Tango achieve state-of-the-art results among 7B/8B-scale models: the generator attains best-in-class performance across five competition-level math benchmarks and four challenging out-of-domain reasoning tasks, while the verifier leads on the ProcessBench dataset. Remarkably, both components exhibit particularly substantial improvements on the most difficult mathematical reasoning problems. Code is at: https://github.com/kaiwenzha/rl-tango.
Satori: Reinforcement Learning with Chain-of-Action-Thought Enhances LLM Reasoning via Autoregressive Search
Feb 04, 2025



Large language models (LLMs) have demonstrated remarkable reasoning capabilities across diverse domains. Recent studies have shown that increasing test-time computation enhances LLMs' reasoning capabilities. This typically involves extensive sampling at inference time guided by an external LLM verifier, resulting in a two-player system. Despite external guidance, the effectiveness of this system demonstrates the potential of a single LLM to tackle complex tasks. Thus, we pose a new research problem: Can we internalize the searching capabilities to fundamentally enhance the reasoning abilities of a single LLM? This work explores an orthogonal direction focusing on post-training LLMs for autoregressive searching (i.e., an extended reasoning process with self-reflection and self-exploration of new strategies). To achieve this, we propose the Chain-of-Action-Thought (COAT) reasoning and a two-stage training paradigm: 1) a small-scale format tuning stage to internalize the COAT reasoning format and 2) a large-scale self-improvement stage leveraging reinforcement learning. Our approach results in Satori, a 7B LLM trained on open-source models and data. Extensive empirical evaluations demonstrate that Satori achieves state-of-the-art performance on mathematical reasoning benchmarks while exhibits strong generalization to out-of-domain tasks. Code, data, and models will be fully open-sourced.
VCA: Video Curious Agent for Long Video Understanding
Dec 12, 2024
Long video understanding poses unique challenges due to their temporal complexity and low information density. Recent works address this task by sampling numerous frames or incorporating auxiliary tools using LLMs, both of which result in high computational costs. In this work, we introduce a curiosity-driven video agent with self-exploration capability, dubbed as VCA. Built upon VLMs, VCA autonomously navigates video segments and efficiently builds a comprehensive understanding of complex video sequences. Instead of directly sampling frames, VCA employs a tree-search structure to explore video segments and collect frames. Rather than relying on external feedback or reward, VCA leverages VLM's self-generated intrinsic reward to guide its exploration, enabling it to capture the most crucial information for reasoning. Experimental results on multiple long video benchmarks demonstrate our approach's superior effectiveness and efficiency.
Get Large Language Models Ready to Speak: A Late-fusion Approach for Speech Generation
Oct 27, 2024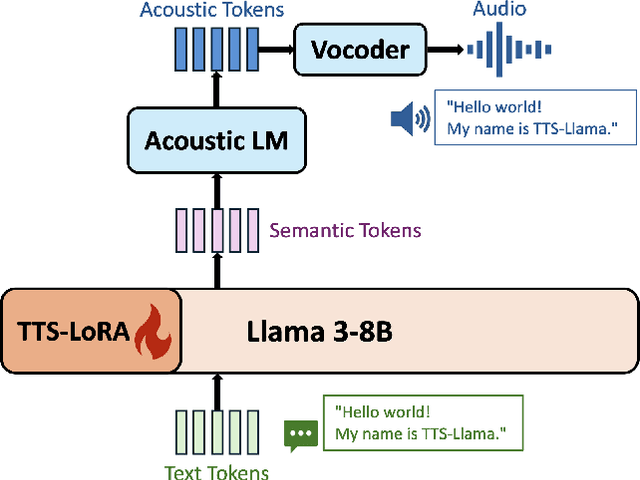
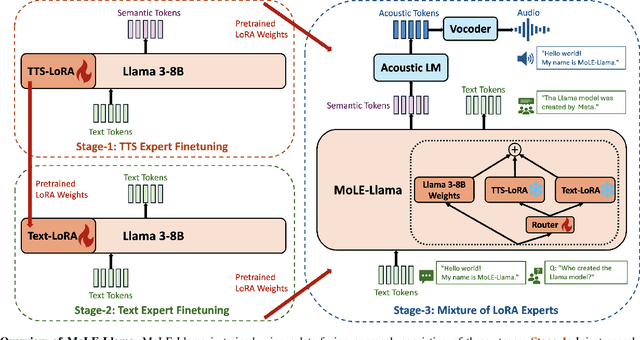
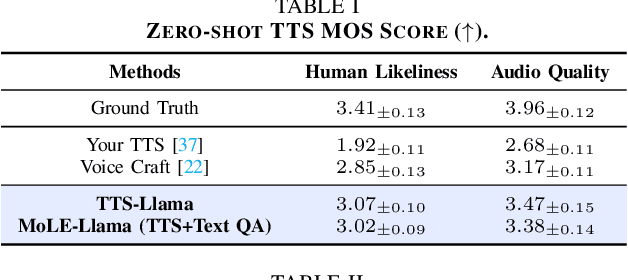
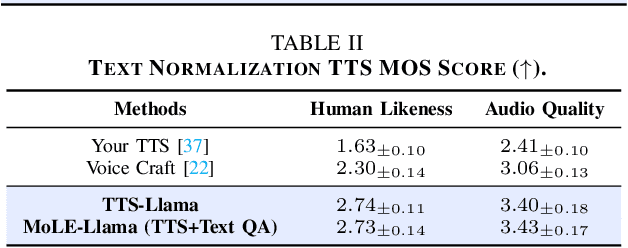
Large language models (LLMs) have revolutionized natural language processing (NLP) with impressive performance across various text-based tasks. However, the extension of text-dominant LLMs to with speech generation tasks remains under-explored. In this work, we introduce a text-to-speech (TTS) system powered by a fine-tuned Llama model, named TTS-Llama, that achieves state-of-the-art speech synthesis performance. Building on TTS-Llama, we further propose MoLE-Llama, a text-and-speech multimodal LLM developed through purely late-fusion parameter-efficient fine-tuning (PEFT) and a mixture-of-expert architecture. Extensive empirical results demonstrate MoLE-Llama's competitive performance on both text-only question-answering (QA) and TTS tasks, mitigating catastrophic forgetting issue in either modality. Finally, we further explore MoLE-Llama in text-in-speech-out QA tasks, demonstrating its great potential as a multimodal dialog system capable of speech generation.
Improved Evidential Deep Learning via a Mixture of Dirichlet Distributions
Feb 09, 2024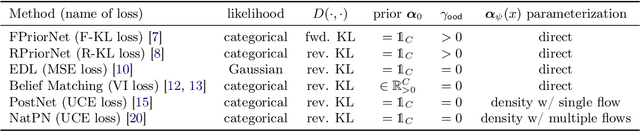
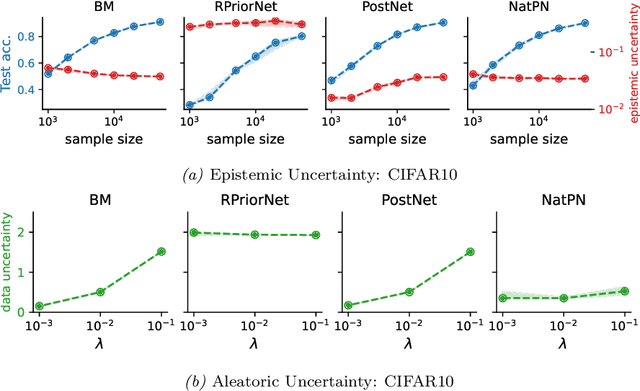
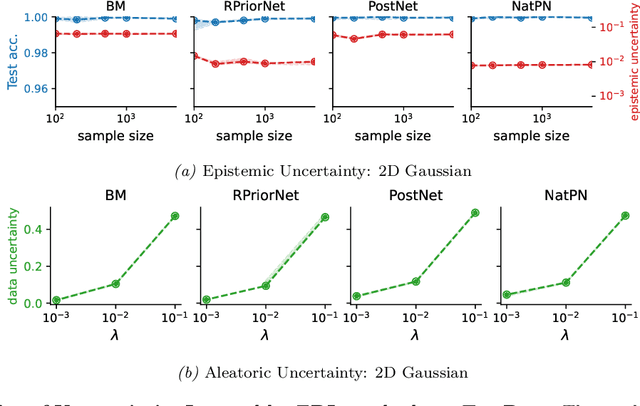
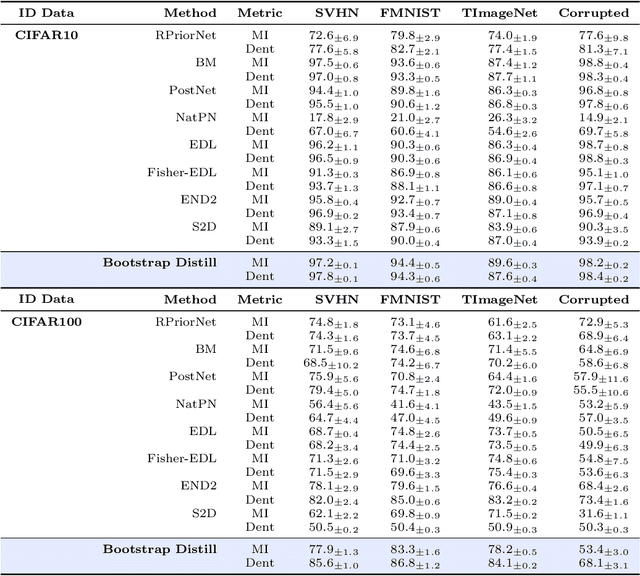
This paper explores a modern predictive uncertainty estimation approach, called evidential deep learning (EDL), in which a single neural network model is trained to learn a meta distribution over the predictive distribution by minimizing a specific objective function. Despite their strong empirical performance, recent studies by Bengs et al. identify a fundamental pitfall of the existing methods: the learned epistemic uncertainty may not vanish even in the infinite-sample limit. We corroborate the observation by providing a unifying view of a class of widely used objectives from the literature. Our analysis reveals that the EDL methods essentially train a meta distribution by minimizing a certain divergence measure between the distribution and a sample-size-independent target distribution, resulting in spurious epistemic uncertainty. Grounded in theoretical principles, we propose learning a consistent target distribution by modeling it with a mixture of Dirichlet distributions and learning via variational inference. Afterward, a final meta distribution model distills the learned uncertainty from the target model. Experimental results across various uncertainty-based downstream tasks demonstrate the superiority of our proposed method, and illustrate the practical implications arising from the consistency and inconsistency of learned epistemic uncertainty.
Reliable Gradient-free and Likelihood-free Prompt Tuning
Apr 30, 2023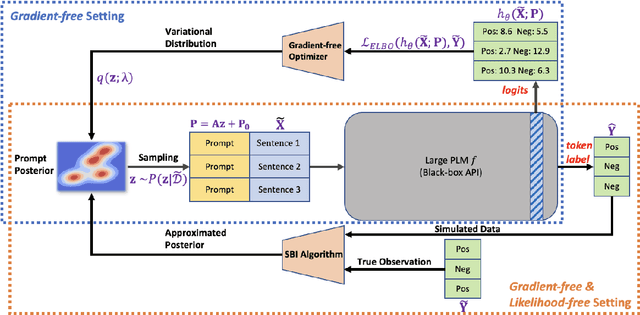
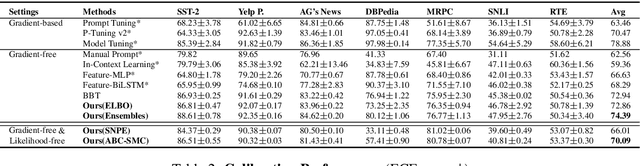

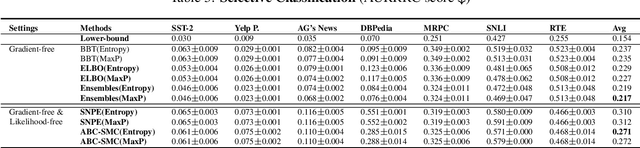
Due to privacy or commercial constraints, large pre-trained language models (PLMs) are often offered as black-box APIs. Fine-tuning such models to downstream tasks is challenging because one can neither access the model's internal representations nor propagate gradients through it. This paper addresses these challenges by developing techniques for adapting PLMs with only API access. Building on recent work on soft prompt tuning, we develop methods to tune the soft prompts without requiring gradient computation. Further, we develop extensions that in addition to not requiring gradients also do not need to access any internal representation of the PLM beyond the input embeddings. Moreover, instead of learning a single prompt, our methods learn a distribution over prompts allowing us to quantify predictive uncertainty. Ours is the first work to consider uncertainty in prompts when only having API access to the PLM. Finally, through extensive experiments, we carefully vet the proposed methods and find them competitive with (and sometimes even improving on) gradient-based approaches with full access to the PLM.
Group Fairness with Uncertainty in Sensitive Attributes
Feb 16, 2023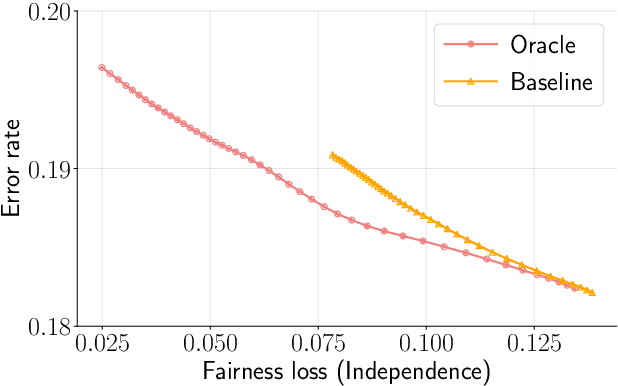

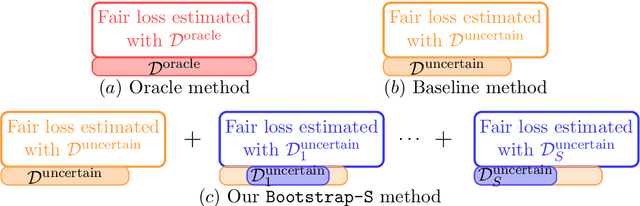
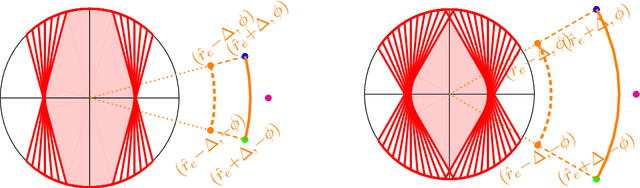
We consider learning a fair predictive model when sensitive attributes are uncertain, say, due to a limited amount of labeled data, collection bias, or privacy mechanism. We formulate the problem, for the independence notion of fairness, using the information bottleneck principle, and propose a robust optimization with respect to an uncertainty set of the sensitive attributes. As an illustrative case, we consider the joint Gaussian model and reduce the task to a quadratically constrained quadratic problem (QCQP). To ensure a strict fairness guarantee, we propose a robust QCQP and completely characterize its solution with an intuitive geometric understanding. When uncertainty arises due to limited labeled sensitive attributes, our analysis reveals the contribution of each new sample towards the optimal performance achieved with unlimited access to labeled sensitive attributes. This allows us to identify non-trivial regimes where uncertainty incurs no performance loss of the proposed algorithm while continuing to guarantee strict fairness. We also propose a bootstrap-based generic algorithm that is applicable beyond the Gaussian case. We demonstrate the value of our analysis and method on synthetic data as well as real-world classification and regression tasks.