 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Active Learning from the Perspective of Sparse Approximation
Nov 05, 2022

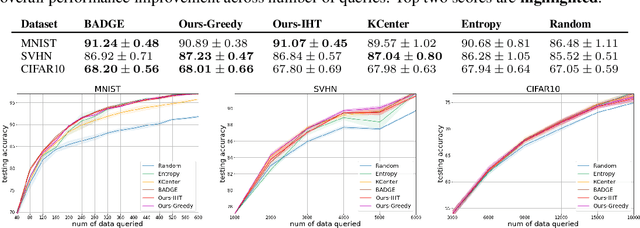

Active learning enables efficient model training by leveraging interactions between machine learning agents and human annotators. We study and propose a novel framework that formulates batch active learning from the sparse approximation's perspective. Our active learning method aims to find an informative subset from the unlabeled data pool such that the corresponding training loss function approximates its full data pool counterpart. We realize the framework as sparsity-constrained discontinuous optimization problems, which explicitly balance uncertainty and representation for large-scale applications and could be solved by greedy or proximal iterative hard thresholding algorithms. The proposed method can adapt to various settings, including both Bayesian and non-Bayesian neural networks. Numerical experiments show that our work achieves competitive performance across different settings with lower computational complexity.
Adversarially Robust Models may not Transfer Better: Sufficient Conditions for Domain Transferability from the View of Regularization
Feb 03, 2022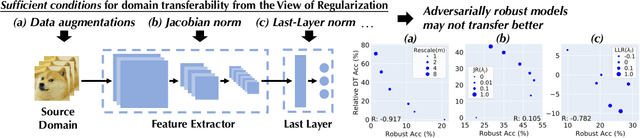
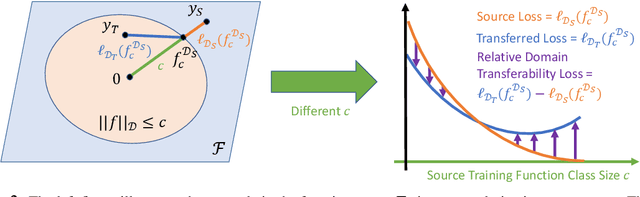
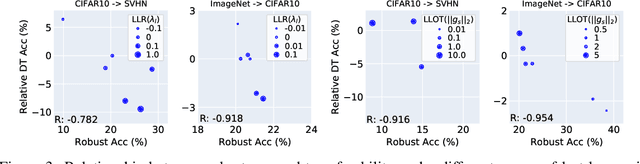
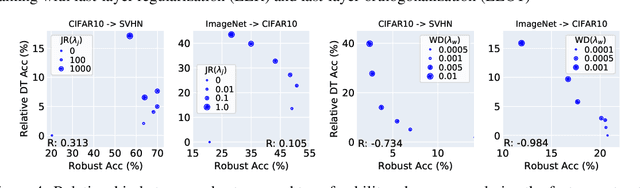
Machine learning (ML) robustness and domain generalization are fundamentally correlated: they essentially concern data distribution shifts under adversarial and natural settings, respectively. On one hand, recent studies show that more robust (adversarially trained) models are more generalizable. On the other hand, there is a lack of theoretical understanding of their fundamental connections. In this paper, we explore the relationship between regularization and domain transferability considering different factors such as norm regularization and data augmentations (DA). We propose a general theoretical framework proving that factors involving the model function class regularization are sufficient conditions for relative domain transferability. Our analysis implies that "robustness" is neither necessary nor sufficient for transferability; rather, robustness induced by adversarial training is a by-product of such function class regularization. We then discuss popular DA protocols and show when they can be viewed as the function class regularization under certain conditions and therefore improve generalization. We conduct extensive experiments to verify our theoretical findings and show several counterexamples where robustness and generalization are negatively correlated on different datasets.