 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUARD: Guided Unlearning and Retention via Data Attribution for Large Language Models
Jun 12, 2025Unlearning in large language models (LLMs) is becoming increasingly important due to regulatory compliance, copyright protection, and privacy concerns. However, a key challenge in LLM unlearning is unintended forgetting, where the removal of specific data inadvertently impairs the utility of the model and its retention of valuable, desired information. While prior work has primarily focused on architectural innovations, the influence of data-level factors on unlearning performance remains underexplored. As a result, existing methods often suffer from degraded retention when forgetting high-impact data. To address this, we propose GUARD-a novel framework for Guided Unlearning And Retention via Data attribution. At its core, GUARD introduces a lightweight proxy data attribution metric tailored for LLM unlearning, which quantifies the "alignment" between the forget and retain sets while remaining computationally efficient. Building on this, we design a novel unlearning objective that assigns adaptive, nonuniform unlearning weights to samples, inversely proportional to their proxy attribution scores. Through such a reallocation of unlearning power, GUARD mitigates unintended losses in retention. We provide rigorous theoretical guarantees that GUARD significantly enhances retention while maintaining forgetting metrics comparable to prior methods. Extensive experiments on the TOFU benchmark across multiple LLM architectures demonstrate that GUARD substantially improves utility preservation while ensuring effective unlearning. Notably, GUARD reduces utility sacrifice on the Retain Set by up to 194.92% in terms of Truth Ratio when forgetting 10% of the training data.
FedGTST: Boosting Global Transferability of Federated Models via Statistics Tuning
Oct 16, 2024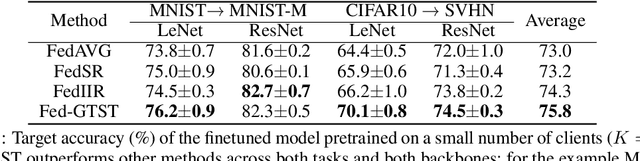
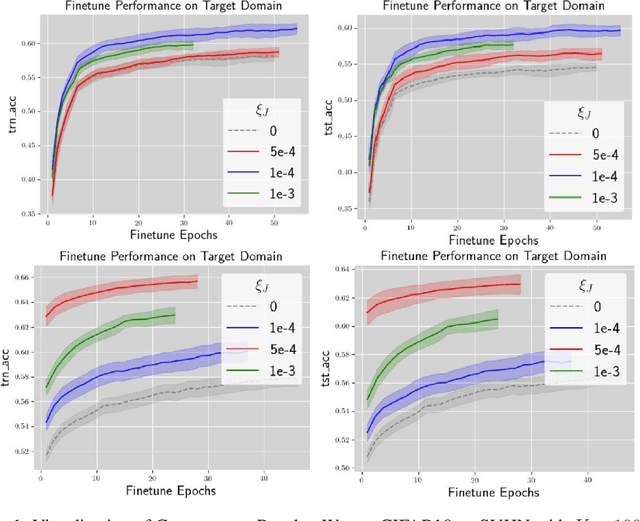
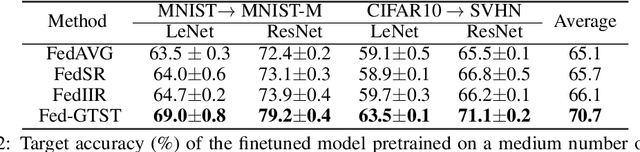
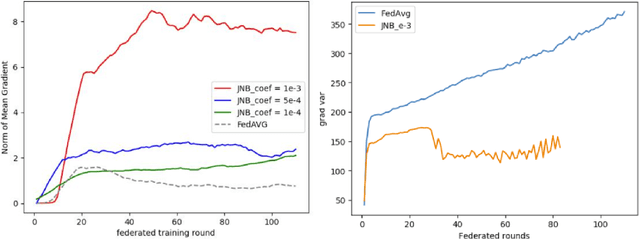
The performance of Transfer Learning (TL) heavily relies on effective pretraining, which demands large datasets and substantial computational resources. As a result, executing TL is often challenging for individual model developers. Federated Learning (FL) addresses these issues by facilitating collaborations among clients, expanding the dataset indirectly, distributing computational costs, and preserving privacy. However, key challenges remain unresolved. First, existing FL methods tend to optimize transferability only within local domains, neglecting the global learning domain. Second, most approaches rely on indirect transferability metrics, which do not accurately reflect the final target loss or true degree of transferability. To address these gaps, we propose two enhancements to FL. First, we introduce a client-server exchange protocol that leverages cross-client Jacobian (gradient) norms to boost transferability. Second, we increase the average Jacobian norm across clients at the server, using this as a local regularizer to reduce cross-client Jacobian variance. Our transferable federated algorithm, termed FedGTST (Federated Global Transferability via Statistics Tuning), demonstrates that increasing the average Jacobian and reducing its variance allows for tighter control of the target loss. This leads to an upper bound on the target loss in terms of the source loss and source-target domain discrepancy. Extensive experiments on datasets such as MNIST to MNIST-M and CIFAR10 to SVHN show that FedGTST outperforms relevant baselines, including FedSR. On the second dataset pair, FedGTST improves accuracy by 9.8% over FedSR and 7.6% over FedIIR when LeNet is used as the backbone.
Local Environment Poisoning Attacks on Federated Reinforcement Learning
Mar 18, 2023



Federated learning (FL) has become a popular tool for solving traditional Reinforcement Learning (RL) tasks. The multi-agent structure addresses the major concern of data-hungry in traditional RL, while the federated mechanism protects the data privacy of individual agents. However, the federated mechanism also exposes the system to poisoning by malicious agents that can mislead the trained policy. Despite the advantage brought by FL, the vulnerability of Federated Reinforcement Learning (FRL) has not been well-studied before. In this work, we propose the first general framework to characterize FRL poisoning as an optimization problem constrained by a limited budget and design a poisoning protocol that can be applied to policy-based FRL and extended to FRL with actor-critic as a local RL algorithm by training a pair of private and public critics. We also discuss a conventional defense strategy inherited from FL to mitigate this risk. We verify our poisoning effectiveness by conducting extensive experiments targeting mainstream RL algorithms and over various RL OpenAI Gym environments covering a wide range of difficulty levels. Our results show that our proposed defense protocol is successful in most cases but is not robust under complicated environments. Our work provides new insights into the vulnerability of FL in RL training and poses additional challenges for designing robust FRL algorithms.
Adversarially Robust Models may not Transfer Better: Sufficient Conditions for Domain Transferability from the View of Regularization
Feb 03, 2022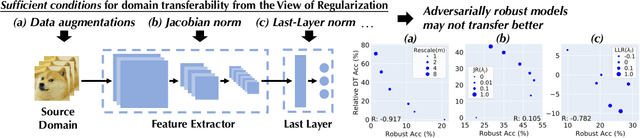
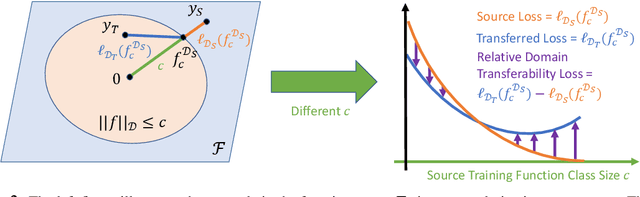
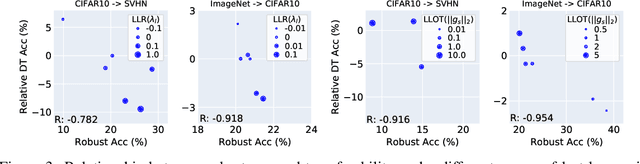
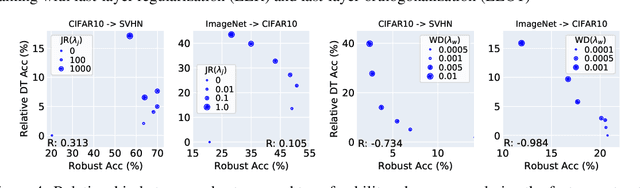
Machine learning (ML) robustness and domain generalization are fundamentally correlated: they essentially concern data distribution shifts under adversarial and natural settings, respectively. On one hand, recent studies show that more robust (adversarially trained) models are more generalizable. On the other hand, there is a lack of theoretical understanding of their fundamental connections. In this paper, we explore the relationship between regularization and domain transferability considering different factors such as norm regularization and data augmentations (DA). We propose a general theoretical framework proving that factors involving the model function class regularization are sufficient conditions for relative domain transferability. Our analysis implies that "robustness" is neither necessary nor sufficient for transferability; rather, robustness induced by adversarial training is a by-product of such function class regularization. We then discuss popular DA protocols and show when they can be viewed as the function class regularization under certain conditions and therefore improve generalization. We conduct extensive experiments to verify our theoretical findings and show several counterexamples where robustness and generalization are negatively correlated on different datasets.