 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Evidential Deep Learning via a Mixture of Dirichlet Distributions
Paper and Code
Feb 09, 2024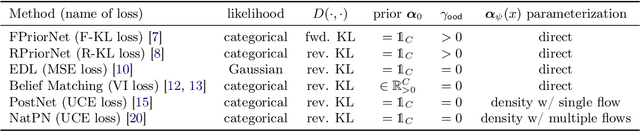
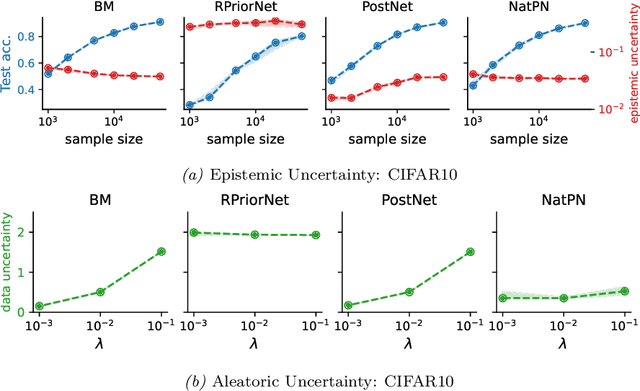
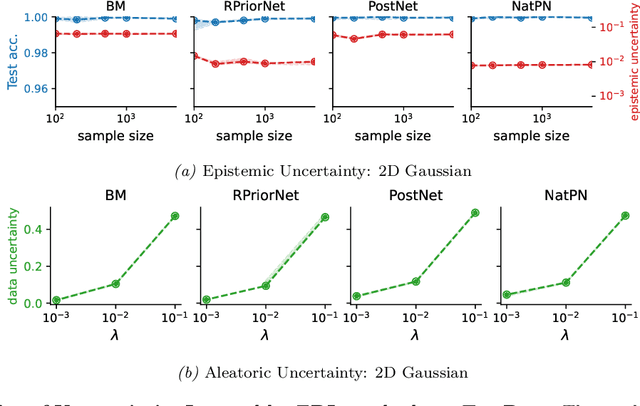
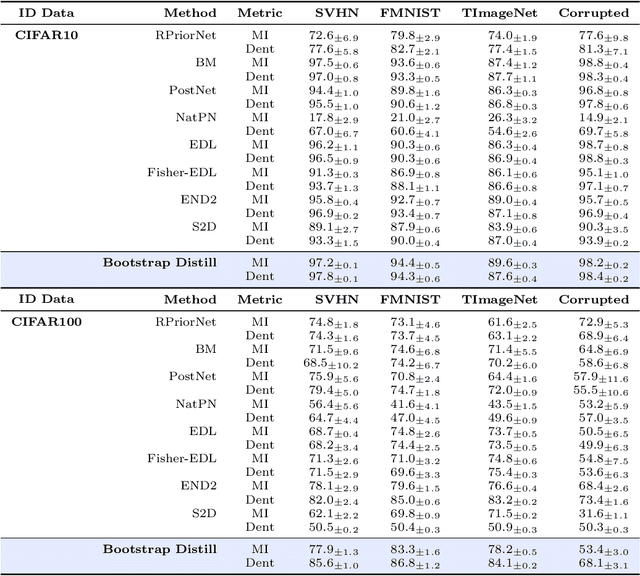
This paper explores a modern predictive uncertainty estimation approach, called evidential deep learning (EDL), in which a single neural network model is trained to learn a meta distribution over the predictive distribution by minimizing a specific objective function. Despite their strong empirical performance, recent studies by Bengs et al. identify a fundamental pitfall of the existing methods: the learned epistemic uncertainty may not vanish even in the infinite-sample limit. We corroborate the observation by providing a unifying view of a class of widely used objectives from the literature. Our analysis reveals that the EDL methods essentially train a meta distribution by minimizing a certain divergence measure between the distribution and a sample-size-independent target distribution, resulting in spurious epistemic uncertainty. Grounded in theoretical principles, we propose learning a consistent target distribution by modeling it with a mixture of Dirichlet distributions and learning via variational inference. Afterward, a final meta distribution model distills the learned uncertainty from the target model. Experimental results across various uncertainty-based downstream tasks demonstrate the superiority of our proposed method, and illustrate the practical implications arising from the consistency and inconsistency of learned epistemic uncertainty.