 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
May 28, 2026Embodied intelligence is often studied through specialized models for individual tasks such as manipulation or navigation, resulting in fragmented capabilities and limited generalization across tasks, environments, and robot embodiments. In this work, we study whether heterogeneous embodied decision-making problems can be unified within a single vision-language-action model. We present Qwen-VLA, a unified embodied foundation model that extends Qwen's vision-language modeling stack from perception, understanding, and reasoning to continuous action and trajectory generation through a DiT-based action decoder. Qwen-VLA is trained with a large-scale joint pretraining recipe over diverse data sources, including robotics manipulation trajectories, human egocentric demonstrations, synthetic simulation data, vision-and-language navigation data, trajectory-centric supervision, and auxiliary vision-language data. To support multiple robot platforms, we introduce embodiment-aware prompt conditioning, where robot-specific textual descriptions specify the current embodiment and control convention. We further cast manipulation, navigation, and trajectory prediction into a unified action-and-trajectory prediction framework, enabling transferable visual grounding, spatial reasoning, and continuous action generation across robot morphologies, task families, and environments. Experiments on manipulation, navigation, and trajectory-centric benchmarks show consistent multi-task performance and out-of-distribution generalization under variations in scene layout, background, lighting, object configuration, and robot embodiment. Qwen-VLA-Instruct achieves 97.9% on LIBERO, 73.7% on Simpler-WidowX, 86.1%/87.2% on RoboTwin-Easy/Hard, 69.0% OSR on R2R, 59.6% SR on RxR, 76.9% average OOD success in real-world ALOHA experiments, and 26.6% zero-shot success on DOMINO dynamic manipulation.
Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering
May 29, 2025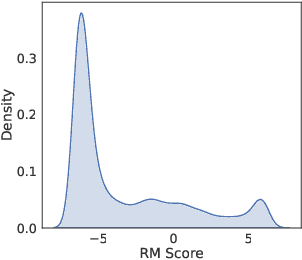
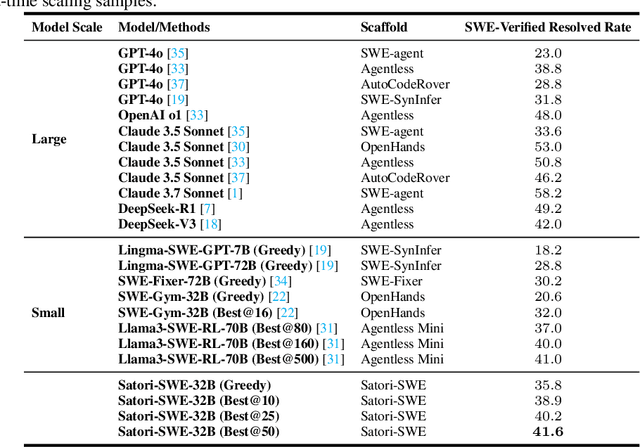
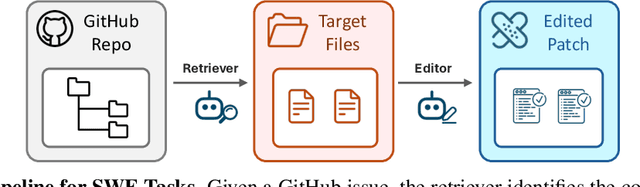

Language models (LMs) perform well on standardized coding benchmarks but struggle with real-world software engineering tasks such as resolving GitHub issues in SWE-Bench, especially when model parameters are less than 100B. While smaller models are preferable in practice due to their lower computational cost, improving their performance remains challenging. Existing approaches primarily rely on supervised fine-tuning (SFT) with high-quality data, which is expensive to curate at scale. An alternative is test-time scaling: generating multiple outputs, scoring them using a verifier, and selecting the best one. Although effective, this strategy often requires excessive sampling and costly scoring, limiting its practical application. We propose Evolutionary Test-Time Scaling (EvoScale), a sample-efficient method that treats generation as an evolutionary process. By iteratively refining outputs via selection and mutation, EvoScale shifts the output distribution toward higher-scoring regions, reducing the number of samples needed to find correct solutions. To reduce the overhead from repeatedly sampling and selection, we train the model to self-evolve using reinforcement learning (RL). Rather than relying on external verifiers at inference time, the model learns to self-improve the scores of its own generations across iterations. Evaluated on SWE-Bench-Verified, EvoScale enables our 32B model, Satori-SWE-32B, to match or exceed the performance of models with over 100B parameters while using a few samples. Code, data, and models will be fully open-sourced.
Scaling Autonomous Agents via Automatic Reward Modeling And Planning
Feb 17, 2025Large language models (LLMs) have demonstrated remarkable capabilities across a range of text-generation tasks. However, LLMs still struggle with problems requiring multi-step decision-making and environmental feedback, such as online shopping, scientific reasoning, and mathematical problem-solving. Unlike pure text data, collecting large-scale decision-making data is challenging. Moreover, many powerful LLMs are only accessible through APIs, which hinders their fine-tuning for agent tasks due to cost and complexity. To address LLM agents' limitations, we propose a framework that can automatically learn a reward model from the environment without human annotations. This model can be used to evaluate the action trajectories of LLM agents and provide heuristics for task planning. Specifically, our approach involves employing one LLM-based agent to navigate an environment randomly, generating diverse action trajectories. Subsequently, a separate LLM is leveraged to assign a task intent and synthesize a negative response alongside the correct response for each trajectory. These triplets (task intent, positive response, and negative response) are then utilized as training data to optimize a reward model capable of scoring action trajectories. The effectiveness and generalizability of our framework are demonstrated through evaluations conducted on different agent benchmarks. In conclusion, our proposed framework represents a significant advancement in enhancing LLM agents' decision-making capabilities. By automating the learning of reward models, we overcome the challenges of data scarcity and API limitations, potentially revolutionizing the application of LLMs in complex and interactive environments. This research paves the way for more sophisticated AI agents capable of tackling a wide range of real-world problems requiring multi-step decision-making.
VCA: Video Curious Agent for Long Video Understanding
Dec 12, 2024
Long video understanding poses unique challenges due to their temporal complexity and low information density. Recent works address this task by sampling numerous frames or incorporating auxiliary tools using LLMs, both of which result in high computational costs. In this work, we introduce a curiosity-driven video agent with self-exploration capability, dubbed as VCA. Built upon VLMs, VCA autonomously navigates video segments and efficiently builds a comprehensive understanding of complex video sequences. Instead of directly sampling frames, VCA employs a tree-search structure to explore video segments and collect frames. Rather than relying on external feedback or reward, VCA leverages VLM's self-generated intrinsic reward to guide its exploration, enabling it to capture the most crucial information for reasoning. Experimental results on multiple long video benchmarks demonstrate our approach's superior effectiveness and efficiency.
Improving Causal Reasoning in Large Language Models: A Survey
Oct 22, 2024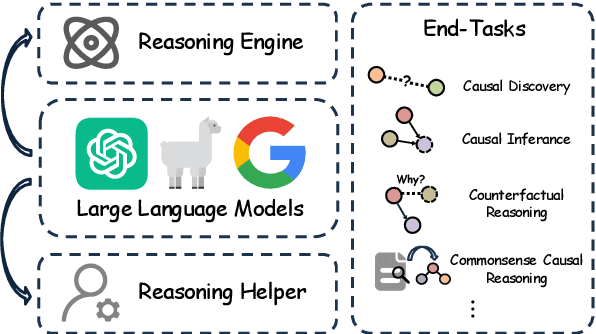
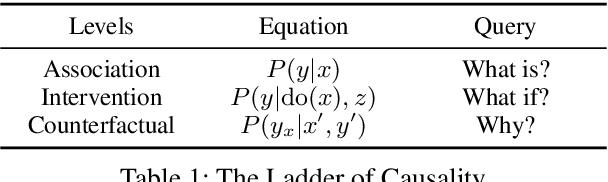


Causal reasoning (CR) is a crucial aspect of intelligence, essential for problem-solving, decision-making, and understanding the world. While large language models (LLMs) can generate rationales for their outputs, their ability to reliably perform causal reasoning remains uncertain, often falling short in tasks requiring a deep understanding of causality. In this survey, we provide a comprehensive review of research aimed at enhancing LLMs for causal reasoning. We categorize existing methods based on the role of LLMs: either as reasoning engines or as helpers providing knowledge or data to traditional CR methods, followed by a detailed discussion of the methodologies in each category. We then evaluate the performance of LLMs on various causal reasoning tasks, providing key findings and in-depth analysis. Finally, we provide insights from current studies and highlight promising directions for future research. We aim for this work to serve as a comprehensive resource, fostering further advancements in causal reasoning with LLMs. Resources are available at https://github.com/chendl02/Awesome-LLM-causal-reasoning.
FlexAttention for Efficient High-Resolution Vision-Language Models
Jul 29, 2024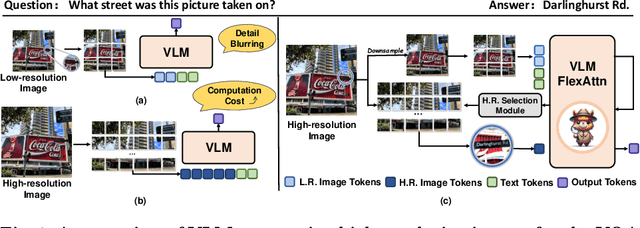
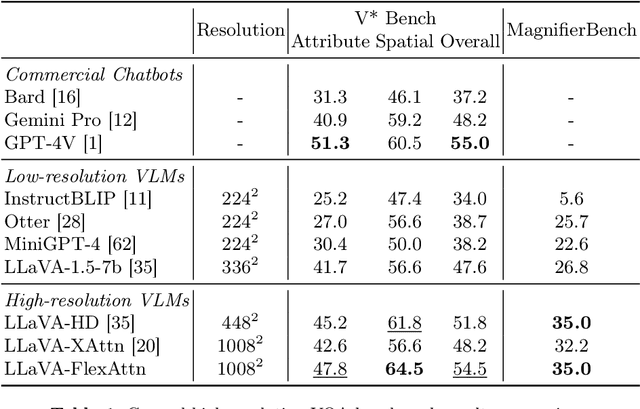
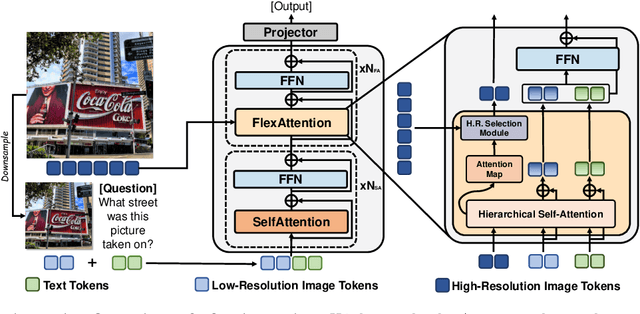
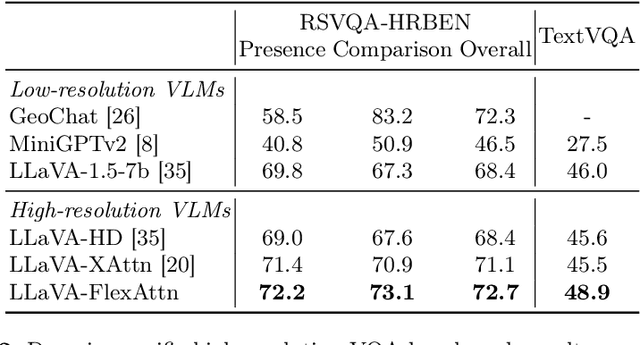
Current high-resolution vision-language models encode images as high-resolution image tokens and exhaustively take all these tokens to compute attention, which significantly increases the computational cost. To address this problem, we propose FlexAttention, a flexible attention mechanism for efficient high-resolution vision-language models. Specifically, a high-resolution image is encoded both as high-resolution tokens and low-resolution tokens, where only the low-resolution tokens and a few selected high-resolution tokens are utilized to calculate the attention map, which greatly shrinks the computational cost. The high-resolution tokens are selected via a high-resolution selection module which could retrieve tokens of relevant regions based on an input attention map. The selected high-resolution tokens are then concatenated to the low-resolution tokens and text tokens, and input to a hierarchical self-attention layer which produces an attention map that could be used for the next-step high-resolution token selection. The hierarchical self-attention process and high-resolution token selection process are performed iteratively for each attention layer. Experiments on multimodal benchmarks prove that our FlexAttention outperforms existing high-resolution VLMs (e.g., relatively ~9% in V* Bench, ~7% in TextVQA), while also significantly reducing the computational cost by nearly 40%.
CoVLM: Composing Visual Entities and Relationships in Large Language Models Via Communicative Decoding
Nov 06, 2023



A remarkable ability of human beings resides in compositional reasoning, i.e., the capacity to make "infinite use of finite means". However, current large vision-language foundation models (VLMs) fall short of such compositional abilities due to their "bag-of-words" behaviors and inability to construct words that correctly represent visual entities and the relations among the entities. To this end, we propose CoVLM, which can guide the LLM to explicitly compose visual entities and relationships among the text and dynamically communicate with the vision encoder and detection network to achieve vision-language communicative decoding. Specifically, we first devise a set of novel communication tokens for the LLM, for dynamic communication between the visual detection system and the language system. A communication token is generated by the LLM following a visual entity or a relation, to inform the detection network to propose regions that are relevant to the sentence generated so far. The proposed regions-of-interests (ROIs) are then fed back into the LLM for better language generation contingent on the relevant regions. The LLM is thus able to compose the visual entities and relationships through the communication tokens. The vision-to-language and language-to-vision communication are iteratively performed until the entire sentence is generated. Our framework seamlessly bridges the gap between visual perception and LLMs and outperforms previous VLMs by a large margin on compositional reasoning benchmarks (e.g., ~20% in HICO-DET mAP, ~14% in Cola top-1 accuracy, and ~3% on ARO top-1 accuracy). We also achieve state-of-the-art performances on traditional vision-language tasks such as referring expression comprehension and visual question answering.
TransRef: Multi-Scale Reference Embedding Transformer for Reference-Guided Image Inpainting
Jun 21, 2023



Image inpainting for completing complicated semantic environments and diverse hole patterns of corrupted images is challenging even for state-of-the-art learning-based inpainting methods trained on large-scale data. A reference image capturing the same scene of a corrupted image offers informative guidance for completing the corrupted image as it shares similar texture and structure priors to that of the holes of the corrupted image. In this work, we propose a transformer-based encoder-decoder network, named TransRef, for reference-guided image inpainting. Specifically, the guidance is conducted progressively through a reference embedding procedure, in which the referencing features are subsequently aligned and fused with the features of the corrupted image. For precise utilization of the reference features for guidance, a reference-patch alignment (Ref-PA) module is proposed to align the patch features of the reference and corrupted images and harmonize their style differences, while a reference-patch transformer (Ref-PT) module is proposed to refine the embedded reference feature. Moreover, to facilitate the research of reference-guided image restoration tasks, we construct a publicly accessible benchmark dataset containing 50K pairs of input and reference images. Both quantitative and qualitative evaluations demonstrate the efficacy of the reference information and the proposed method over the state-of-the-art methods in completing complex holes. Code and dataset can be accessed at https://github.com/Cameltr/TransRef.