 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneration Order and Parallel Decoding in Masked Diffusion Models: An Information-Theoretic Perspective
Jan 30, 2026Masked Diffusion Models (MDMs) significantly accelerate inference by trading off sequential determinism. However, the theoretical mechanisms governing generation order and the risks inherent in parallelization remain under-explored. In this work, we provide a unified information-theoretic framework to decouple and analyze two fundamental sources of failure: order sensitivity and parallelization bias. Our analysis yields three key insights: (1) The benefits of Easy-First decoding (prioritizing low-entropy tokens) are magnified as model error increases; (2) factorized parallel decoding introduces intrinsic sampling errors that can lead to arbitrary large Reverse KL divergence, capturing "incoherence" failures that standard Forward KL metrics overlook; and (3) while verification can eliminate sampling error, it incurs an exponential cost governed by the total correlation within a block. Conversely, heuristics like remasking, though computationally efficient, cannot guarantee distributional correctness. Experiments on a controlled Block-HMM and large-scale MDMs (LLaDA) for arithmetic reasoning validate our theoretical framework.
Thinking Out of Order: When Output Order Stops Reflecting Reasoning Order in Diffusion Language Models
Jan 29, 2026Autoregressive (AR) language models enforce a fixed left-to-right generation order, creating a fundamental limitation when the required output structure conflicts with natural reasoning (e.g., producing answers before explanations due to presentation or schema constraints). In such cases, AR models must commit to answers before generating intermediate reasoning, and this rigid constraint forces premature commitment. Masked diffusion language models (MDLMs), which iteratively refine all tokens in parallel, offer a way to decouple computation order from output structure. We validate this capability on GSM8K, Math500, and ReasonOrderQA, a benchmark we introduce with controlled difficulty and order-level evaluation. When prompts request answers before reasoning, AR models exhibit large accuracy gaps compared to standard chain-of-thought ordering (up to 67% relative drop), while MDLMs remain stable ($\leq$14% relative drop), a property we term "order robustness". Using ReasonOrderQA, we present evidence that MDLMs achieve order robustness by stabilizing simpler tokens (e.g., reasoning steps) earlier in the diffusion process than complex ones (e.g., final answers), enabling reasoning tokens to stabilize before answer commitment. Finally, we identify failure conditions where this advantage weakens, outlining the limits required for order robustness.
Improving Causal Reasoning in Large Language Models: A Survey
Oct 22, 2024
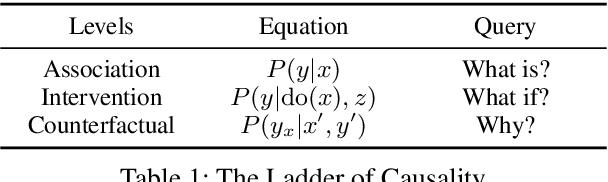


Causal reasoning (CR) is a crucial aspect of intelligence, essential for problem-solving, decision-making, and understanding the world. While large language models (LLMs) can generate rationales for their outputs, their ability to reliably perform causal reasoning remains uncertain, often falling short in tasks requiring a deep understanding of causality. In this survey, we provide a comprehensive review of research aimed at enhancing LLMs for causal reasoning. We categorize existing methods based on the role of LLMs: either as reasoning engines or as helpers providing knowledge or data to traditional CR methods, followed by a detailed discussion of the methodologies in each category. We then evaluate the performance of LLMs on various causal reasoning tasks, providing key findings and in-depth analysis. Finally, we provide insights from current studies and highlight promising directions for future research. We aim for this work to serve as a comprehensive resource, fostering further advancements in causal reasoning with LLMs. Resources are available at https://github.com/chendl02/Awesome-LLM-causal-reasoning.