 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLAM-LLM: A Modular, Open-Source Multimodal Large Language Model Framework and Best Practice for Speech, Language, Audio and Music Processing
Jan 14, 2026The recent surge in open-source Multimodal Large Language Models (MLLM) frameworks, such as LLaVA, provides a convenient kickoff for artificial intelligence developers and researchers. However, most of the MLLM frameworks take vision as the main input modality, and provide limited in-depth support for the modality of speech, audio, and music. This situation hinders the development of audio-language models, and forces researchers to spend a lot of effort on code writing and hyperparameter tuning. We present SLAM-LLM, an open-source deep learning framework designed to train customized MLLMs, focused on speech, language, audio, and music processing. SLAM-LLM provides a modular configuration of different encoders, projectors, LLMs, and parameter-efficient fine-tuning plugins. SLAM-LLM also includes detailed training and inference recipes for mainstream tasks, along with high-performance checkpoints like LLM-based Automatic Speech Recognition (ASR), Automated Audio Captioning (AAC), and Music Captioning (MC). Some of these recipes have already reached or are nearing state-of-the-art performance, and some relevant techniques have also been accepted by academic papers. We hope SLAM-LLM will accelerate iteration, development, data engineering, and model training for researchers. We are committed to continually pushing forward audio-based MLLMs through this open-source framework, and call on the community to contribute to the LLM-based speech, audio and music processing.
MCGA: A Multi-task Classical Chinese Literary Genre Audio Corpus
Jan 14, 2026With the rapid advancement of Multimodal Large Language Models (MLLMs), their potential has garnered significant attention in Chinese Classical Studies (CCS). While existing research has primarily focused on text and visual modalities, the audio corpus within this domain remains largely underexplored. To bridge this gap, we propose the Multi-task Classical Chinese Literary Genre Audio Corpus (MCGA). It encompasses a diverse range of literary genres across six tasks: Automatic Speech Recognition (ASR), Speech-to-Text Translation (S2TT), Speech Emotion Captioning (SEC), Spoken Question Answering (SQA), Speech Understanding (SU), and Speech Reasoning (SR). Through the evaluation of ten MLLMs, our experimental results demonstrate that current models still face substantial challenges when processed on the MCGA test set. Furthermore, we introduce an evaluation metric for SEC and a metric to measure the consistency between the speech and text capabilities of MLLMs. We release MCGA and our code to the public to facilitate the development of MLLMs with more robust multidimensional audio capabilities in CCS. MCGA Corpus: https://github.com/yxduir/MCGA
CCFQA: A Benchmark for Cross-Lingual and Cross-Modal Speech and Text Factuality Evaluation
Aug 10, 2025As Large Language Models (LLMs) are increasingly popularized in the multilingual world, ensuring hallucination-free factuality becomes markedly crucial. However, existing benchmarks for evaluating the reliability of Multimodal Large Language Models (MLLMs) predominantly focus on textual or visual modalities with a primary emphasis on English, which creates a gap in evaluation when processing multilingual input, especially in speech. To bridge this gap, we propose a novel \textbf{C}ross-lingual and \textbf{C}ross-modal \textbf{F}actuality benchmark (\textbf{CCFQA}). Specifically, the CCFQA benchmark contains parallel speech-text factual questions across 8 languages, designed to systematically evaluate MLLMs' cross-lingual and cross-modal factuality capabilities. Our experimental results demonstrate that current MLLMs still face substantial challenges on the CCFQA benchmark. Furthermore, we propose a few-shot transfer learning strategy that effectively transfers the Question Answering (QA) capabilities of LLMs in English to multilingual Spoken Question Answering (SQA) tasks, achieving competitive performance with GPT-4o-mini-Audio using just 5-shot training. We release CCFQA as a foundational research resource to promote the development of MLLMs with more robust and reliable speech understanding capabilities. Our code and dataset are available at https://github.com/yxduir/ccfqa.
ProjectEval: A Benchmark for Programming Agents Automated Evaluation on Project-Level Code Generation
Mar 10, 2025



Recently, LLM agents have made rapid progress in improving their programming capabilities. However, existing benchmarks lack the ability to automatically evaluate from users' perspective, and also lack the explainability of the results of LLM agents' code generation capabilities. Thus, we introduce ProjectEval, a new benchmark for LLM agents project-level code generation's automated evaluation by simulating user interaction. ProjectEval is constructed by LLM with human reviewing. It has three different level inputs of natural languages or code skeletons. ProjectEval can evaluate the generated projects by user interaction simulation for execution, and by code similarity through existing objective indicators. Through ProjectEval, we find that systematic engineering project code, overall understanding of the project and comprehensive analysis capability are the keys for LLM agents to achieve practical projects. Our findings and benchmark provide valuable insights for developing more effective programming agents that can be deployed in future real-world production.
CoT-ST: Enhancing LLM-based Speech Translation with Multimodal Chain-of-Thought
Sep 29, 2024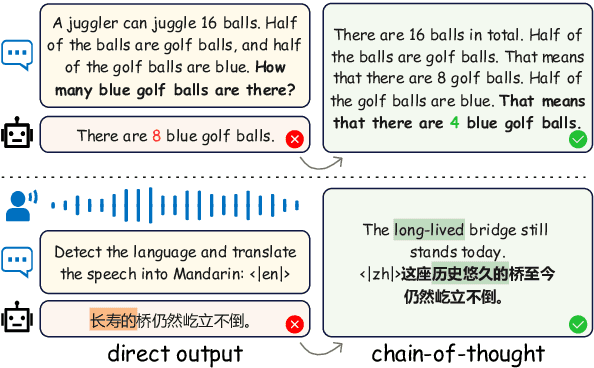

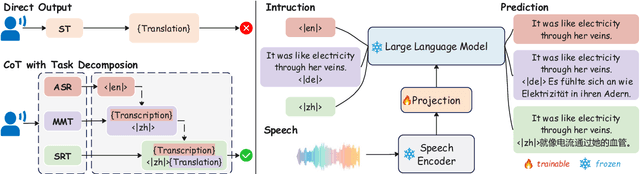
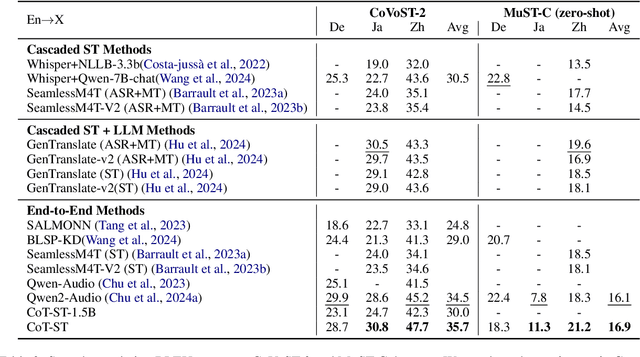
Speech Language Models (SLMs) have demonstrated impressive performance on speech translation tasks. However, existing research primarily focuses on direct instruction fine-tuning and often overlooks the inherent reasoning capabilities of SLMs. In this paper, we introduce a three-stage training framework designed to activate the chain-of-thought (CoT) capabilities of SLMs. We propose CoT-ST, a speech translation model that utilizes multimodal CoT to decompose speech translation into sequential steps of speech recognition and translation. We validated the effectiveness of our method on two datasets: the CoVoST-2 dataset and MuST-C dataset. The experimental results demonstrate that CoT-ST outperforms previous state-of-the-art methods, achieving higher BLEU scores (CoVoST-2 en-ja: 30.5->30.8, en-zh: 45.2->47.7, MuST-C en-zh: 19.6->21.2). This work is open sourced at https://github.com/X-LANCE/SLAM-LLM/tree/main/examples/st_covost2 .
GigaSpeech 2: An Evolving, Large-Scale and Multi-domain ASR Corpus for Low-Resource Languages with Automated Crawling, Transcription and Refinement
Jun 17, 2024The evolution of speech technology has been spurred by the rapid increase in dataset sizes. Traditional speech models generally depend on a large amount of labeled training data, which is scarce for low-resource languages. This paper presents GigaSpeech 2, a large-scale, multi-domain, multilingual speech recognition corpus. It is designed for low-resource languages and does not rely on paired speech and text data. GigaSpeech 2 comprises about 30,000 hours of automatically transcribed speech, including Thai, Indonesian, and Vietnamese, gathered from unlabeled YouTube videos. We also introduce an automated pipeline for data crawling, transcription, and label refinement. Specifically, this pipeline uses Whisper for initial transcription and TorchAudio for forced alignment, combined with multi-dimensional filtering for data quality assurance. A modified Noisy Student Training is developed to further refine flawed pseudo labels iteratively, thus enhancing model performance. Experimental results on our manually transcribed evaluation set and two public test sets from Common Voice and FLEURS confirm our corpus's high quality and broad applicability. Notably, ASR models trained on GigaSpeech 2 can reduce the word error rate for Thai, Indonesian, and Vietnamese on our challenging and realistic YouTube test set by 25% to 40% compared to the Whisper large-v3 model, with merely 10% model parameters. Furthermore, our ASR models trained on Gigaspeech 2 yield superior performance compared to commercial services. We believe that our newly introduced corpus and pipeline will open a new avenue for low-resource speech recognition and significantly facilitate research in this area.