 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Hybrid CTC/Attention End-to-End Automatic Speech Recognition Architecture
Jul 05, 2023



Recently, there has been increasing progress in end-to-end automatic speech recognition (ASR) architecture, which transcribes speech to text without any pre-trained alignments. One popular end-to-end approach is the hybrid Connectionist Temporal Classification (CTC) and attention (CTC/attention) based ASR architecture. However, how to deploy hybrid CTC/attention systems for online speech recognition is still a non-trivial problem. This article describes our proposed online hybrid CTC/attention end-to-end ASR architecture, which replaces all the offline components of conventional CTC/attention ASR architecture with their corresponding streaming components. Firstly, we propose stable monotonic chunk-wise attention (sMoChA) to stream the conventional global attention, and further propose monotonic truncated attention (MTA) to simplify sMoChA and solve the training-and-decoding mismatch problem of sMoChA. Secondly, we propose truncated CTC (T-CTC) prefix score to stream CTC prefix score calculation. Thirdly, we design dynamic waiting joint decoding (DWJD) algorithm to dynamically collect the predictions of CTC and attention in an online manner. Finally, we use latency-controlled bidirectional long short-term memory (LC-BLSTM) to stream the widely-used offline bidirectional encoder network. Experiments with LibriSpeech English and HKUST Mandarin tasks demonstrate that, compared with the offline CTC/attention model, our proposed online CTC/attention model improves the real time factor in human-computer interaction services and maintains its performance with moderate degradation. To the best of our knowledge, this is the first work to provide the full-stack online solution for CTC/attention end-to-end ASR architecture.
Improving Streaming End-to-End ASR on Transformer-based Causal Models with Encoder States Revision Strategies
Jul 06, 2022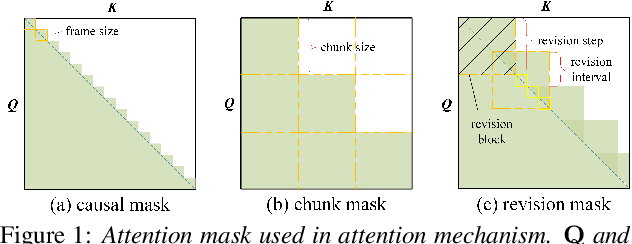
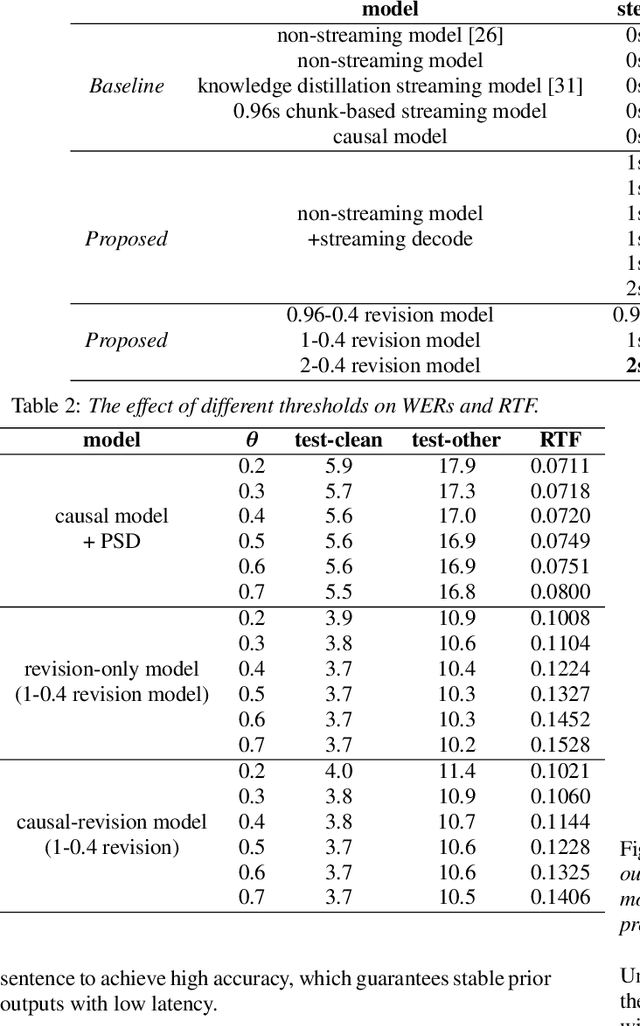
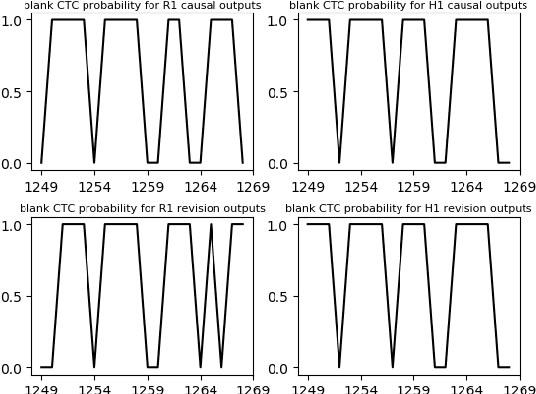
There is often a trade-off between performance and latency in streaming automatic speech recognition (ASR). Traditional methods such as look-ahead and chunk-based methods, usually require information from future frames to advance recognition accuracy, which incurs inevitable latency even if the computation is fast enough. A causal model that computes without any future frames can avoid this latency, but its performance is significantly worse than traditional methods. In this paper, we propose corresponding revision strategies to improve the causal model. Firstly, we introduce a real-time encoder states revision strategy to modify previous states. Encoder forward computation starts once the data is received and revises the previous encoder states after several frames, which is no need to wait for any right context. Furthermore, a CTC spike position alignment decoding algorithm is designed to reduce time costs brought by the revision strategy. Experiments are all conducted on Librispeech datasets. Fine-tuning on the CTC-based wav2vec2.0 model, our best method can achieve 3.7/9.2 WERs on test-clean/other sets, which is also competitive with the chunk-based methods and the knowledge distillation methods.
Streaming non-autoregressive model for any-to-many voice conversion
Jun 15, 2022


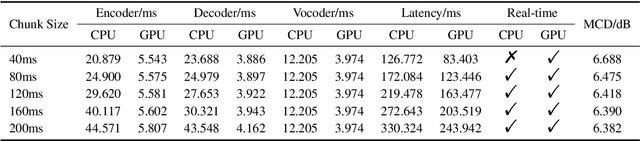
Voice conversion models have developed for decades, and current mainstream research focuses on non-streaming voice conversion. However, streaming voice conversion is more suitable for practical application scenarios than non-streaming voice conversion. In this paper, we propose a streaming any-to-many voice conversion based on fully non-autoregressive model, which includes a streaming transformer based acoustic model and a streaming vocoder. Streaming transformer based acoustic model is composed of a pre-trained encoder from streaming end-to-end based automatic speech recognition model and a decoder modified on FastSpeech blocks. Streaming vocoder is designed for streaming task with pseudo quadrature mirror filter bank and causal convolution. Experimental results show that the proposed method achieves significant performance both in latency and conversion quality and can be real-time on CPU and GPU.
Transformer-based Online CTC/attention End-to-End Speech Recognition Architecture
Feb 11, 2020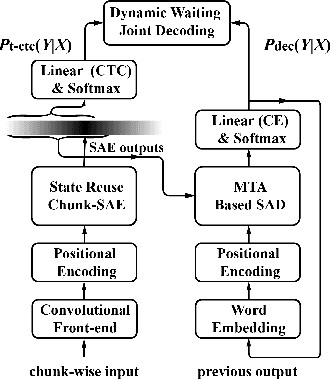

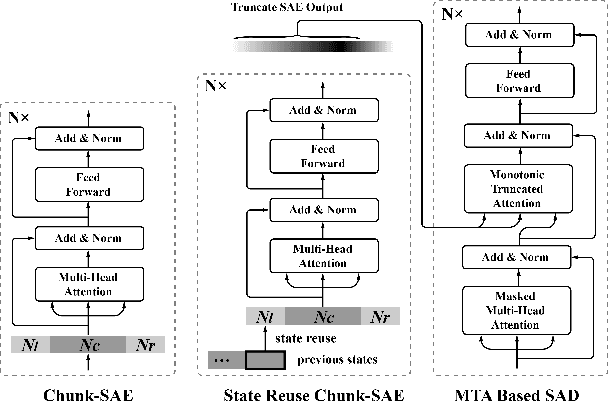

Recently, Transformer has gained success in automatic speech recognition (ASR) field. However, it is challenging to deploy a Transformer-based end-to-end (E2E) model for online speech recognition. In this paper, we propose the Transformer-based online CTC/attention E2E ASR architecture, which contains the chunk self-attention encoder (chunk-SAE) and the monotonic truncated attention (MTA) based self-attention decoder (SAD). Firstly, the chunk-SAE splits the speech into isolated chunks. To reduce the computational cost and improve the performance, we propose the state reuse chunk-SAE. Sencondly, the MTA based SAD truncates the speech features monotonically and performs attention on the truncated features. To support the online recognition, we integrate the state reuse chunk-SAE and the MTA based SAD into online CTC/attention architecture. We evaluate the proposed online models on the HKUST Mandarin ASR benchmark and achieve a 23.66% character error rate (CER) with a 320 ms latency. Our online model yields as little as 0.19% absolute CER degradation compared with the offline baseline, and achieves significant improvement over our prior work on Long Short-Term Memory (LSTM) based online E2E models.