 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Streaming End-to-End ASR on Transformer-based Causal Models with Encoder States Revision Strategies
Paper and Code
Jul 06, 2022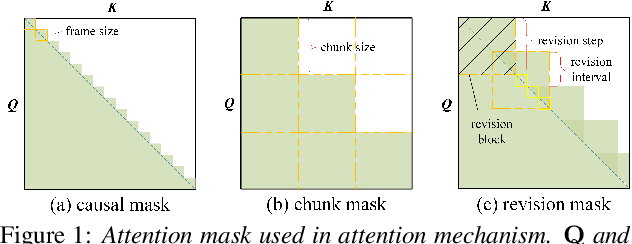
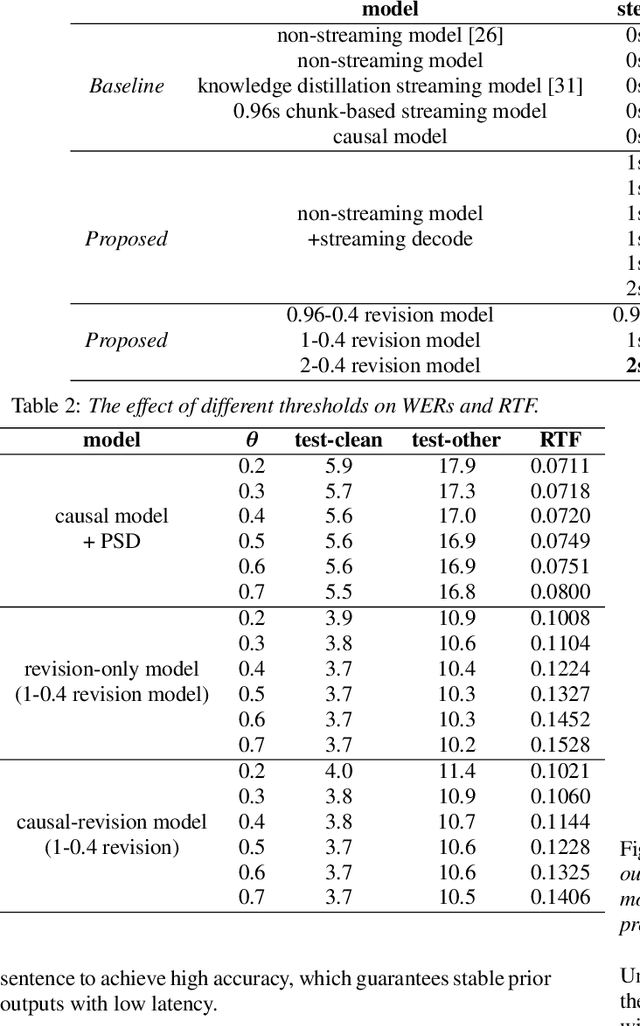
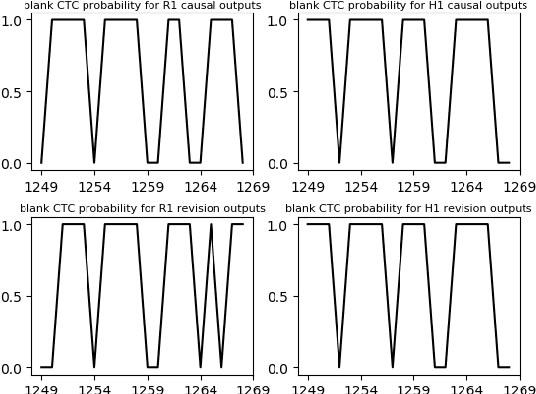
There is often a trade-off between performance and latency in streaming automatic speech recognition (ASR). Traditional methods such as look-ahead and chunk-based methods, usually require information from future frames to advance recognition accuracy, which incurs inevitable latency even if the computation is fast enough. A causal model that computes without any future frames can avoid this latency, but its performance is significantly worse than traditional methods. In this paper, we propose corresponding revision strategies to improve the causal model. Firstly, we introduce a real-time encoder states revision strategy to modify previous states. Encoder forward computation starts once the data is received and revises the previous encoder states after several frames, which is no need to wait for any right context. Furthermore, a CTC spike position alignment decoding algorithm is designed to reduce time costs brought by the revision strategy. Experiments are all conducted on Librispeech datasets. Fine-tuning on the CTC-based wav2vec2.0 model, our best method can achieve 3.7/9.2 WERs on test-clean/other sets, which is also competitive with the chunk-based methods and the knowledge distillation methods.