 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Spectral Calibration of Hyperspectral Images:Method, Dataset and Benchmark
Dec 19, 2024



Hyperspectral image (HSI) densely samples the world in both the space and frequency domain and therefore is more distinctive than RGB images. Usually, HSI needs to be calibrated to minimize the impact of various illumination conditions. The traditional way to calibrate HSI utilizes a physical reference, which involves manual operations, occlusions, and/or limits camera mobility. These limitations inspire this paper to automatically calibrate HSIs using a learning-based method. Towards this goal, a large-scale HSI calibration dataset is created, which has 765 high-quality HSI pairs covering diversified natural scenes and illuminations. The dataset is further expanded to 7650 pairs by combining with 10 different physically measured illuminations. A spectral illumination transformer (SIT) together with an illumination attention module is proposed. Extensive benchmarks demonstrate the SoTA performance of the proposed SIT. The benchmarks also indicate that low-light conditions are more challenging than normal conditions. The dataset and codes are available online:https://github.com/duranze/Automatic-spectral-calibration-of-HSI
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
Modeling Weather Uncertainty for Multi-weather Co-Presence Estimation
Mar 29, 2024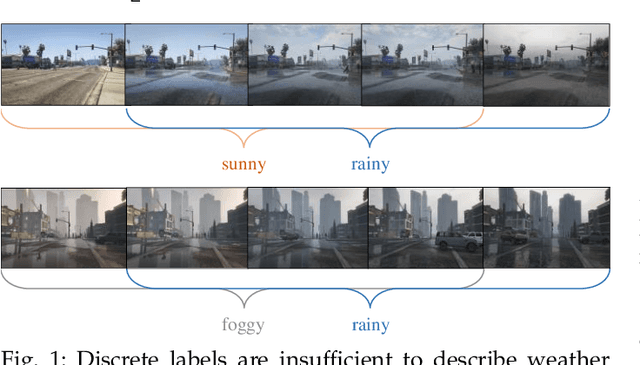
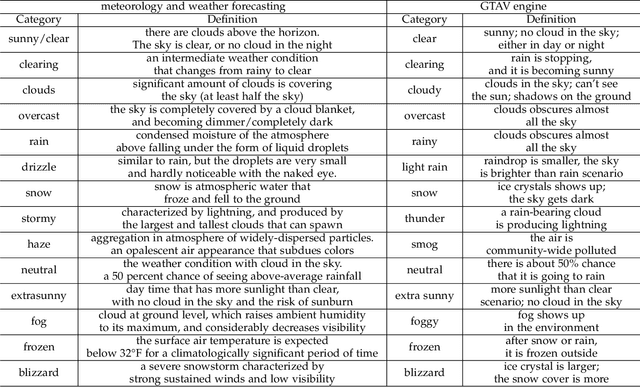
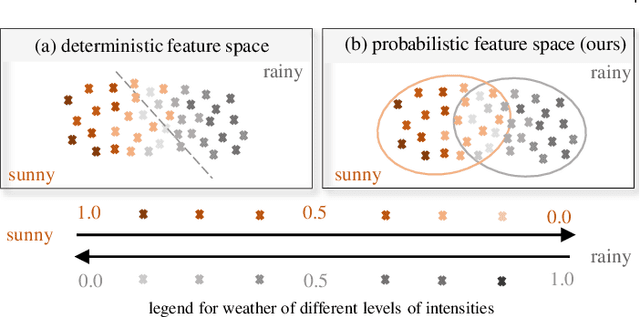
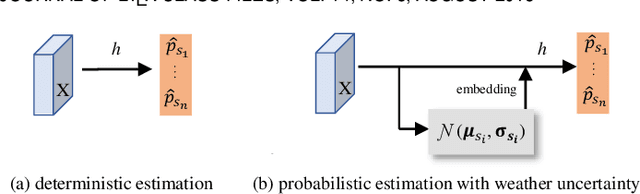
Images from outdoor scenes may be taken under various weather conditions. It is well studied that weather impacts the performance of computer vision algorithms and needs to be handled properly. However, existing algorithms model weather condition as a discrete status and estimate it using multi-label classification. The fact is that, physically, specifically in meteorology, weather are modeled as a continuous and transitional status. Instead of directly implementing hard classification as existing multi-weather classification methods do, we consider the physical formulation of multi-weather conditions and model the impact of physical-related parameter on learning from the image appearance. In this paper, we start with solid revisit of the physics definition of weather and how it can be described as a continuous machine learning and computer vision task. Namely, we propose to model the weather uncertainty, where the level of probability and co-existence of multiple weather conditions are both considered. A Gaussian mixture model is used to encapsulate the weather uncertainty and a uncertainty-aware multi-weather learning scheme is proposed based on prior-posterior learning. A novel multi-weather co-presence estimation transformer (MeFormer) is proposed. In addition, a new multi-weather co-presence estimation (MePe) dataset, along with 14 fine-grained weather categories and 16,078 samples, is proposed to benchmark both conventional multi-label weather classification task and multi-weather co-presence estimation task. Large scale experiments show that the proposed method achieves state-of-the-art performance and substantial generalization capabilities on both the conventional multi-label weather classification task and the proposed multi-weather co-presence estimation task. Besides, modeling weather uncertainty also benefits adverse-weather semantic segmentation.
Atlantis: Enabling Underwater Depth Estimation with Stable Diffusion
Dec 19, 2023
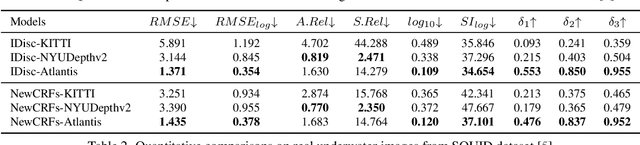
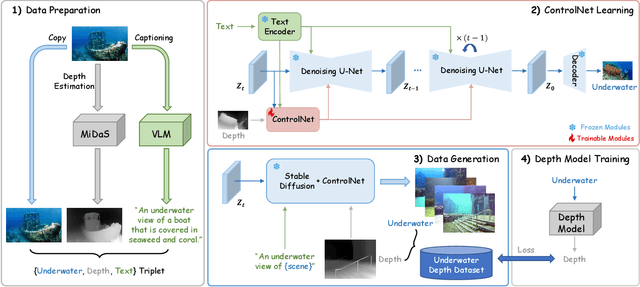
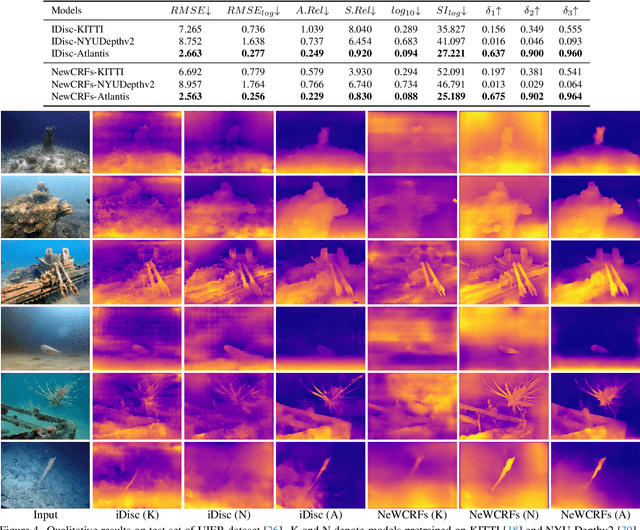
Monocular depth estimation has experienced significant progress on terrestrial images in recent years, largely due to deep learning advancements. However, it remains inadequate for underwater scenes, primarily because of data scarcity. Given the inherent challenges of light attenuation and backscattering in water, acquiring clear underwater images or precise depth information is notably difficult and costly. Consequently, learning-based approaches often rely on synthetic data or turn to unsupervised or self-supervised methods to mitigate this lack of data. Nonetheless, the performance of these methods is often constrained by the domain gap and looser constraints. In this paper, we propose a novel pipeline for generating photorealistic underwater images using accurate terrestrial depth data. This approach facilitates the training of supervised models for underwater depth estimation, effectively reducing the performance disparity between terrestrial and underwater environments. Contrary to prior synthetic datasets that merely apply style transfer to terrestrial images without altering the scene content, our approach uniquely creates vibrant, non-existent underwater scenes by leveraging terrestrial depth data through the innovative Stable Diffusion model. Specifically, we introduce a unique Depth2Underwater ControlNet, trained on specially prepared \{Underwater, Depth, Text\} data triplets, for this generation task. Our newly developed dataset enables terrestrial depth estimation models to achieve considerable improvements, both quantitatively and qualitatively, on unseen underwater images, surpassing their terrestrial pre-trained counterparts. Moreover, the enhanced depth accuracy for underwater scenes also aids underwater image restoration techniques that rely on depth maps, further demonstrating our dataset's utility. The dataset will be available at https://github.com/zkawfanx/Atlantis.
Exploring Different Levels of Supervision for Detecting and Localizing Solar Panels on Remote Sensing Imagery
Sep 19, 2023



This study investigates object presence detection and localization in remote sensing imagery, focusing on solar panel recognition. We explore different levels of supervision, evaluating three models: a fully supervised object detector, a weakly supervised image classifier with CAM-based localization, and a minimally supervised anomaly detector. The classifier excels in binary presence detection (0.79 F1-score), while the object detector (0.72) offers precise localization. The anomaly detector requires more data for viable performance. Fusion of model results shows potential accuracy gains. CAM impacts localization modestly, with GradCAM, GradCAM++, and HiResCAM yielding superior results. Notably, the classifier remains robust with less data, in contrast to the object detector.
Learning Content-enhanced Mask Transformer for Domain Generalized Urban-Scene Segmentation
Jul 01, 2023
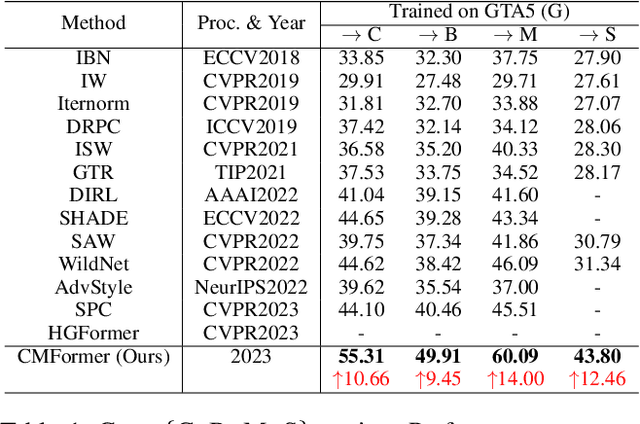

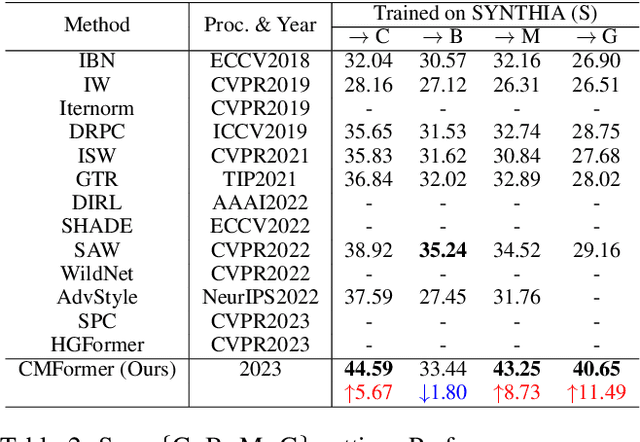
Domain-generalized urban-scene semantic segmentation (USSS) aims to learn generalized semantic predictions across diverse urban-scene styles. Unlike domain gap challenges, USSS is unique in that the semantic categories are often similar in different urban scenes, while the styles can vary significantly due to changes in urban landscapes, weather conditions, lighting, and other factors. Existing approaches typically rely on convolutional neural networks (CNNs) to learn the content of urban scenes. In this paper, we propose a Content-enhanced Mask TransFormer (CMFormer) for domain-generalized USSS. The main idea is to enhance the focus of the fundamental component, the mask attention mechanism, in Transformer segmentation models on content information. To achieve this, we introduce a novel content-enhanced mask attention mechanism. It learns mask queries from both the image feature and its down-sampled counterpart, as lower-resolution image features usually contain more robust content information and are less sensitive to style variations. These features are fused into a Transformer decoder and integrated into a multi-resolution content-enhanced mask attention learning scheme. Extensive experiments conducted on various domain-generalized urban-scene segmentation datasets demonstrate that the proposed CMFormer significantly outperforms existing CNN-based methods for domain-generalized semantic segmentation, achieving improvements of up to 14.00\% in terms of mIoU (mean intersection over union). The source code for CMFormer will be made available at this \href{https://github.com/BiQiWHU/domain-generalized-urban-scene-segmentation}{repository}.
GTAV-NightRain: Photometric Realistic Large-scale Dataset for Night-time Rain Streak Removal
Oct 10, 2022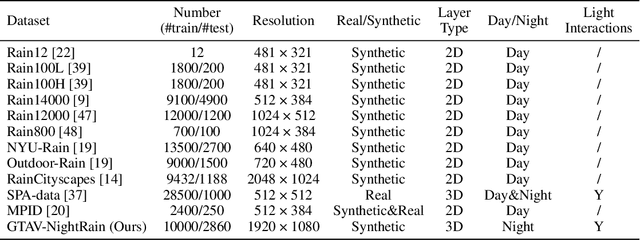

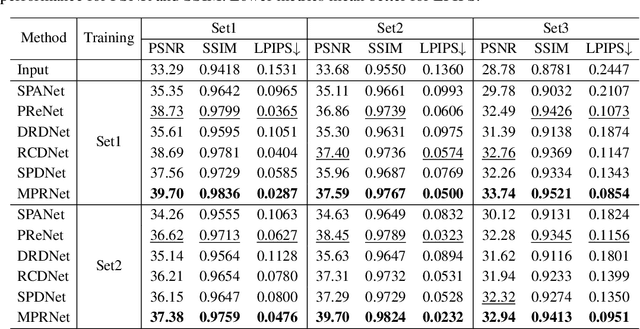

Rain is transparent, which reflects and refracts light in the scene to the camera. In outdoor vision, rain, especially rain streaks degrade visibility and therefore need to be removed. In existing rain streak removal datasets, although density, scale, direction and intensity have been considered, transparency is not fully taken into account. This problem is particularly serious in night scenes, where the appearance of rain largely depends on the interaction with scene illuminations and changes drastically on different positions within the image. This is problematic, because unrealistic dataset causes serious domain bias. In this paper, we propose GTAV-NightRain dataset, which is a large-scale synthetic night-time rain streak removal dataset. Unlike existing datasets, by using 3D computer graphic platform (namely GTA V), we are allowed to infer the three dimensional interaction between rain and illuminations, which insures the photometric realness. Current release of the dataset contains 12,860 HD rainy images and 1,286 corresponding HD ground truth images in diversified night scenes. A systematic benchmark and analysis are provided along with the dataset to inspire further research.
Multitask AET with Orthogonal Tangent Regularity for Dark Object Detection
May 06, 2022

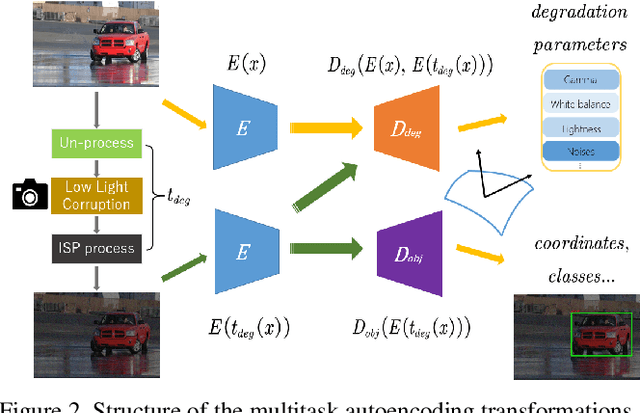

Dark environment becomes a challenge for computer vision algorithms owing to insufficient photons and undesirable noise. To enhance object detection in a dark environment, we propose a novel multitask auto encoding transformation (MAET) model which is able to explore the intrinsic pattern behind illumination translation. In a self-supervision manner, the MAET learns the intrinsic visual structure by encoding and decoding the realistic illumination-degrading transformation considering the physical noise model and image signal processing (ISP). Based on this representation, we achieve the object detection task by decoding the bounding box coordinates and classes. To avoid the over-entanglement of two tasks, our MAET disentangles the object and degrading features by imposing an orthogonal tangent regularity. This forms a parametric manifold along which multitask predictions can be geometrically formulated by maximizing the orthogonality between the tangents along the outputs of respective tasks. Our framework can be implemented based on the mainstream object detection architecture and directly trained end-to-end using normal target detection datasets, such as VOC and COCO. We have achieved the state-of-the-art performance using synthetic and real-world datasets. Code is available at https://github.com/cuiziteng/MAET.
Finding a Needle in a Haystack: Tiny Flying Object Detection in 4K Videos using a Joint Detection-and-Tracking Approach
May 18, 2021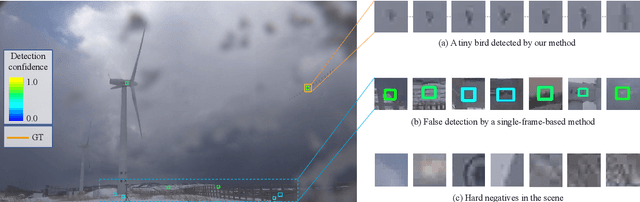
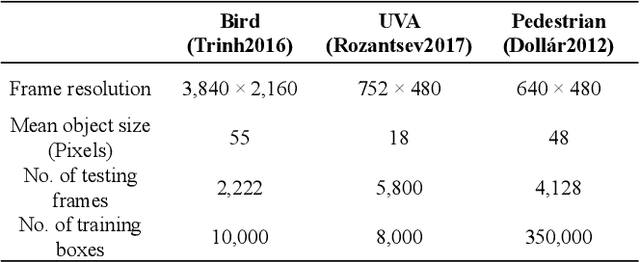

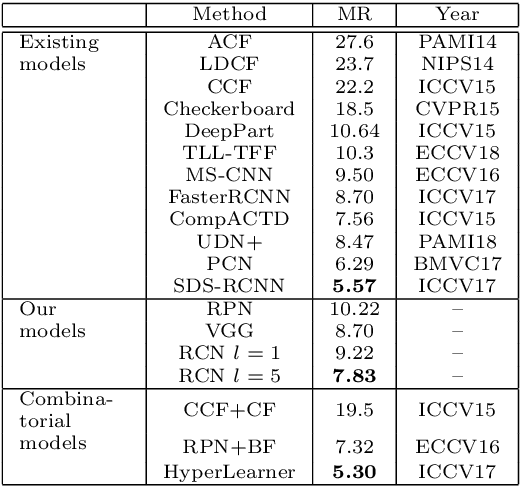
Detecting tiny objects in a high-resolution video is challenging because the visual information is little and unreliable. Specifically, the challenge includes very low resolution of the objects, MPEG artifacts due to compression and a large searching area with many hard negatives. Tracking is equally difficult because of the unreliable appearance, and the unreliable motion estimation. Luckily, we found that by combining this two challenging tasks together, there will be mutual benefits. Following the idea, in this paper, we present a neural network model called the Recurrent Correlational Network, where detection and tracking are jointly performed over a multi-frame representation learned through a single, trainable, and end-to-end network. The framework exploits a convolutional long short-term memory network for learning informative appearance changes for detection, while the learned representation is shared in tracking for enhancing its performance. In experiments with datasets containing images of scenes with small flying objects, such as birds and unmanned aerial vehicles, the proposed method yielded consistent improvements in detection performance over deep single-frame detectors and existing motion-based detectors. Furthermore, our network performs as well as state-of-the-art generic object trackers when it was evaluated as a tracker on a bird image dataset.
Hyperspectral Image Semantic Segmentation in Cityscapes
Dec 18, 2020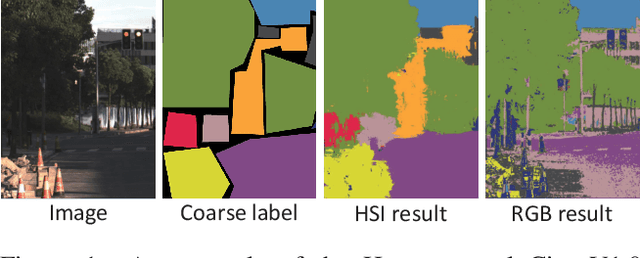



High-resolution hyperspectral images (HSIs) contain the response of each pixel in different spectral bands, which can be used to effectively distinguish various objects in complex scenes. While HSI cameras have become low cost, algorithms based on it has not been well exploited. In this paper, we focus on a novel topic, semi-supervised semantic segmentation in cityscapes using HSIs.It is based on the idea that high-resolution HSIs in city scenes contain rich spectral information, which can be easily associated to semantics without manual labeling. Therefore, it enables low cost, highly reliable semantic segmentation in complex scenes.Specifically, in this paper, we introduce a semi-supervised HSI semantic segmentation network, which utilizes spectral information to improve the coarse labels to a finer degree.The experimental results show that our method can obtain highly competitive labels and even have higher edge fineness than artificial fine labels in some classes. At the same time, the results also show that the optimized labels can effectively improve the effect of semantic segmentation. The combination of HSIs and semantic segmentation proves that HSIs have great potential in high-level visual tasks.