 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOscillating Dispersion for Maximal Light-throughput Spectral Imaging
Mar 16, 2026Existing computational spectral imaging systems typically rely on coded aperture and beam splitters that block a substantial fraction of incident light, degrading reconstruction quality under light-starved conditions. To address this limitation, we develop the Oscillating Dispersion Imaging Spectrometer (ODIS), which for the first time achieves near-full light throughput by axially translating a disperser between the conjugate image plane and a defocused position, sequentially capturing a panchromatic (PAN) image and a dispersed measurement along a single optical path. We further propose a PAN-guided Dispersion-Aware Deep Unfolding Network (PDAUN) that recovers high-fidelity spectral information from maskless dispersion under PAN structural guidance. Its data-fidelity step derives an FFT-Woodbury preconditioned solver by exploiting the cyclic-convolution property of the ODIS forward model, while a Dispersion-Aware Deformable Convolution module (DADC) corrects sub-pixel spectral misalignment using PAN features. Experiments show state-of-the-art performance on standard benchmarks, and cross-system comparisons confirm that ODIS yields decisive gains under low illumination. High-fidelity reconstruction is validated on a physical prototype.
Exploring Spatiotemporal Feature Propagation for Video-Level Compressive Spectral Reconstruction: Dataset, Model and Benchmark
Feb 28, 2026Recently, Spectral Compressive Imaging (SCI) has achieved remarkable success, unlocking significant potential for dynamic spectral vision. However, existing reconstruction methods, primarily image-based, suffer from two limitations: (i) Encoding process masks spatial-spectral features, leading to uncertainty in reconstructing missing information from single compressed measurements, and (ii) The frame-by-frame reconstruction paradigm fails to ensure temporal consistency, which is crucial in the video perception. To address these challenges, this paper seeks to advance spectral reconstruction from the image level to the video level, leveraging the complementary features and temporal continuity across adjacent frames in dynamic scenes. Initially, we construct the first high-quality dynamic hyperspectral image dataset (DynaSpec), comprising 30 sequences obtained through frame-scanning acquisition. Subsequently, we propose the Propagation-Guided Spectral Video Reconstruction Transformer (PG-SVRT), which employs a spatial-then-temporal attention to effectively reconstruct spectral features from abundant video information, while using a bridged token to reduce computational complexity. Finally, we conduct simulation experiments to assess the performance of four SCI systems, and construct a DD-CASSI prototype for real-world data collection and benchmarking. Extensive experiments demonstrate that PG-SVRT achieves superior performance in reconstruction quality, spectral fidelity, and temporal consistency, while maintaining minimal FLOPs. Project page: https://github.com/nju-cite/DynaSpec
Split-Layer: Enhancing Implicit Neural Representation by Maximizing the Dimensionality of Feature Space
Nov 13, 2025Implicit neural representation (INR) models signals as continuous functions using neural networks, offering efficient and differentiable optimization for inverse problems across diverse disciplines. However, the representational capacity of INR defined by the range of functions the neural network can characterize, is inherently limited by the low-dimensional feature space in conventional multilayer perceptron (MLP) architectures. While widening the MLP can linearly increase feature space dimensionality, it also leads to a quadratic growth in computational and memory costs. To address this limitation, we propose the split-layer, a novel reformulation of MLP construction. The split-layer divides each layer into multiple parallel branches and integrates their outputs via Hadamard product, effectively constructing a high-degree polynomial space. This approach significantly enhances INR's representational capacity by expanding the feature space dimensionality without incurring prohibitive computational overhead. Extensive experiments demonstrate that the split-layer substantially improves INR performance, surpassing existing methods across multiple tasks, including 2D image fitting, 2D CT reconstruction, 3D shape representation, and 5D novel view synthesis.
Hierarchical Spatial-Frequency Aggregation for Spectral Deconvolution Imaging
Nov 10, 2025Computational spectral imaging (CSI) achieves real-time hyperspectral imaging through co-designed optics and algorithms, but typical CSI methods suffer from a bulky footprint and limited fidelity. Therefore, Spectral Deconvolution imaging (SDI) methods based on PSF engineering have been proposed to achieve high-fidelity compact CSI design recently. However, the composite convolution-integration operations of SDI render the normal-equation coefficient matrix scene-dependent, which hampers the efficient exploitation of imaging priors and poses challenges for accurate reconstruction. To tackle the inherent data-dependent operators in SDI, we introduce a Hierarchical Spatial-Spectral Aggregation Unfolding Framework (HSFAUF). By decomposing subproblems and projecting them into the frequency domain, HSFAUF transforms nonlinear processes into linear mappings, thereby enabling efficient solutions. Furthermore, to integrate spatial-spectral priors during iterative refinement, we propose a Spatial-Frequency Aggregation Transformer (SFAT), which explicitly aggregates information across spatial and frequency domains. By integrating SFAT into HSFAUF, we develop a Transformer-based deep unfolding method, \textbf{H}ierarchical \textbf{S}patial-\textbf{F}requency \textbf{A}ggregation \textbf{U}nfolding \textbf{T}ransformer (HSFAUT), to solve the inverse problem of SDI. Systematic simulated and real experiments show that HSFAUT surpasses SOTA methods with cheaper memory and computational costs, while exhibiting optimal performance on different SDI systems.
Explore Spatio-temporal Aggregation for Insubstantial Object Detection: Benchmark Dataset and Baseline
Jun 23, 2022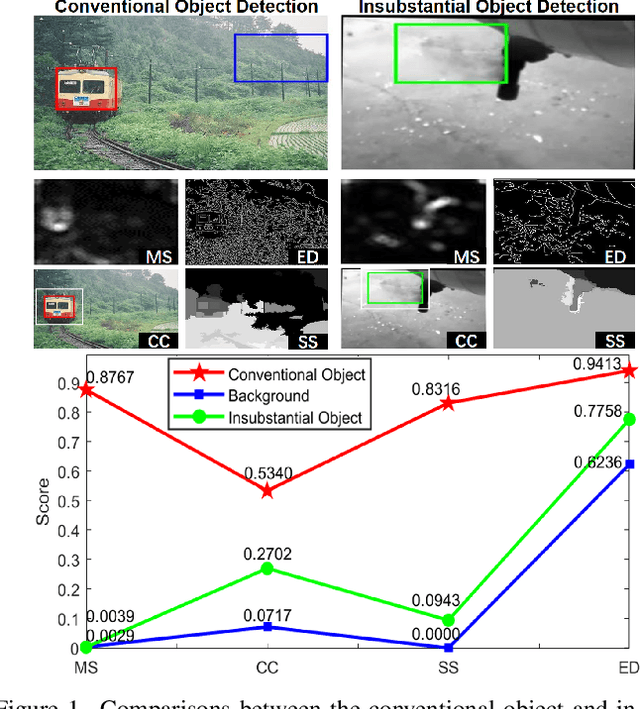
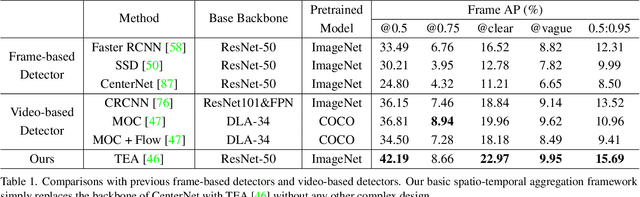
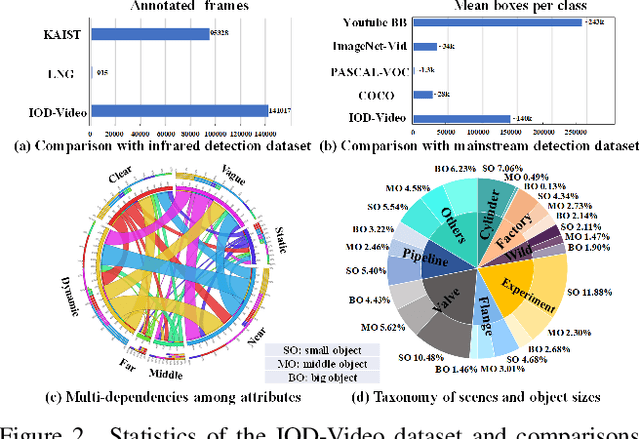
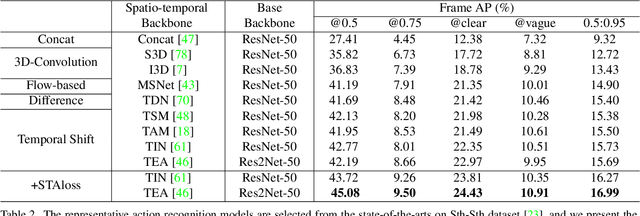
We endeavor on a rarely explored task named Insubstantial Object Detection (IOD), which aims to localize the object with following characteristics: (1) amorphous shape with indistinct boundary; (2) similarity to surroundings; (3) absence in color. Accordingly, it is far more challenging to distinguish insubstantial objects in a single static frame and the collaborative representation of spatial and temporal information is crucial. Thus, we construct an IOD-Video dataset comprised of 600 videos (141,017 frames) covering various distances, sizes, visibility, and scenes captured by different spectral ranges. In addition, we develop a spatio-temporal aggregation framework for IOD, in which different backbones are deployed and a spatio-temporal aggregation loss (STAloss) is elaborately designed to leverage the consistency along the time axis. Experiments conducted on IOD-Video dataset demonstrate that spatio-temporal aggregation can significantly improve the performance of IOD. We hope our work will attract further researches into this valuable yet challenging task. The code will be available at: \url{https://github.com/CalayZhou/IOD-Video}.
Hyperspectral Image Semantic Segmentation in Cityscapes
Dec 18, 2020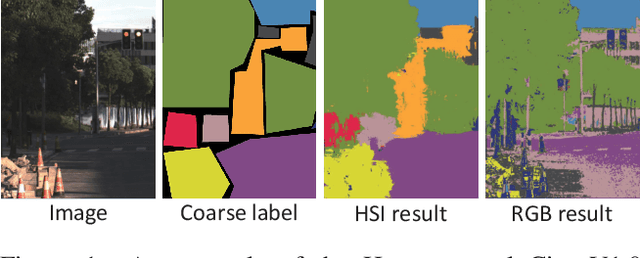



High-resolution hyperspectral images (HSIs) contain the response of each pixel in different spectral bands, which can be used to effectively distinguish various objects in complex scenes. While HSI cameras have become low cost, algorithms based on it has not been well exploited. In this paper, we focus on a novel topic, semi-supervised semantic segmentation in cityscapes using HSIs.It is based on the idea that high-resolution HSIs in city scenes contain rich spectral information, which can be easily associated to semantics without manual labeling. Therefore, it enables low cost, highly reliable semantic segmentation in complex scenes.Specifically, in this paper, we introduce a semi-supervised HSI semantic segmentation network, which utilizes spectral information to improve the coarse labels to a finer degree.The experimental results show that our method can obtain highly competitive labels and even have higher edge fineness than artificial fine labels in some classes. At the same time, the results also show that the optimized labels can effectively improve the effect of semantic segmentation. The combination of HSIs and semantic segmentation proves that HSIs have great potential in high-level visual tasks.
Improving Multispectral Pedestrian Detection by Addressing Modality Imbalance Problems
Aug 17, 2020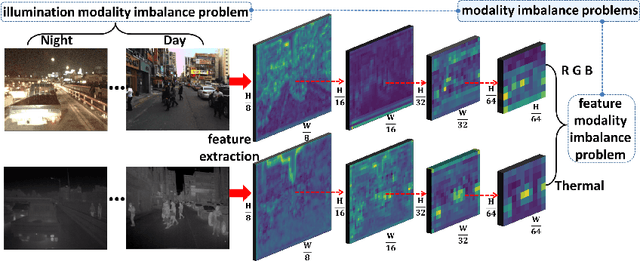
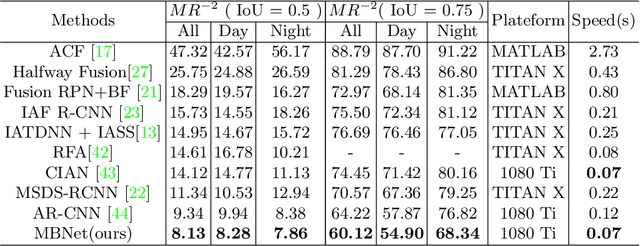
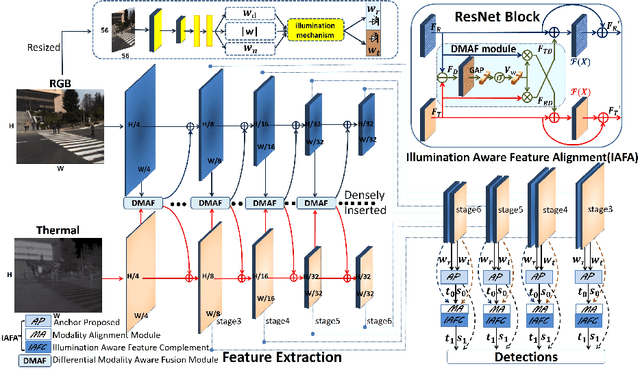
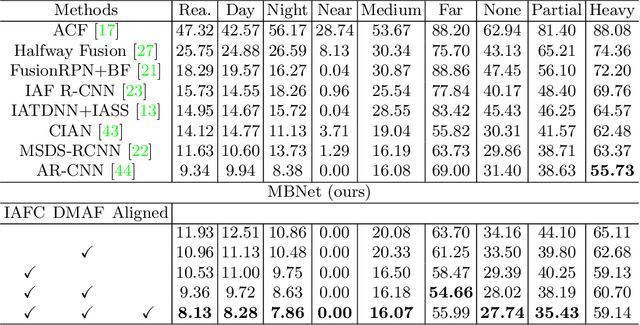
Multispectral pedestrian detection is capable of adapting to insufficient illumination conditions by leveraging color-thermal modalities. On the other hand, it is still lacking of in-depth insights on how to fuse the two modalities effectively. Compared with traditional pedestrian detection, we find multispectral pedestrian detection suffers from modality imbalance problems which will hinder the optimization process of dual-modality network and depress the performance of detector. Inspired by this observation, we propose Modality Balance Network (MBNet) which facilitates the optimization process in a much more flexible and balanced manner. Firstly, we design a novel Differential Modality Aware Fusion (DMAF) module to make the two modalities complement each other. Secondly, an illumination aware feature alignment module selects complementary features according to the illumination conditions and aligns the two modality features adaptively. Extensive experimental results demonstrate MBNet outperforms the state-of-the-arts on both the challenging KAIST and CVC-14 multispectral pedestrian datasets in terms of the accuracy and the computational efficiency. Code is available at https://github.com/CalayZhou/MBNet.
Multispectral Image Intrinsic Decomposition via Low Rank Constraint
Feb 24, 2018
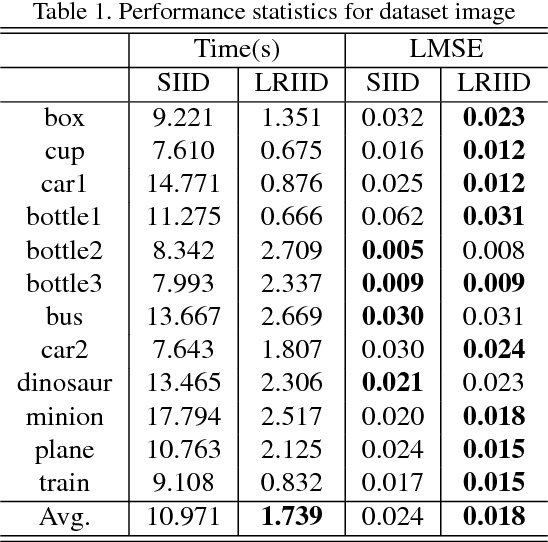
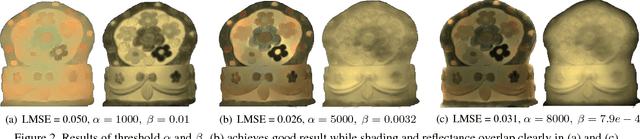
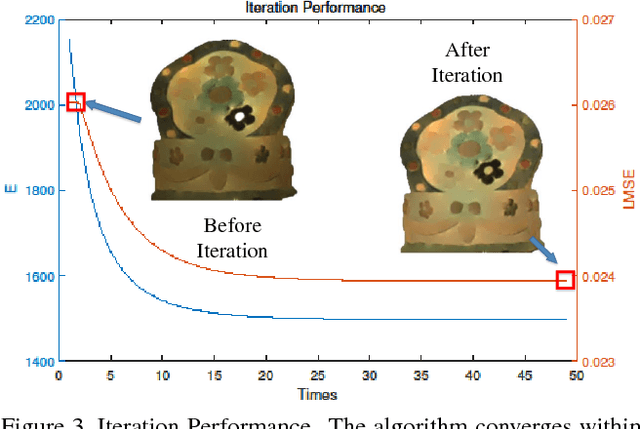
Multispectral images contain many clues of surface characteristics of the objects, thus can be widely used in many computer vision tasks, e.g., recolorization and segmentation. However, due to the complex illumination and the geometry structure of natural scenes, the spectra curves of a same surface can look very different. In this paper, a Low Rank Multispectral Image Intrinsic Decomposition model (LRIID) is presented to decompose the shading and reflectance from a single multispectral image. We extend the Retinex model, which is proposed for RGB image intrinsic decomposition, for multispectral domain. Based on this, a low rank constraint is proposed to reduce the ill-posedness of the problem and make the algorithm solvable. A dataset of 12 images is given with the ground truth of shadings and reflectance, so that the objective evaluations can be conducted. The experiments demonstrate the effectiveness of proposed method.