 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDM-ASR: Diarization-aware Multi-speaker ASR with Large Language Models
Apr 24, 2026Multi-speaker automatic speech recognition (ASR) aims to transcribe conversational speech involving multiple speakers, requiring the model to capture not only what was said, but also who said it and sometimes when it was spoken. Recent Speech-LLM approaches have shown the potential of unified modeling for this task, but jointly learning speaker attribution, temporal structure, and lexical recognition remains difficult and data-intensive. At the current stage, leveraging reliable speaker diarization as an explicit structural prior provides a practical and efficient way to simplify this task. To effectively exploit such priors, we propose DM-ASR, a diarization-aware multi-speaker ASR framework that reformulates the task as a multi-turn dialogue generation process. Given an audio chunk and diarization results, DM-ASR decomposes transcription into a sequence of speaker- and time-conditioned queries, each corresponding to one speaker in one time segment. This formulation converts multi-speaker recognition into a series of structured sub-tasks, explicitly decoupling speaker-temporal structure from linguistic content and enabling effective integration of diarization cues with the reasoning capability of large language models. We further introduce an optional word-level timestamp prediction mechanism that interleaves word and timestamp tokens, yielding richer structured outputs and better transcription quality. Our analysis shows that diarization systems provide more reliable speaker identities and segment-level boundaries, while LLMs excel at modeling linguistic content and long-range dependencies, demonstrating their complementary strengths. Experiments on Mandarin and English benchmarks show that the proposed approach achieves strong performance with relatively small models and training data, while remaining competitive with or outperforming existing unified approaches.
TEA-PSE 3.0: Tencent-Ethereal-Audio-Lab Personalized Speech Enhancement System For ICASSP 2023 DNS Challenge
Mar 14, 2023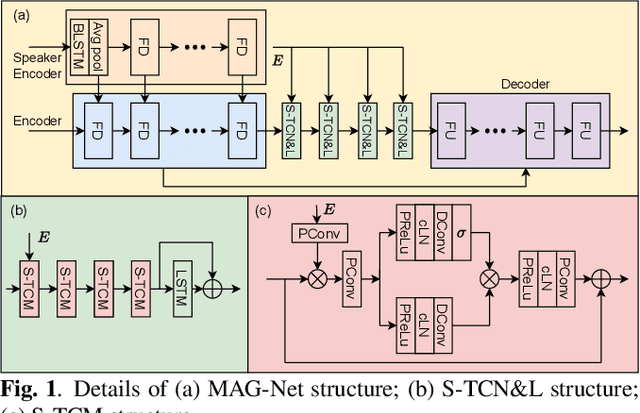


This paper introduces the Unbeatable Team's submission to the ICASSP 2023 Deep Noise Suppression (DNS) Challenge. We expand our previous work, TEA-PSE, to its upgraded version -- TEA-PSE 3.0. Specifically, TEA-PSE 3.0 incorporates a residual LSTM after squeezed temporal convolution network (S-TCN) to enhance sequence modeling capabilities. Additionally, the local-global representation (LGR) structure is introduced to boost speaker information extraction, and multi-STFT resolution loss is used to effectively capture the time-frequency characteristics of the speech signals. Moreover, retraining methods are employed based on the freeze training strategy to fine-tune the system. According to the official results, TEA-PSE 3.0 ranks 1st in both ICASSP 2023 DNS-Challenge track 1 and track 2.
spatial-dccrn: dccrn equipped with frame-level angle feature and hybrid filtering for multi-channel speech enhancement
Oct 17, 2022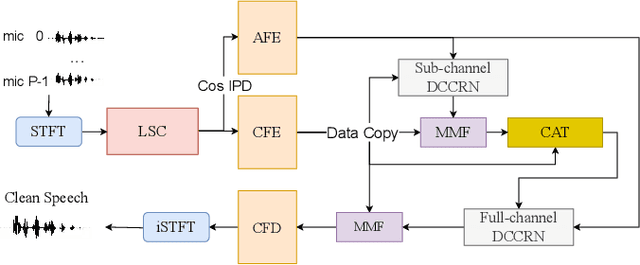
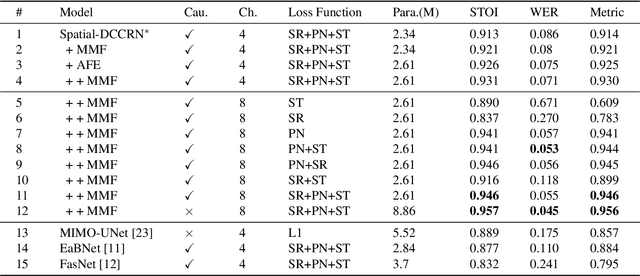
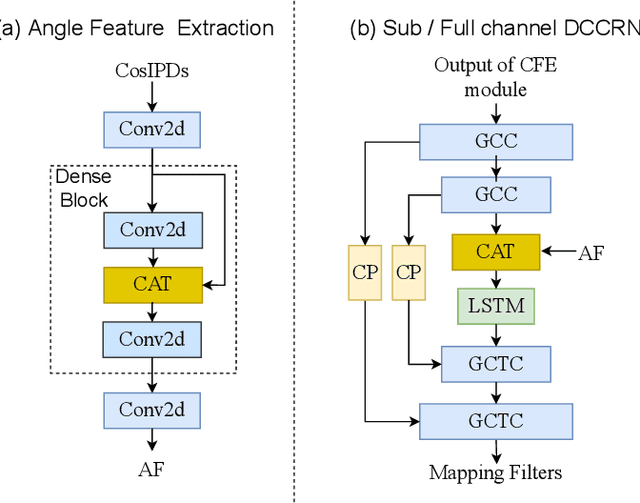
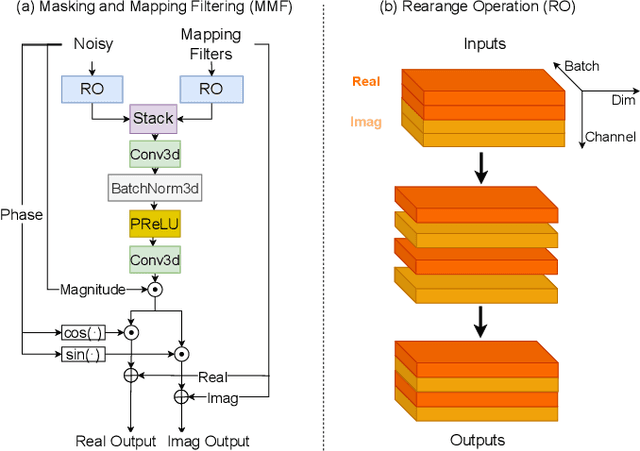
Recently, multi-channel speech enhancement has drawn much interest due to the use of spatial information to distinguish target speech from interfering signal. To make full use of spatial information and neural network based masking estimation, we propose a multi-channel denoising neural network -- Spatial DCCRN. Firstly, we extend S-DCCRN to multi-channel scenario, aiming at performing cascaded sub-channel and full-channel processing strategy, which can model different channels separately. Moreover, instead of only adopting multi-channel spectrum or concatenating first-channel's magnitude and IPD as the model's inputs, we apply an angle feature extraction module (AFE) to extract frame-level angle feature embeddings, which can help the model to apparently perceive spatial information. Finally, since the phenomenon of residual noise will be more serious when the noise and speech exist in the same time frequency (TF) bin, we particularly design a masking and mapping filtering method to substitute the traditional filter-and-sum operation, with the purpose of cascading coarsely denoising, dereverberation and residual noise suppression. The proposed model, Spatial-DCCRN, has surpassed EaBNet, FasNet as well as several competitive models on the L3DAS22 Challenge dataset. Not only the 3D scenario, Spatial-DCCRN outperforms state-of-the-art (SOTA) model MIMO-UNet by a large margin in multiple evaluation metrics on the multi-channel ConferencingSpeech2021 Challenge dataset. Ablation studies also demonstrate the effectiveness of different contributions.
Multispectral Image Intrinsic Decomposition via Low Rank Constraint
Feb 24, 2018
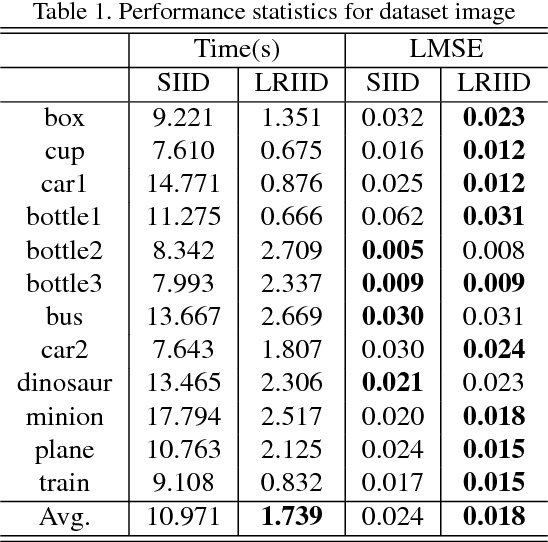
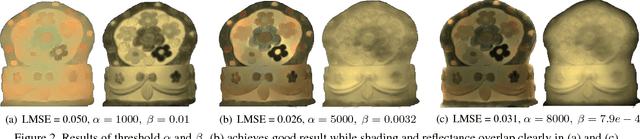
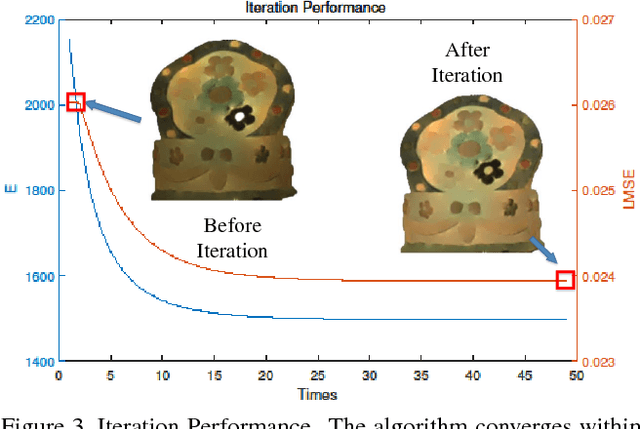
Multispectral images contain many clues of surface characteristics of the objects, thus can be widely used in many computer vision tasks, e.g., recolorization and segmentation. However, due to the complex illumination and the geometry structure of natural scenes, the spectra curves of a same surface can look very different. In this paper, a Low Rank Multispectral Image Intrinsic Decomposition model (LRIID) is presented to decompose the shading and reflectance from a single multispectral image. We extend the Retinex model, which is proposed for RGB image intrinsic decomposition, for multispectral domain. Based on this, a low rank constraint is proposed to reduce the ill-posedness of the problem and make the algorithm solvable. A dataset of 12 images is given with the ground truth of shadings and reflectance, so that the objective evaluations can be conducted. The experiments demonstrate the effectiveness of proposed method.