 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgespatial-dccrn: dccrn equipped with frame-level angle feature and hybrid filtering for multi-channel speech enhancement
Oct 17, 2022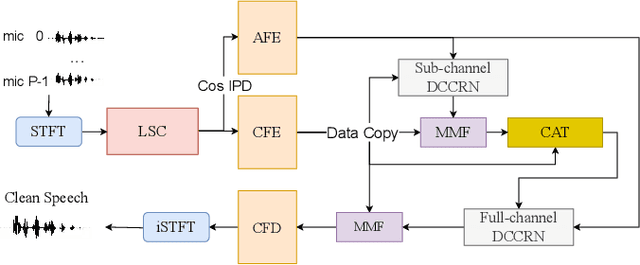
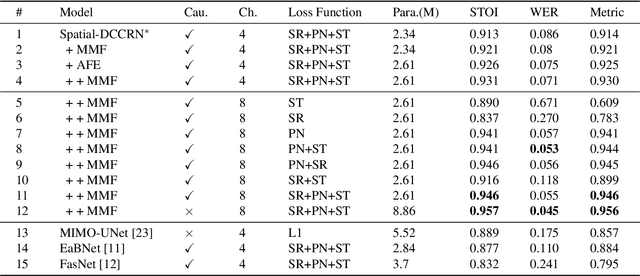
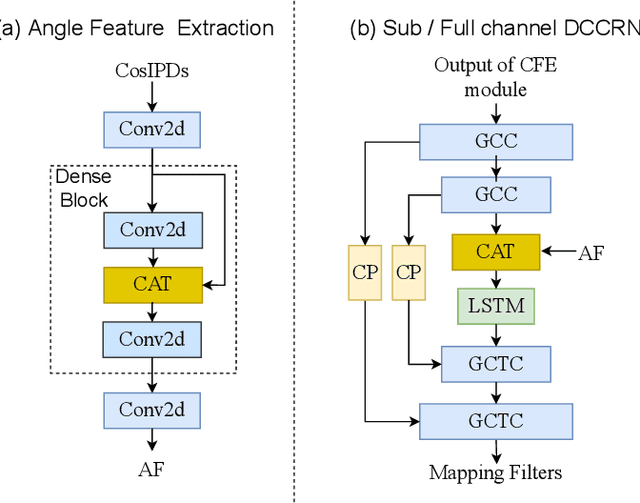
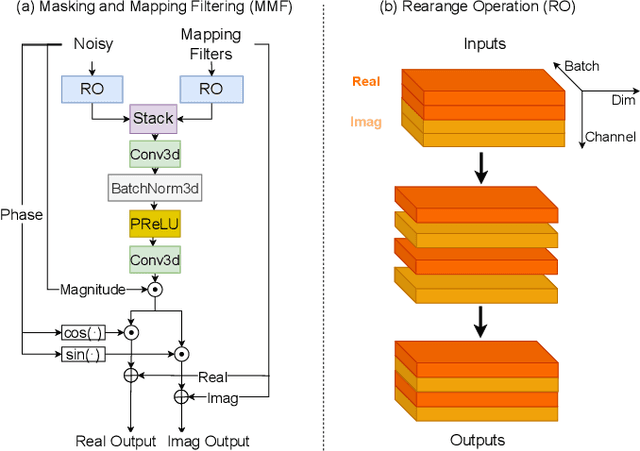
Recently, multi-channel speech enhancement has drawn much interest due to the use of spatial information to distinguish target speech from interfering signal. To make full use of spatial information and neural network based masking estimation, we propose a multi-channel denoising neural network -- Spatial DCCRN. Firstly, we extend S-DCCRN to multi-channel scenario, aiming at performing cascaded sub-channel and full-channel processing strategy, which can model different channels separately. Moreover, instead of only adopting multi-channel spectrum or concatenating first-channel's magnitude and IPD as the model's inputs, we apply an angle feature extraction module (AFE) to extract frame-level angle feature embeddings, which can help the model to apparently perceive spatial information. Finally, since the phenomenon of residual noise will be more serious when the noise and speech exist in the same time frequency (TF) bin, we particularly design a masking and mapping filtering method to substitute the traditional filter-and-sum operation, with the purpose of cascading coarsely denoising, dereverberation and residual noise suppression. The proposed model, Spatial-DCCRN, has surpassed EaBNet, FasNet as well as several competitive models on the L3DAS22 Challenge dataset. Not only the 3D scenario, Spatial-DCCRN outperforms state-of-the-art (SOTA) model MIMO-UNet by a large margin in multiple evaluation metrics on the multi-channel ConferencingSpeech2021 Challenge dataset. Ablation studies also demonstrate the effectiveness of different contributions.
Uformer: A Unet based dilated complex & real dual-path conformer network for simultaneous speech enhancement and dereverberation
Nov 11, 2021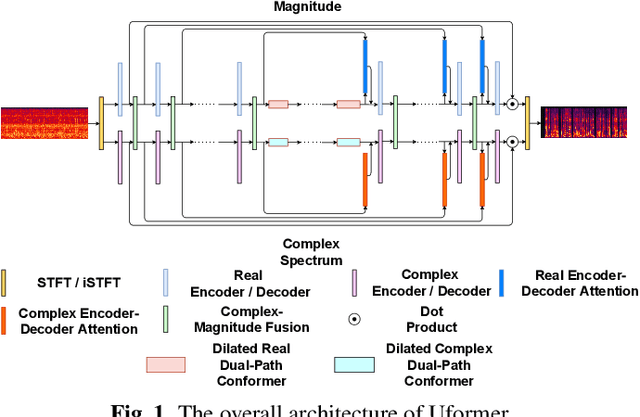
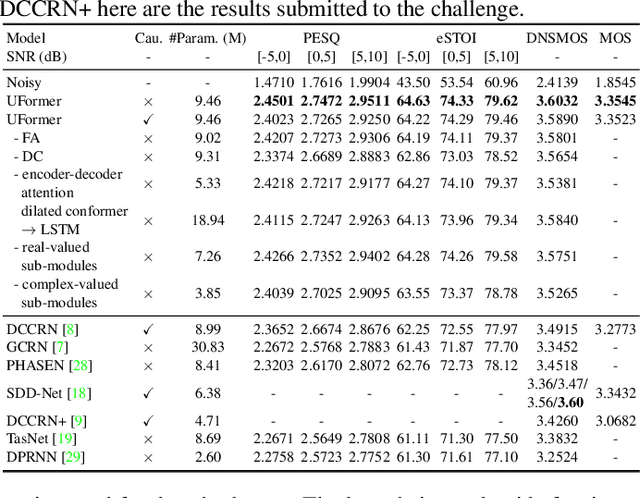
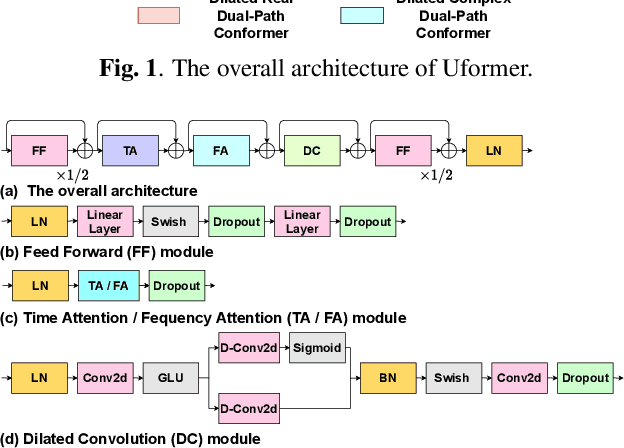
Complex spectrum and magnitude are considered as two major features of speech enhancement and dereverberation. Traditional approaches always treat these two features separately, ignoring their underlying relationship. In this paper, we proposem Uformer, a Unet based dilated complex & real dual-path conformer network in both complex and magnitude domain for simultaneous speech enhancement and dereverberation. We exploit time attention (TA) and dilated convolution (DC) to leverage local and global contextual information and frequency attention (FA) to model dimensional information. These three sub-modules contained in the proposed dilated complex & real dual-path conformer module effectively improve the speech enhancement and dereverberation performance. Furthermore, hybrid encoder and decoder are adopted to simultaneously model the complex spectrum and magnitude and promote the information interaction between two domains. Encoder decoder attention is also applied to enhance the interaction between encoder and decoder. Our experimental results outperform all SOTA time and complex domain models objectively and subjectively. Specifically, Uformer reaches 3.6032 DNSMOS on the blind test set of Interspeech 2021 DNS Challenge, which outperforms all top-performed models. We also carry out ablation experiments to tease apart all proposed sub-modules that are most important.
AISHELL-4: An Open Source Dataset for Speech Enhancement, Separation, Recognition and Speaker Diarization in Conference Scenario
Apr 08, 2021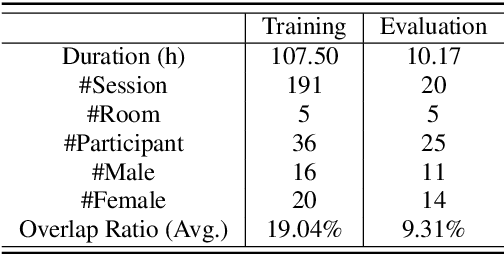
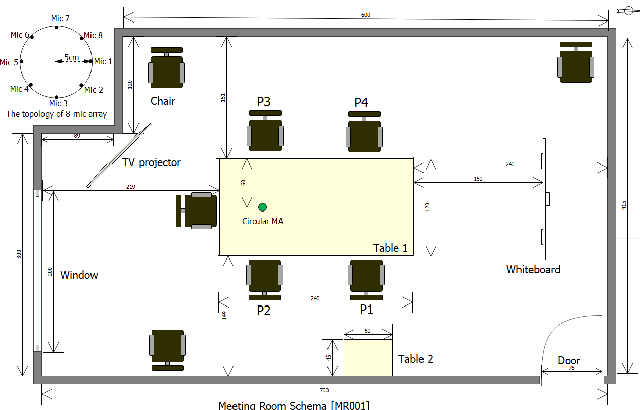

In this paper, we present AISHELL-4, a sizable real-recorded Mandarin speech dataset collected by 8-channel circular microphone array for speech processing in conference scenario. The dataset consists of 211 recorded meeting sessions, each containing 4 to 8 speakers, with a total length of 118 hours. This dataset aims to bride the advanced research on multi-speaker processing and the practical application scenario in three aspects. With real recorded meetings, AISHELL-4 provides realistic acoustics and rich natural speech characteristics in conversation such as short pause, speech overlap, quick speaker turn, noise, etc. Meanwhile, the accurate transcription and speaker voice activity are provided for each meeting in AISHELL-4. This allows the researchers to explore different aspects in meeting processing, ranging from individual tasks such as speech front-end processing, speech recognition and speaker diarization, to multi-modality modeling and joint optimization of relevant tasks. Given most open source dataset for multi-speaker tasks are in English, AISHELL-4 is the only Mandarin dataset for conversation speech, providing additional value for data diversity in speech community.