 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCCRN+: Channel-wise Subband DCCRN with SNR Estimation for Speech Enhancement
Jun 16, 2021
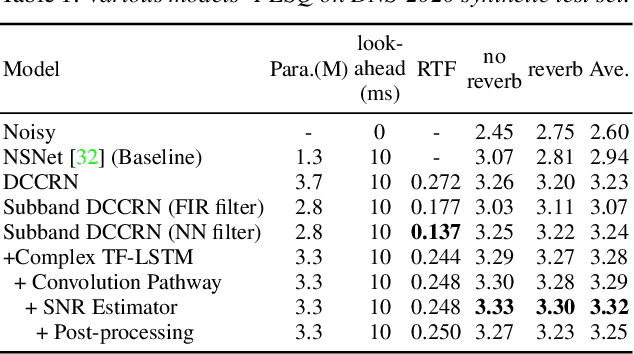
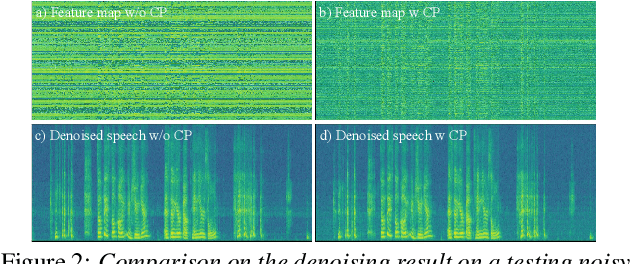

Deep complex convolution recurrent network (DCCRN), which extends CRN with complex structure, has achieved superior performance in MOS evaluation in Interspeech 2020 deep noise suppression challenge (DNS2020). This paper further extends DCCRN with the following significant revisions. We first extend the model to sub-band processing where the bands are split and merged by learnable neural network filters instead of engineered FIR filters, leading to a faster noise suppressor trained in an end-to-end manner. Then the LSTM is further substituted with a complex TF-LSTM to better model temporal dependencies along both time and frequency axes. Moreover, instead of simply concatenating the output of each encoder layer to the input of the corresponding decoder layer, we use convolution blocks to first aggregate essential information from the encoder output before feeding it to the decoder layers. We specifically formulate the decoder with an extra a priori SNR estimation module to maintain good speech quality while removing noise. Finally a post-processing module is adopted to further suppress the unnatural residual noise. The new model, named DCCRN+, has surpassed the original DCCRN as well as several competitive models in terms of PESQ and DNSMOS, and has achieved superior performance in the new Interspeech 2021 DNS challenge
F-T-LSTM based Complex Network for Joint Acoustic Echo Cancellation and Speech Enhancement
Jun 16, 2021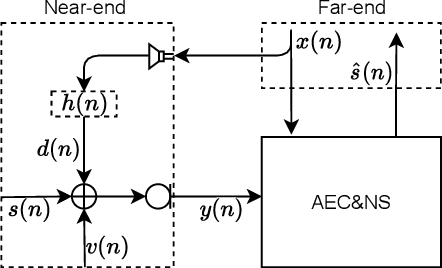
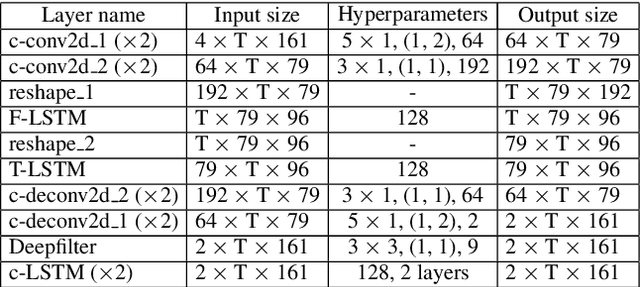
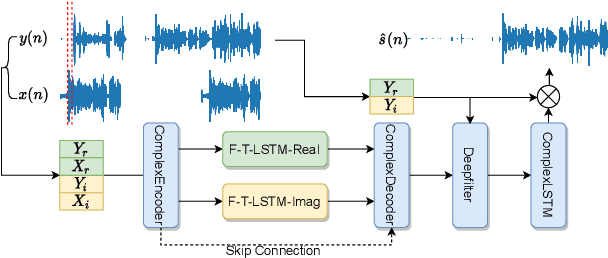
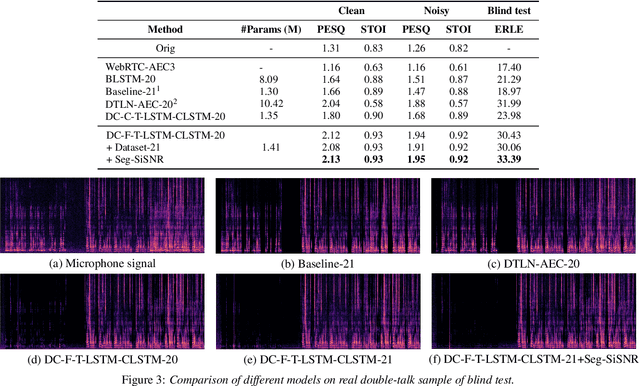
With the increasing demand for audio communication and online conference, ensuring the robustness of Acoustic Echo Cancellation (AEC) under the complicated acoustic scenario including noise, reverberation and nonlinear distortion has become a top issue. Although there have been some traditional methods that consider nonlinear distortion, they are still inefficient for echo suppression and the performance will be attenuated when noise is present. In this paper, we present a real-time AEC approach using complex neural network to better modeling the important phase information and frequency-time-LSTMs (F-T-LSTM), which scan both frequency and time axis, for better temporal modeling. Moreover, we utilize modified SI-SNR as cost function to make the model to have better echo cancellation and noise suppression (NS) performance. With only 1.4M parameters, the proposed approach outperforms the AEC-challenge baseline by 0.27 in terms of Mean Opinion Score (MOS).
AISHELL-4: An Open Source Dataset for Speech Enhancement, Separation, Recognition and Speaker Diarization in Conference Scenario
Apr 08, 2021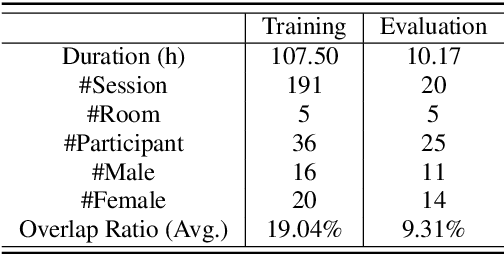
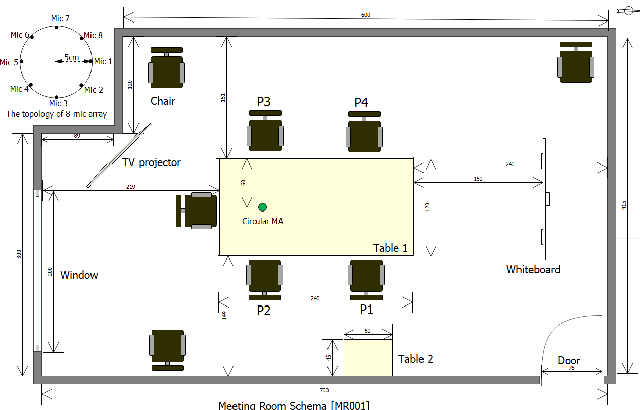

In this paper, we present AISHELL-4, a sizable real-recorded Mandarin speech dataset collected by 8-channel circular microphone array for speech processing in conference scenario. The dataset consists of 211 recorded meeting sessions, each containing 4 to 8 speakers, with a total length of 118 hours. This dataset aims to bride the advanced research on multi-speaker processing and the practical application scenario in three aspects. With real recorded meetings, AISHELL-4 provides realistic acoustics and rich natural speech characteristics in conversation such as short pause, speech overlap, quick speaker turn, noise, etc. Meanwhile, the accurate transcription and speaker voice activity are provided for each meeting in AISHELL-4. This allows the researchers to explore different aspects in meeting processing, ranging from individual tasks such as speech front-end processing, speech recognition and speaker diarization, to multi-modality modeling and joint optimization of relevant tasks. Given most open source dataset for multi-speaker tasks are in English, AISHELL-4 is the only Mandarin dataset for conversation speech, providing additional value for data diversity in speech community.
INTERSPEECH 2021 ConferencingSpeech Challenge: Towards Far-field Multi-Channel Speech Enhancement for Video Conferencing
Apr 02, 2021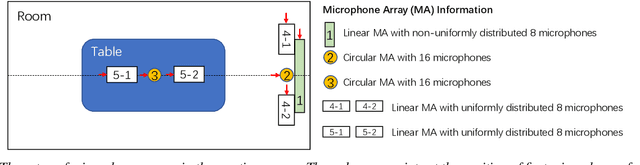
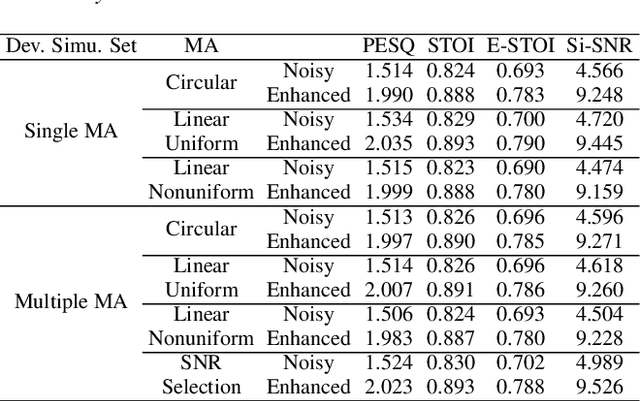
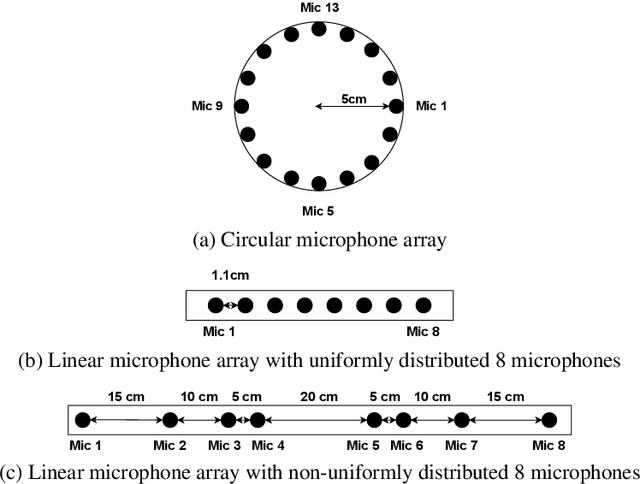
The ConferencingSpeech 2021 challenge is proposed to stimulate research on far-field multi-channel speech enhancement for video conferencing. The challenge consists of two separate tasks: 1) Task 1 is multi-channel speech enhancement with single microphone array and focusing on practical application with real-time requirement and 2) Task 2 is multi-channel speech enhancement with multiple distributed microphone arrays, which is a non-real-time track and does not have any constraints so that participants could explore any algorithms to obtain high speech quality. Targeting the real video conferencing room application, the challenge database was recorded from real speakers and all recording facilities were located by following the real setup of conferencing room. In this challenge, we open-sourced the list of open source clean speech and noise datasets, simulation scripts, and a baseline system for participants to develop their own system. The final ranking of the challenge will be decided by the subjective evaluation which is performed using Absolute Category Ratings (ACR) to estimate Mean Opinion Score (MOS), speech MOS (S-MOS), and noise MOS (N-MOS). This paper describes the challenge, tasks, datasets, and subjective evaluation. The baseline system which is a complex ratio mask based neural network and its experimental results are also presented.