 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging What the Model Thinks and How It Speaks: Self-Aware Speech Language Models for Expressive Speech Generation
Apr 13, 2026Speech Language Models (SLMs) exhibit strong semantic understanding, yet their generated speech often sounds flat and fails to convey expressive intent, undermining user engagement. We term this mismatch the semantic understanding-acoustic realization gap. We attribute this gap to two key deficiencies: (1) intent transmission failure, where SLMs fail to provide the stable utterance-level intent needed for expressive delivery; and (2) realization-unaware training, where no feedback signal verifies whether acoustic outputs faithfully reflect intended expression. To address these issues, we propose SA-SLM (Self-Aware Speech Language Model), built on the principle that the model should be aware of what it thinks during generation and how it speaks during training. SA-SLM addresses this gap through two core contributions: (1) Intent-Aware Bridging, which uses a Variational Information Bottleneck (VIB) objective to translate the model's internal semantics into temporally smooth expressive intent, making speech generation aware of what the model intends to express; and (2) Realization-Aware Alignment, which repurposes the model as its own critic to verify and align acoustic realization with intended expressive intent via rubric-based feedback. Trained on only 800 hours of expressive speech data, our 3B parameter SA-SLM surpasses all open-source baselines and comes within 0.08 points of GPT-4o-Audio in overall expressiveness on the EchoMind benchmark.
Workflow is All You Need: Escaping the "Statistical Smoothing Trap" via High-Entropy Information Foraging and Adversarial Pacing
Dec 10, 2025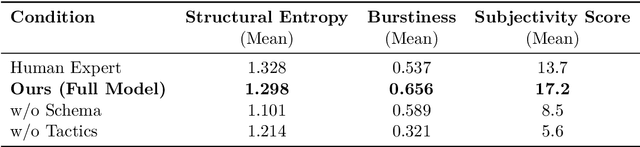



Central to long-form text generation in vertical domains is the "impossible trinity" confronting current large language models (LLMs): the simultaneous achievement of low hallucination, deep logical coherence, and personalized expression. This study establishes that this bottleneck arises from existing generative paradigms succumbing to the Statistical Smoothing Trap, a phenomenon that overlooks the high-entropy information acquisition and structured cognitive processes integral to expert-level writing. To address this limitation, we propose the DeepNews Framework, an agentic workflow that explicitly models the implicit cognitive processes of seasoned financial journalists. The framework integrates three core modules: first, a dual-granularity retrieval mechanism grounded in information foraging theory, which enforces a 10:1 saturated information input ratio to mitigate hallucinatory outputs; second, schema-guided strategic planning, a process leveraging domain expert knowledge bases (narrative schemas) and Atomic Blocks to forge a robust logical skeleton; third, adversarial constraint prompting, a technique deploying tactics including Rhythm Break and Logic Fog to disrupt the probabilistic smoothness inherent in model-generated text. Experiments delineate a salient Knowledge Cliff in deep financial reporting: content truthfulness collapses when retrieved context falls below 15,000 characters, while a high-redundancy input exceeding 30,000 characters stabilizes the Hallucination-Free Rate (HFR) above 85%. In an ecological validity blind test conducted with a top-tier Chinese technology media outlet, the DeepNews system--built on a previous-generation model (DeepSeek-V3-0324)-achieved a 25% submission acceptance rate, significantly outperforming the 0% acceptance rate of zero-shot generation by a state-of-the-art (SOTA) model (GPT-5).
Accent Normalization Using Self-Supervised Discrete Tokens with Non-Parallel Data
Jul 23, 2025Accent normalization converts foreign-accented speech into native-like speech while preserving speaker identity. We propose a novel pipeline using self-supervised discrete tokens and non-parallel training data. The system extracts tokens from source speech, converts them through a dedicated model, and synthesizes the output using flow matching. Our method demonstrates superior performance over a frame-to-frame baseline in naturalness, accentedness reduction, and timbre preservation across multiple English accents. Through token-level phonetic analysis, we validate the effectiveness of our token-based approach. We also develop two duration preservation methods, suitable for applications such as dubbing.
SpeechRefiner: Towards Perceptual Quality Refinement for Front-End Algorithms
Jun 16, 2025Speech pre-processing techniques such as denoising, de-reverberation, and separation, are commonly employed as front-ends for various downstream speech processing tasks. However, these methods can sometimes be inadequate, resulting in residual noise or the introduction of new artifacts. Such deficiencies are typically not captured by metrics like SI-SNR but are noticeable to human listeners. To address this, we introduce SpeechRefiner, a post-processing tool that utilizes Conditional Flow Matching (CFM) to improve the perceptual quality of speech. In this study, we benchmark SpeechRefiner against recent task-specific refinement methods and evaluate its performance within our internal processing pipeline, which integrates multiple front-end algorithms. Experiments show that SpeechRefiner exhibits strong generalization across diverse impairment sources, significantly enhancing speech perceptual quality. Audio demos can be found at https://speechrefiner.github.io/SpeechRefiner/.
Lightweight Speaker Verification Using Transformation Module with Feature Partition and Fusion
Dec 06, 2023Although many efforts have been made on decreasing the model complexity for speaker verification, it is still challenging to deploy speaker verification systems with satisfactory result on low-resource terminals. We design a transformation module that performs feature partition and fusion to implement lightweight speaker verification. The transformation module consists of multiple simple but effective operations, such as convolution, pooling, mean, concatenation, normalization, and element-wise summation. It works in a plug-and-play way, and can be easily implanted into a wide variety of models to reduce the model complexity while maintaining the model error. First, the input feature is split into several low-dimensional feature subsets for decreasing the model complexity. Then, each feature subset is updated by fusing it with the inter-feature-subsets correlational information to enhance its representational capability. Finally, the updated feature subsets are independently fed into the block (one or several layers) of the model for further processing. The features that are output from current block of the model are processed according to the steps above before they are fed into the next block of the model. Experimental data are selected from two public speech corpora (namely VoxCeleb1 and VoxCeleb2). Results show that implanting the transformation module into three models (namely AMCRN, ResNet34, and ECAPA-TDNN) for speaker verification slightly increases the model error and significantly decreases the model complexity. Our proposed method outperforms baseline methods on the whole in memory requirement and computational complexity with lower equal error rate. It also generalizes well across truncated segments with various lengths.
Speaker verification using attentive multi-scale convolutional recurrent network
Jun 01, 2023



In this paper, we propose a speaker verification method by an Attentive Multi-scale Convolutional Recurrent Network (AMCRN). The proposed AMCRN can acquire both local spatial information and global sequential information from the input speech recordings. In the proposed method, logarithm Mel spectrum is extracted from each speech recording and then fed to the proposed AMCRN for learning speaker embedding. Afterwards, the learned speaker embedding is fed to the back-end classifier (such as cosine similarity metric) for scoring in the testing stage. The proposed method is compared with state-of-the-art methods for speaker verification. Experimental data are three public datasets that are selected from two large-scale speech corpora (VoxCeleb1 and VoxCeleb2). Experimental results show that our method exceeds baseline methods in terms of equal error rate and minimal detection cost function, and has advantages over most of baseline methods in terms of computational complexity and memory requirement. In addition, our method generalizes well across truncated speech segments with different durations, and the speaker embedding learned by the proposed AMCRN has stronger generalization ability across two back-end classifiers.
INTERSPEECH 2021 ConferencingSpeech Challenge: Towards Far-field Multi-Channel Speech Enhancement for Video Conferencing
Apr 02, 2021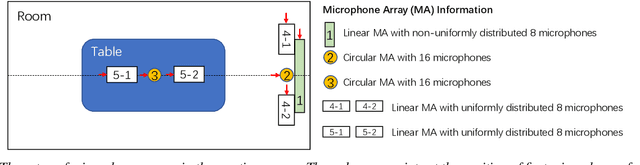
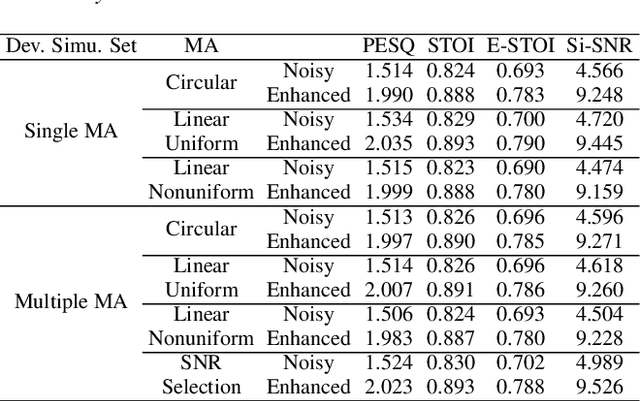
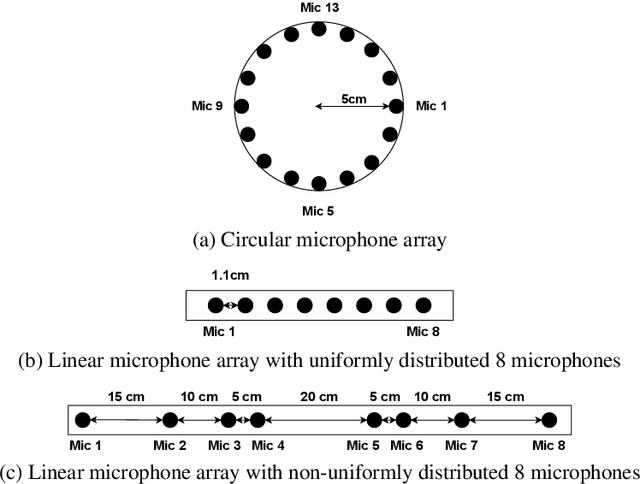
The ConferencingSpeech 2021 challenge is proposed to stimulate research on far-field multi-channel speech enhancement for video conferencing. The challenge consists of two separate tasks: 1) Task 1 is multi-channel speech enhancement with single microphone array and focusing on practical application with real-time requirement and 2) Task 2 is multi-channel speech enhancement with multiple distributed microphone arrays, which is a non-real-time track and does not have any constraints so that participants could explore any algorithms to obtain high speech quality. Targeting the real video conferencing room application, the challenge database was recorded from real speakers and all recording facilities were located by following the real setup of conferencing room. In this challenge, we open-sourced the list of open source clean speech and noise datasets, simulation scripts, and a baseline system for participants to develop their own system. The final ranking of the challenge will be decided by the subjective evaluation which is performed using Absolute Category Ratings (ACR) to estimate Mean Opinion Score (MOS), speech MOS (S-MOS), and noise MOS (N-MOS). This paper describes the challenge, tasks, datasets, and subjective evaluation. The baseline system which is a complex ratio mask based neural network and its experimental results are also presented.