 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechRefiner: Towards Perceptual Quality Refinement for Front-End Algorithms
Jun 16, 2025Speech pre-processing techniques such as denoising, de-reverberation, and separation, are commonly employed as front-ends for various downstream speech processing tasks. However, these methods can sometimes be inadequate, resulting in residual noise or the introduction of new artifacts. Such deficiencies are typically not captured by metrics like SI-SNR but are noticeable to human listeners. To address this, we introduce SpeechRefiner, a post-processing tool that utilizes Conditional Flow Matching (CFM) to improve the perceptual quality of speech. In this study, we benchmark SpeechRefiner against recent task-specific refinement methods and evaluate its performance within our internal processing pipeline, which integrates multiple front-end algorithms. Experiments show that SpeechRefiner exhibits strong generalization across diverse impairment sources, significantly enhancing speech perceptual quality. Audio demos can be found at https://speechrefiner.github.io/SpeechRefiner/.
Spectrally-Corrected and Regularized QDA Classifier for Spiked Covariance Model
Mar 17, 2025Quadratic discriminant analysis (QDA) is a widely used method for classification problems, particularly preferable over Linear Discriminant Analysis (LDA) for heterogeneous data. However, QDA loses its effectiveness in high-dimensional settings, where the data dimension and sample size tend to infinity. To address this issue, we propose a novel QDA method utilizing spectral correction and regularization techniques, termed SR-QDA. The regularization parameters in our method are selected by maximizing the Fisher-discriminant ratio. We compare SR-QDA with QDA, regularized quadratic discriminant analysis (R-QDA), and several other competitors. The results indicate that SR-QDA performs exceptionally well, especially in moderate and high-dimensional situations. Empirical experiments across diverse datasets further support this conclusion.
E1 TTS: Simple and Fast Non-Autoregressive TTS
Sep 14, 2024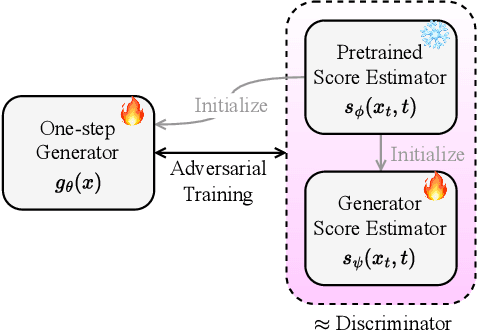
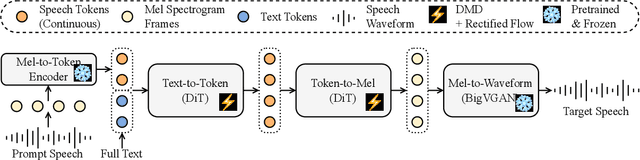
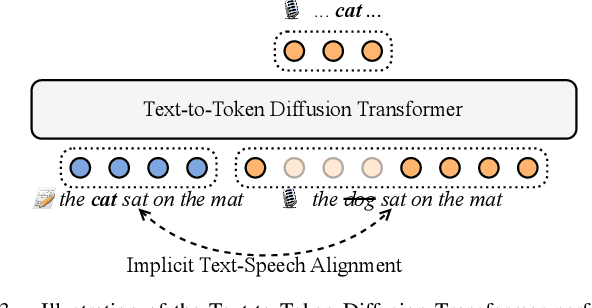
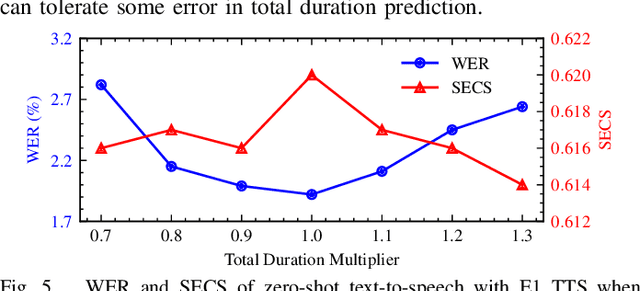
This paper introduces Easy One-Step Text-to-Speech (E1 TTS), an efficient non-autoregressive zero-shot text-to-speech system based on denoising diffusion pretraining and distribution matching distillation. The training of E1 TTS is straightforward; it does not require explicit monotonic alignment between the text and audio pairs. The inference of E1 TTS is efficient, requiring only one neural network evaluation for each utterance. Despite its sampling efficiency, E1 TTS achieves naturalness and speaker similarity comparable to various strong baseline models. Audio samples are available at http://e1tts.github.io/ .
A Self-Correcting Strategy of the Digital Volume Correlation Displacement Field Based on Image Matching: Application to Poor Speckles Quality and Complex-Large Deformation
Jul 16, 2024Digital Volume Correlation (DVC) is widely used for the analysis of three-dimensional displacement and strain fields based on CT scans. However, the applicability of DVC methods is limited when it comes to geomaterials: CT speckles are directly correlated with the material's microstructure, and the speckle structure cannot be artificially altered, with generally poor speckle quality. Additionally, most geomaterials exhibit elastoplastic properties and will undergo complex-large deformations under external loading, sometimes leading to strain localization phenomena. These factors contribute to inaccuracies in the displacement field obtained through DVC, and at present, there is a shortage of correction methods and accuracy assessment techniques for the displacement field. If the accuracy of the DVC displacement field is sufficiently high, the gray residue of the two volume images before and after deformation should be minimal, utilizing this characteristic to develop a correction method for the displacement field is feasible. The proposed self-correcting strategy of the DVC displacement field based on image matching, which from the experimental measurement error. We demonstrated the effectiveness of the proposed method by CT triaxial tests of granite residual soil. Without adding other parameters or adjusting the original parameters of DVC, the gray residue showed that the proposed method can effectively improve the accuracy of the displacement field. Additionally, the accuracy evaluation method can reasonably estimate the accuracy of the displacement field. The proposed method can effectively improve the accuracy of DVC three-dimensional displacement field for the state of speckles with poor quality and complex-large deformation.
Autoregressive Diffusion Transformer for Text-to-Speech Synthesis
Jun 08, 2024Audio language models have recently emerged as a promising approach for various audio generation tasks, relying on audio tokenizers to encode waveforms into sequences of discrete symbols. Audio tokenization often poses a necessary compromise between code bitrate and reconstruction accuracy. When dealing with low-bitrate audio codes, language models are constrained to process only a subset of the information embedded in the audio, which in turn restricts their generative capabilities. To circumvent these issues, we propose encoding audio as vector sequences in continuous space $\mathbb R^d$ and autoregressively generating these sequences using a decoder-only diffusion transformer (ARDiT). Our findings indicate that ARDiT excels in zero-shot text-to-speech and exhibits performance that compares to or even surpasses that of state-of-the-art models. High-bitrate continuous speech representation enables almost flawless reconstruction, allowing our model to achieve nearly perfect speech editing. Our experiments reveal that employing Integral Kullback-Leibler (IKL) divergence for distillation at each autoregressive step significantly boosts the perceived quality of the samples. Simultaneously, it condenses the iterative sampling process of the diffusion model into a single step. Furthermore, ARDiT can be trained to predict several continuous vectors in one step, significantly reducing latency during sampling. Impressively, one of our models can generate $170$ ms of $24$ kHz speech per evaluation step with minimal degradation in performance. Audio samples are available at http://ardit-tts.github.io/ .
UniCATS: A Unified Context-Aware Text-to-Speech Framework with Contextual VQ-Diffusion and Vocoding
Jun 18, 2023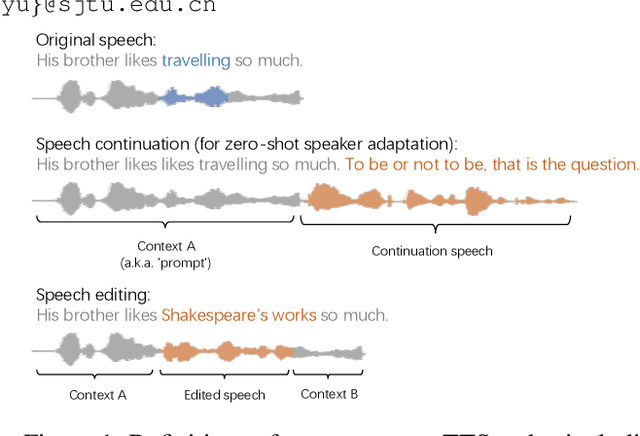

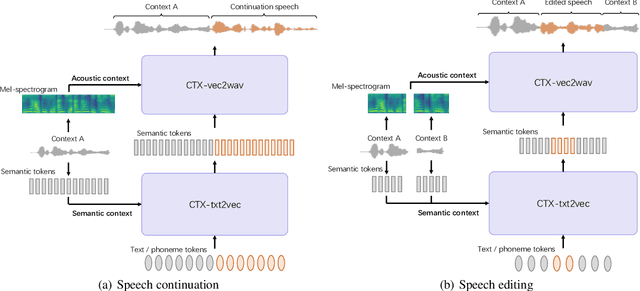

The utilization of discrete speech tokens, divided into semantic tokens and acoustic tokens, has been proven superior to traditional acoustic feature mel-spectrograms in terms of naturalness and robustness for text-to-speech (TTS) synthesis. Recent popular models, such as VALL-E and SPEAR-TTS, allow zero-shot speaker adaptation through auto-regressive (AR) continuation of acoustic tokens extracted from a short speech prompt. However, these AR models are restricted to generate speech only in a left-to-right direction, making them unsuitable for speech editing where both preceding and following contexts are provided. Furthermore, these models rely on acoustic tokens, which have audio quality limitations imposed by the performance of audio codec models. In this study, we propose a unified context-aware TTS framework called UniCATS, which is capable of both speech continuation and editing. UniCATS comprises two components, an acoustic model CTX-txt2vec and a vocoder CTX-vec2wav. CTX-txt2vec employs contextual VQ-diffusion to predict semantic tokens from the input text, enabling it to incorporate the semantic context and maintain seamless concatenation with the surrounding context. Following that, CTX-vec2wav utilizes contextual vocoding to convert these semantic tokens into waveforms, taking into consideration the acoustic context. Our experimental results demonstrate that CTX-vec2wav outperforms HifiGAN and AudioLM in terms of speech resynthesis from semantic tokens. Moreover, we show that UniCATS achieves state-of-the-art performance in both speech continuation and editing.
DiffVoice: Text-to-Speech with Latent Diffusion
Apr 23, 2023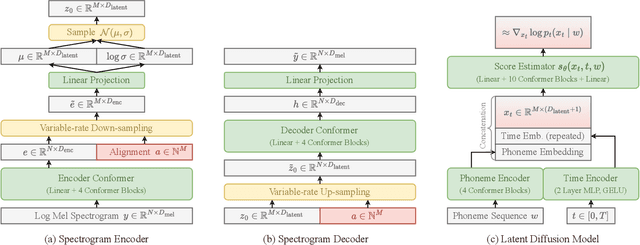
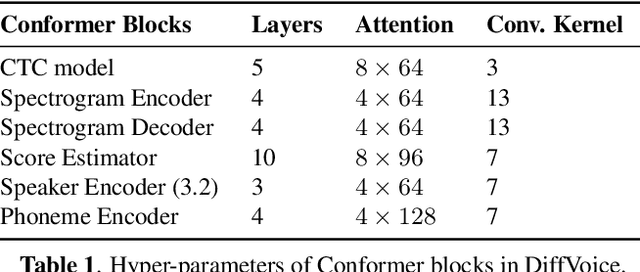
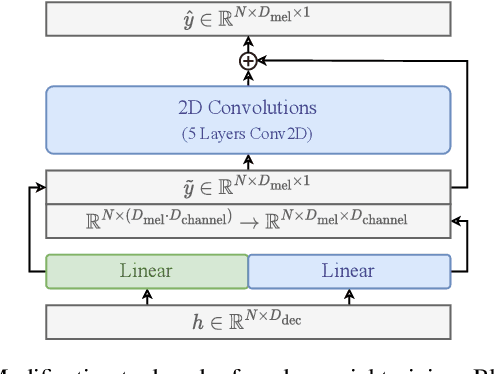

In this work, we present DiffVoice, a novel text-to-speech model based on latent diffusion. We propose to first encode speech signals into a phoneme-rate latent representation with a variational autoencoder enhanced by adversarial training, and then jointly model the duration and the latent representation with a diffusion model. Subjective evaluations on LJSpeech and LibriTTS datasets demonstrate that our method beats the best publicly available systems in naturalness. By adopting recent generative inverse problem solving algorithms for diffusion models, DiffVoice achieves the state-of-the-art performance in text-based speech editing, and zero-shot adaptation.
FedBA: Non-IID Federated Learning Framework in UAV Networks
Oct 10, 2022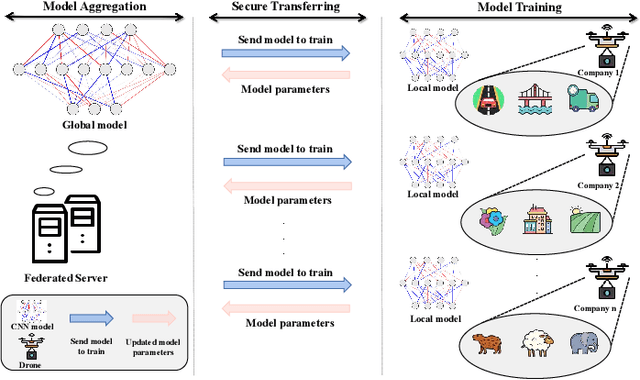
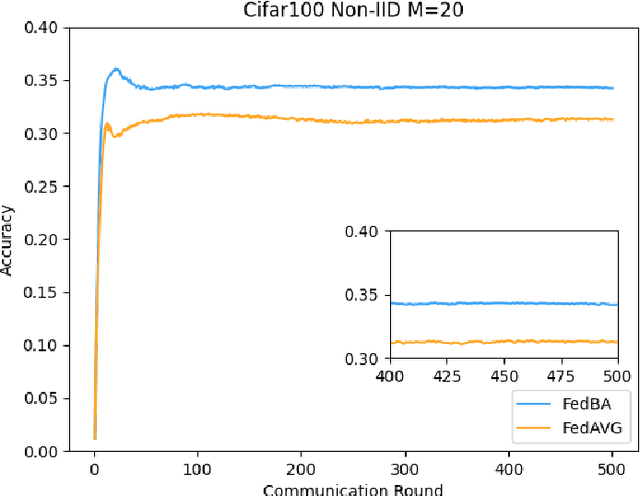
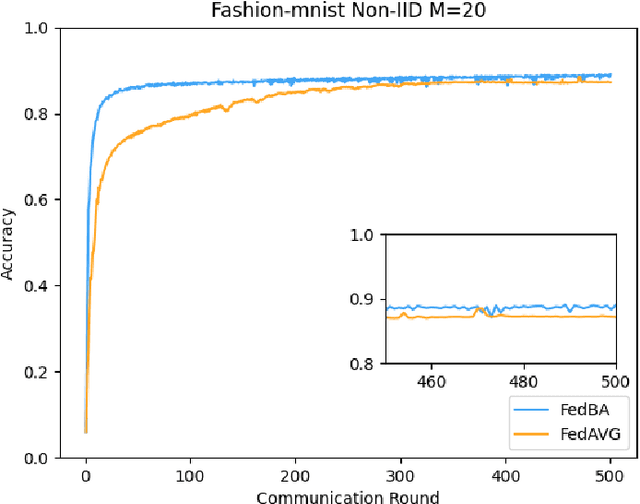
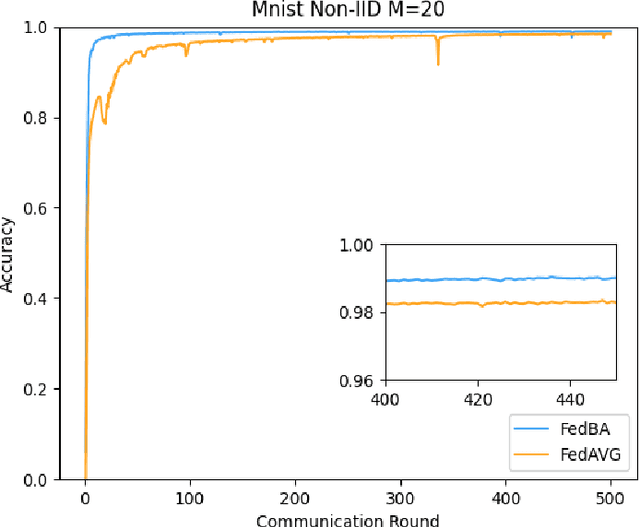
With the development and progress of science and technology, the Internet of Things(IoT) has gradually entered people's lives, bringing great convenience to our lives and improving people's work efficiency. Specifically, the IoT can replace humans in jobs that they cannot perform. As a new type of IoT vehicle, the current status and trend of research on Unmanned Aerial Vehicle(UAV) is gratifying, and the development prospect is very promising. However, privacy and communication are still very serious issues in drone applications. This is because most drones still use centralized cloud-based data processing, which may lead to leakage of data collected by drones. At the same time, the large amount of data collected by drones may incur greater communication overhead when transferred to the cloud. Federated learning as a means of privacy protection can effectively solve the above two problems. However, federated learning when applied to UAV networks also needs to consider the heterogeneity of data, which is caused by regional differences in UAV regulation. In response, this paper proposes a new algorithm FedBA to optimize the global model and solves the data heterogeneity problem. In addition, we apply the algorithm to some real datasets, and the experimental results show that the algorithm outperforms other algorithms and improves the accuracy of the local model for UAVs.