 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccent Normalization Using Self-Supervised Discrete Tokens with Non-Parallel Data
Jul 23, 2025Accent normalization converts foreign-accented speech into native-like speech while preserving speaker identity. We propose a novel pipeline using self-supervised discrete tokens and non-parallel training data. The system extracts tokens from source speech, converts them through a dedicated model, and synthesizes the output using flow matching. Our method demonstrates superior performance over a frame-to-frame baseline in naturalness, accentedness reduction, and timbre preservation across multiple English accents. Through token-level phonetic analysis, we validate the effectiveness of our token-based approach. We also develop two duration preservation methods, suitable for applications such as dubbing.
PersonaTAB: Predicting Personality Traits using Textual, Acoustic, and Behavioral Cues in Fully-Duplex Speech Dialogs
May 20, 2025Despite significant progress in neural spoken dialog systems, personality-aware conversation agents -- capable of adapting behavior based on personalities -- remain underexplored due to the absence of personality annotations in speech datasets. We propose a pipeline that preprocesses raw audio recordings to create a dialogue dataset annotated with timestamps, response types, and emotion/sentiment labels. We employ an automatic speech recognition (ASR) system to extract transcripts and timestamps, then generate conversation-level annotations. Leveraging these annotations, we design a system that employs large language models to predict conversational personality. Human evaluators were engaged to identify conversational characteristics and assign personality labels. Our analysis demonstrates that the proposed system achieves stronger alignment with human judgments compared to existing approaches.
Hierarchical Control of Emotion Rendering in Speech Synthesis
Dec 17, 2024



Emotional text-to-speech synthesis (TTS) aims to generate realistic emotional speech from input text. However, quantitatively controlling multi-level emotion rendering remains challenging. In this paper, we propose a diffusion-based emotional TTS framework with a novel approach for emotion intensity modeling to facilitate fine-grained control over emotion rendering at the phoneme, word, and utterance levels. We introduce a hierarchical emotion distribution (ED) extractor that captures a quantifiable ED embedding across different speech segment levels. Additionally, we explore various acoustic features and assess their impact on emotion intensity modeling. During TTS training, the hierarchical ED embedding effectively captures the variance in emotion intensity from the reference audio and correlates it with linguistic and speaker information. The TTS model not only generates emotional speech during inference, but also quantitatively controls the emotion rendering over the speech constituents. Both objective and subjective evaluations demonstrate the effectiveness of our framework in terms of speech quality, emotional expressiveness, and hierarchical emotion control.
MacST: Multi-Accent Speech Synthesis via Text Transliteration for Accent Conversion
Sep 14, 2024



In accented voice conversion or accent conversion, we seek to convert the accent in speech from one another while preserving speaker identity and semantic content. In this study, we formulate a novel method for creating multi-accented speech samples, thus pairs of accented speech samples by the same speaker, through text transliteration for training accent conversion systems. We begin by generating transliterated text with Large Language Models (LLMs), which is then fed into multilingual TTS models to synthesize accented English speech. As a reference system, we built a sequence-to-sequence model on the synthetic parallel corpus for accent conversion. We validated the proposed method for both native and non-native English speakers. Subjective and objective evaluations further validate our dataset's effectiveness in accent conversion studies.
Autoregressive Diffusion Transformer for Text-to-Speech Synthesis
Jun 08, 2024Audio language models have recently emerged as a promising approach for various audio generation tasks, relying on audio tokenizers to encode waveforms into sequences of discrete symbols. Audio tokenization often poses a necessary compromise between code bitrate and reconstruction accuracy. When dealing with low-bitrate audio codes, language models are constrained to process only a subset of the information embedded in the audio, which in turn restricts their generative capabilities. To circumvent these issues, we propose encoding audio as vector sequences in continuous space $\mathbb R^d$ and autoregressively generating these sequences using a decoder-only diffusion transformer (ARDiT). Our findings indicate that ARDiT excels in zero-shot text-to-speech and exhibits performance that compares to or even surpasses that of state-of-the-art models. High-bitrate continuous speech representation enables almost flawless reconstruction, allowing our model to achieve nearly perfect speech editing. Our experiments reveal that employing Integral Kullback-Leibler (IKL) divergence for distillation at each autoregressive step significantly boosts the perceived quality of the samples. Simultaneously, it condenses the iterative sampling process of the diffusion model into a single step. Furthermore, ARDiT can be trained to predict several continuous vectors in one step, significantly reducing latency during sampling. Impressively, one of our models can generate $170$ ms of $24$ kHz speech per evaluation step with minimal degradation in performance. Audio samples are available at http://ardit-tts.github.io/ .
Hierarchical Emotion Prediction and Control in Text-to-Speech Synthesis
May 15, 2024



It remains a challenge to effectively control the emotion rendering in text-to-speech (TTS) synthesis. Prior studies have primarily focused on learning a global prosodic representation at the utterance level, which strongly correlates with linguistic prosody. Our goal is to construct a hierarchical emotion distribution (ED) that effectively encapsulates intensity variations of emotions at various levels of granularity, encompassing phonemes, words, and utterances. During TTS training, the hierarchical ED is extracted from the ground-truth audio and guides the predictor to establish a connection between emotional and linguistic prosody. At run-time inference, the TTS model generates emotional speech and, at the same time, provides quantitative control of emotion over the speech constituents. Both objective and subjective evaluations validate the effectiveness of the proposed framework in terms of emotion prediction and control.
Fine-Grained Quantitative Emotion Editing for Speech Generation
Mar 04, 2024It remains a significant challenge how to quantitatively control the expressiveness of speech emotion in speech generation. In this work, we present a novel approach for manipulating the rendering of emotions for speech generation. We propose a hierarchical emotion distribution extractor, i.e. Hierarchical ED, that quantifies the intensity of emotions at different levels of granularity. Support vector machines (SVMs) are employed to rank emotion intensity, resulting in a hierarchical emotional embedding. Hierarchical ED is subsequently integrated into the FastSpeech2 framework, guiding the model to learn emotion intensity at phoneme, word, and utterance levels. During synthesis, users can manually edit the emotional intensity of the generated voices. Both objective and subjective evaluations demonstrate the effectiveness of the proposed network in terms of fine-grained quantitative emotion editing.
Style-Restricted GAN: Multi-Modal Translation with Style Restriction Using Generative Adversarial Networks
May 17, 2021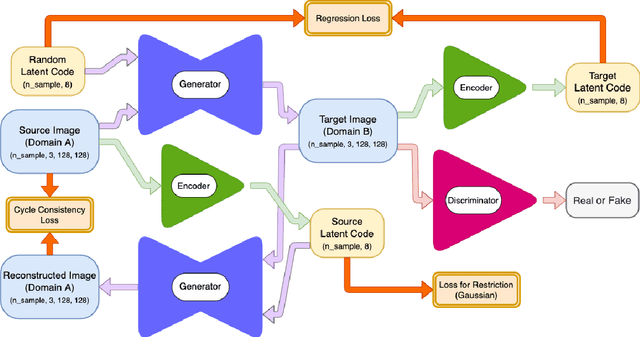
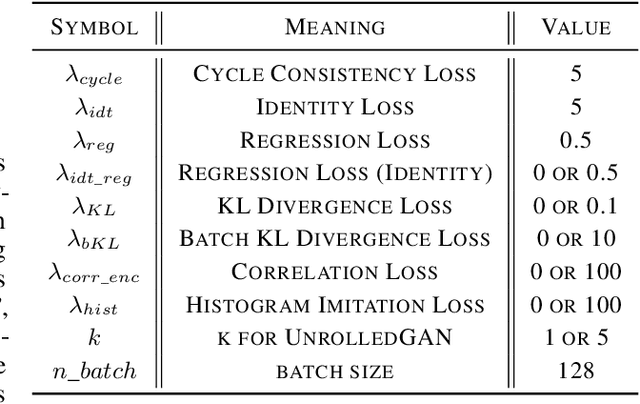
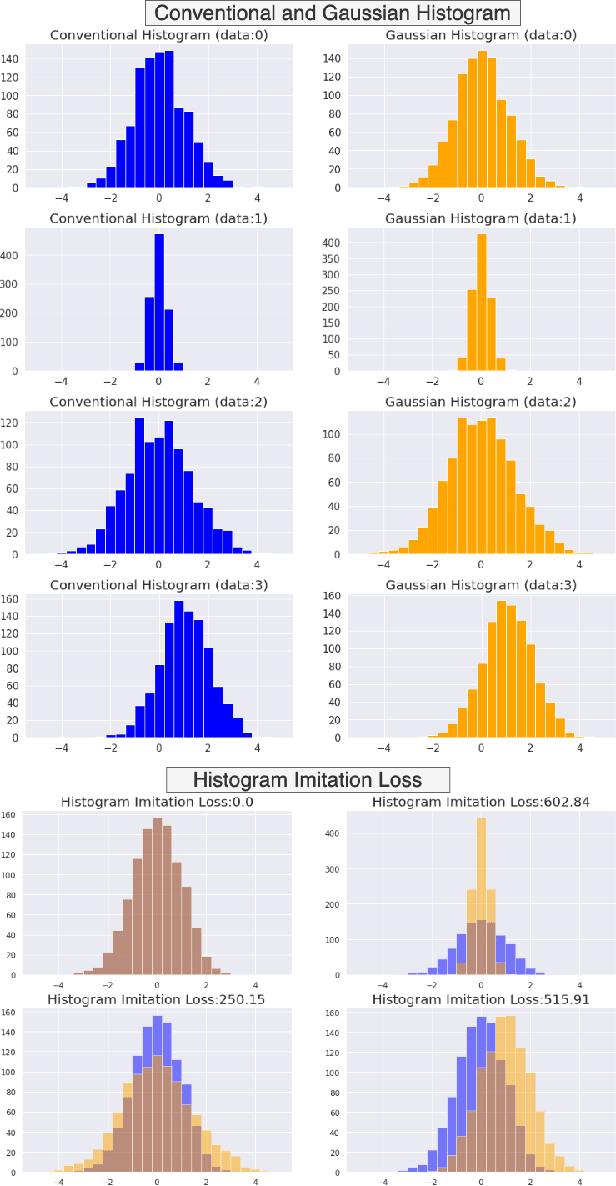
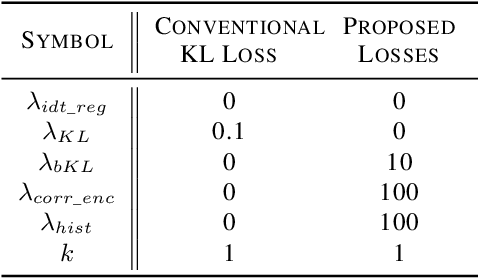
Unpaired image-to-image translation using Generative Adversarial Networks (GAN) is successful in converting images among multiple domains. Moreover, recent studies have shown a way to diversify the outputs of the generator. However, since there are no restrictions on how the generator diversifies the results, it is likely to translate some unexpected features. In this paper, we propose Style-Restricted GAN (SRGAN), a novel approach to transfer input images into different domains' with different styles, changing the exclusively class-related features. Additionally, instead of KL divergence loss, we adopt 3 new losses to restrict the distribution of the encoded features: batch KL divergence loss, correlation loss, and histogram imitation loss. The study reports quantitative as well as qualitative results with Precision, Recall, Density, and Coverage. The proposed 3 losses lead to the enhancement of the level of diversity compared to the conventional KL loss. In particular, SRGAN is found to be successful in translating with higher diversity and without changing the class-unrelated features in the CelebA face dataset. Our implementation is available at https://github.com/shinshoji01/Style-Restricted_GAN.