Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE1 TTS: Simple and Fast Non-Autoregressive TTS
Paper and Code
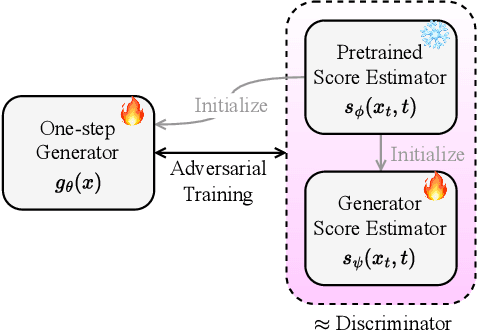
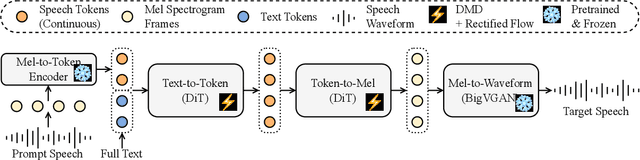
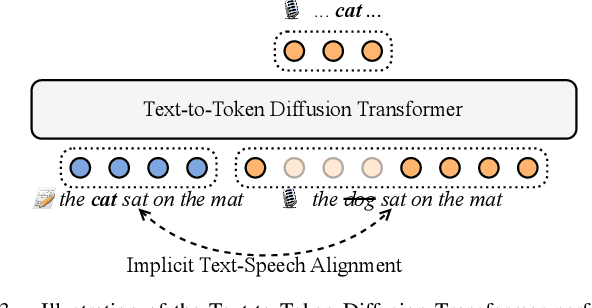
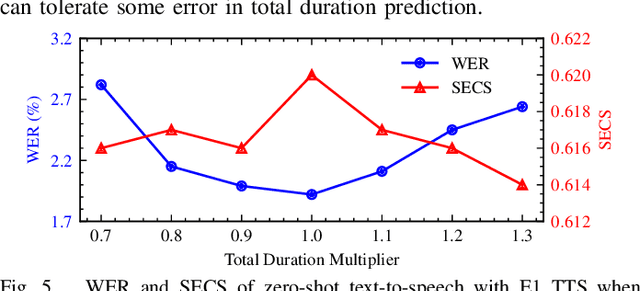
This paper introduces Easy One-Step Text-to-Speech (E1 TTS), an efficient non-autoregressive zero-shot text-to-speech system based on denoising diffusion pretraining and distribution matching distillation. The training of E1 TTS is straightforward; it does not require explicit monotonic alignment between the text and audio pairs. The inference of E1 TTS is efficient, requiring only one neural network evaluation for each utterance. Despite its sampling efficiency, E1 TTS achieves naturalness and speaker similarity comparable to various strong baseline models. Audio samples are available at http://e1tts.github.io/ .
View paper on