 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCATS: A Unified Context-Aware Text-to-Speech Framework with Contextual VQ-Diffusion and Vocoding
Paper and Code
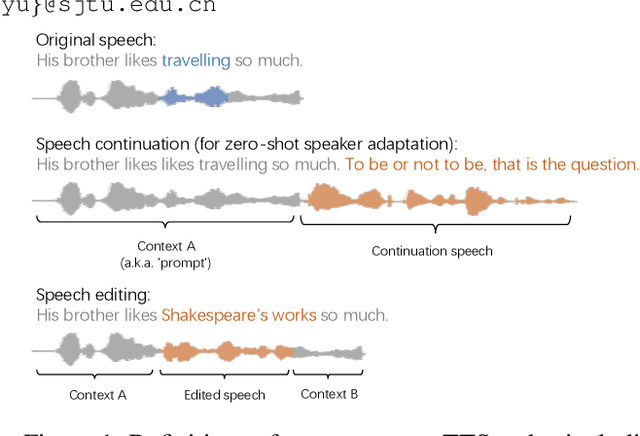

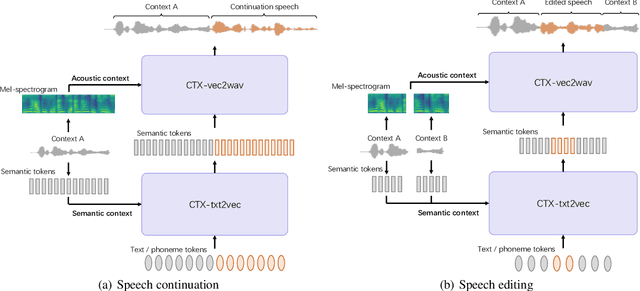

The utilization of discrete speech tokens, divided into semantic tokens and acoustic tokens, has been proven superior to traditional acoustic feature mel-spectrograms in terms of naturalness and robustness for text-to-speech (TTS) synthesis. Recent popular models, such as VALL-E and SPEAR-TTS, allow zero-shot speaker adaptation through auto-regressive (AR) continuation of acoustic tokens extracted from a short speech prompt. However, these AR models are restricted to generate speech only in a left-to-right direction, making them unsuitable for speech editing where both preceding and following contexts are provided. Furthermore, these models rely on acoustic tokens, which have audio quality limitations imposed by the performance of audio codec models. In this study, we propose a unified context-aware TTS framework called UniCATS, which is capable of both speech continuation and editing. UniCATS comprises two components, an acoustic model CTX-txt2vec and a vocoder CTX-vec2wav. CTX-txt2vec employs contextual VQ-diffusion to predict semantic tokens from the input text, enabling it to incorporate the semantic context and maintain seamless concatenation with the surrounding context. Following that, CTX-vec2wav utilizes contextual vocoding to convert these semantic tokens into waveforms, taking into consideration the acoustic context. Our experimental results demonstrate that CTX-vec2wav outperforms HifiGAN and AudioLM in terms of speech resynthesis from semantic tokens. Moreover, we show that UniCATS achieves state-of-the-art performance in both speech continuation and editing.