 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Speaker Verification Using Transformation Module with Feature Partition and Fusion
Dec 06, 2023Although many efforts have been made on decreasing the model complexity for speaker verification, it is still challenging to deploy speaker verification systems with satisfactory result on low-resource terminals. We design a transformation module that performs feature partition and fusion to implement lightweight speaker verification. The transformation module consists of multiple simple but effective operations, such as convolution, pooling, mean, concatenation, normalization, and element-wise summation. It works in a plug-and-play way, and can be easily implanted into a wide variety of models to reduce the model complexity while maintaining the model error. First, the input feature is split into several low-dimensional feature subsets for decreasing the model complexity. Then, each feature subset is updated by fusing it with the inter-feature-subsets correlational information to enhance its representational capability. Finally, the updated feature subsets are independently fed into the block (one or several layers) of the model for further processing. The features that are output from current block of the model are processed according to the steps above before they are fed into the next block of the model. Experimental data are selected from two public speech corpora (namely VoxCeleb1 and VoxCeleb2). Results show that implanting the transformation module into three models (namely AMCRN, ResNet34, and ECAPA-TDNN) for speaker verification slightly increases the model error and significantly decreases the model complexity. Our proposed method outperforms baseline methods on the whole in memory requirement and computational complexity with lower equal error rate. It also generalizes well across truncated segments with various lengths.
Low-Complexity Acoustic Scene Classification Using Data Augmentation and Lightweight ResNet
Jun 03, 2023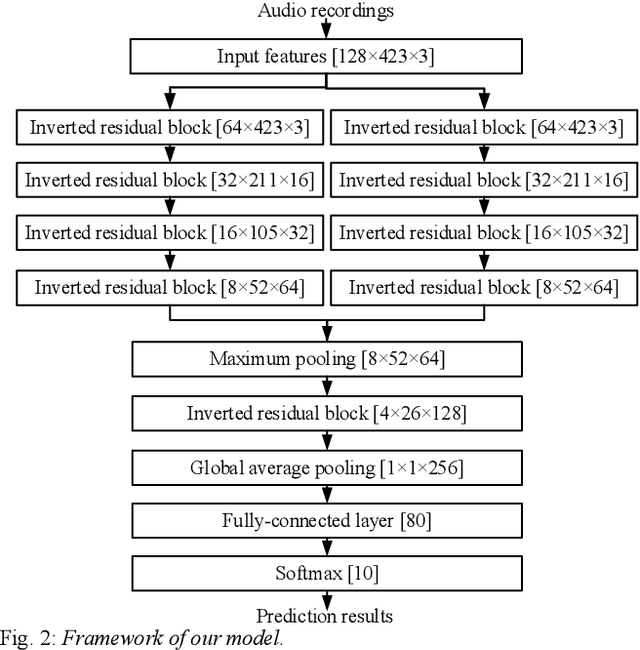
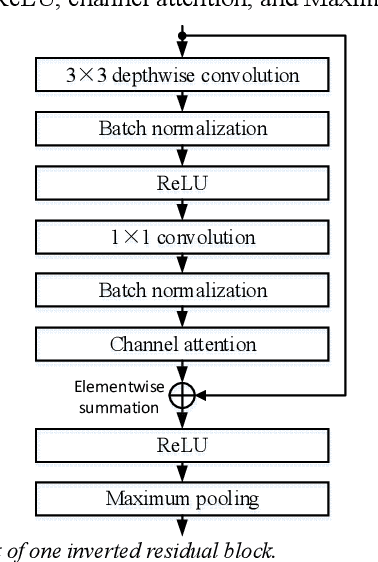
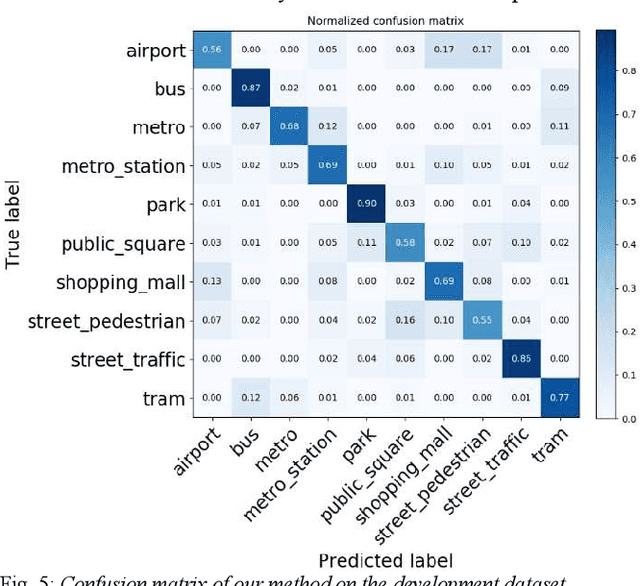
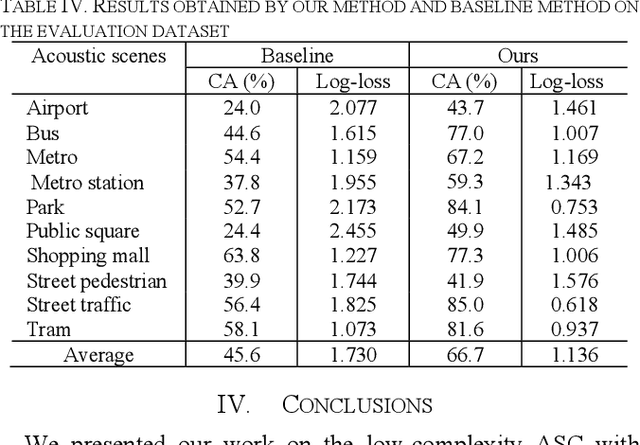
We present a work on low-complexity acoustic scene classification (ASC) with multiple devices, namely the subtask A of Task 1 of the DCASE2021 challenge. This subtask focuses on classifying audio samples of multiple devices with a low-complexity model, where two main difficulties need to be overcome. First, the audio samples are recorded by different devices, and there is mismatch of recording devices in audio samples. We reduce the negative impact of the mismatch of recording devices by using some effective strategies, including data augmentation (e.g., mix-up, spectrum correction, pitch shift), usages of multi-patch network structure and channel attention. Second, the model size should be smaller than a threshold (e.g., 128 KB required by the DCASE2021 challenge). To meet this condition, we adopt a ResNet with both depthwise separable convolution and channel attention as the backbone network, and perform model compression. In summary, we propose a low-complexity ASC method using data augmentation and a lightweight ResNet. Evaluated on the official development and evaluation datasets, our method obtains classification accuracy scores of 71.6% and 66.7%, respectively; and obtains Log-loss scores of 1.038 and 1.136, respectively. Our final model size is 110.3 KB which is smaller than the maximum of 128 KB.
Speaker verification using attentive multi-scale convolutional recurrent network
Jun 01, 2023



In this paper, we propose a speaker verification method by an Attentive Multi-scale Convolutional Recurrent Network (AMCRN). The proposed AMCRN can acquire both local spatial information and global sequential information from the input speech recordings. In the proposed method, logarithm Mel spectrum is extracted from each speech recording and then fed to the proposed AMCRN for learning speaker embedding. Afterwards, the learned speaker embedding is fed to the back-end classifier (such as cosine similarity metric) for scoring in the testing stage. The proposed method is compared with state-of-the-art methods for speaker verification. Experimental data are three public datasets that are selected from two large-scale speech corpora (VoxCeleb1 and VoxCeleb2). Experimental results show that our method exceeds baseline methods in terms of equal error rate and minimal detection cost function, and has advantages over most of baseline methods in terms of computational complexity and memory requirement. In addition, our method generalizes well across truncated speech segments with different durations, and the speaker embedding learned by the proposed AMCRN has stronger generalization ability across two back-end classifiers.
Few-Shot Speaker Identification Using Lightweight Prototypical Network with Feature Grouping and Interaction
May 31, 2023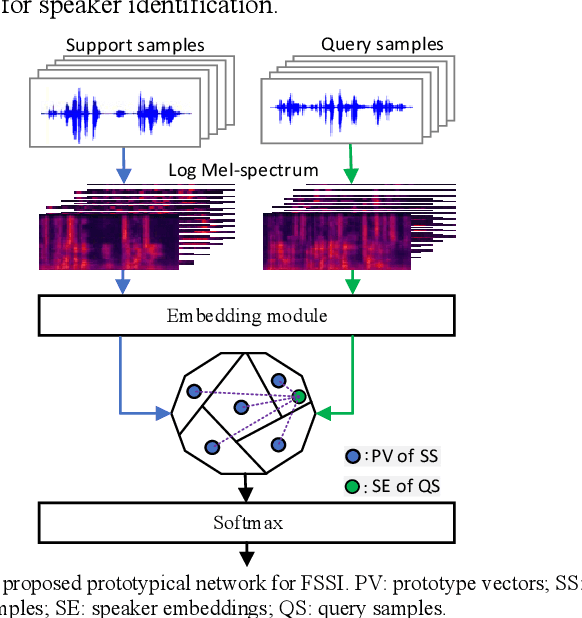
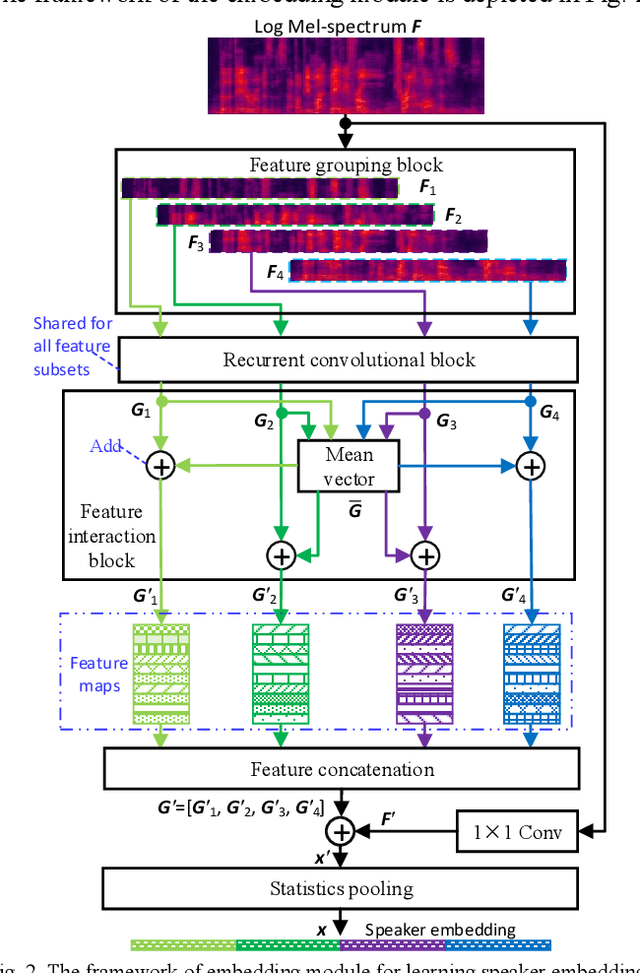
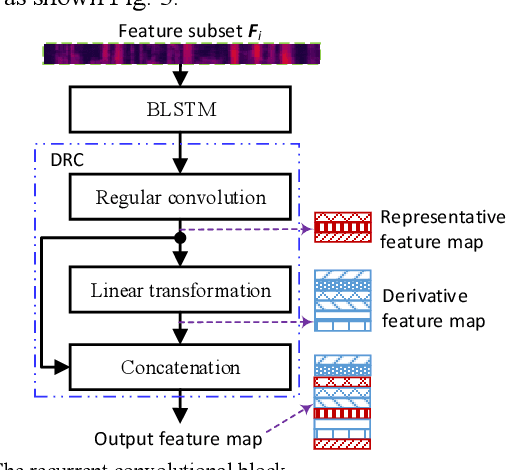

Existing methods for few-shot speaker identification (FSSI) obtain high accuracy, but their computational complexities and model sizes need to be reduced for lightweight applications. In this work, we propose a FSSI method using a lightweight prototypical network with the final goal to implement the FSSI on intelligent terminals with limited resources, such as smart watches and smart speakers. In the proposed prototypical network, an embedding module is designed to perform feature grouping for reducing the memory requirement and computational complexity, and feature interaction for enhancing the representational ability of the learned speaker embedding. In the proposed embedding module, audio feature of each speech sample is split into several low-dimensional feature subsets that are transformed by a recurrent convolutional block in parallel. Then, the operations of averaging, addition, concatenation, element-wise summation and statistics pooling are sequentially executed to learn a speaker embedding for each speech sample. The recurrent convolutional block consists of a block of bidirectional long short-term memory, and a block of de-redundancy convolution in which feature grouping and interaction are conducted too. Our method is compared to baseline methods on three datasets that are selected from three public speech corpora (VoxCeleb1, VoxCeleb2, and LibriSpeech). The results show that our method obtains higher accuracy under several conditions, and has advantages over all baseline methods in computational complexity and model size.