 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Dysarthria Wake-Up Word Spotting: An End-to-End Approach for SLT 2024 LRDWWS Challenge
Sep 16, 2024Speech has emerged as a widely embraced user interface across diverse applications. However, for individuals with dysarthria, the inherent variability in their speech poses significant challenges. This paper presents an end-to-end Pretrain-based Dual-filter Dysarthria Wake-up word Spotting (PD-DWS) system for the SLT 2024 Low-Resource Dysarthria Wake-Up Word Spotting Challenge. Specifically, our system improves performance from two key perspectives: audio modeling and dual-filter strategy. For audio modeling, we propose an innovative 2branch-d2v2 model based on the pre-trained data2vec2 (d2v2), which can simultaneously model automatic speech recognition (ASR) and wake-up word spotting (WWS) tasks through a unified multi-task finetuning paradigm. Additionally, a dual-filter strategy is introduced to reduce the false accept rate (FAR) while maintaining the same false reject rate (FRR). Experimental results demonstrate that our PD-DWS system achieves an FAR of 0.00321 and an FRR of 0.005, with a total score of 0.00821 on the test-B eval set, securing first place in the challenge.
Predicting Multi-Codebook Vector Quantization Indexes for Knowledge Distillation
Oct 31, 2022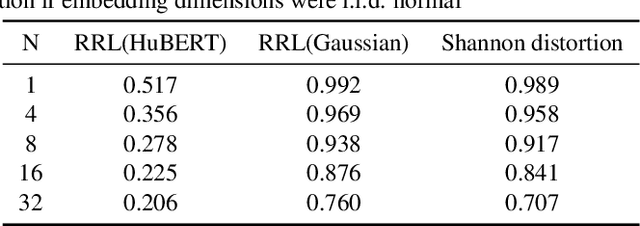
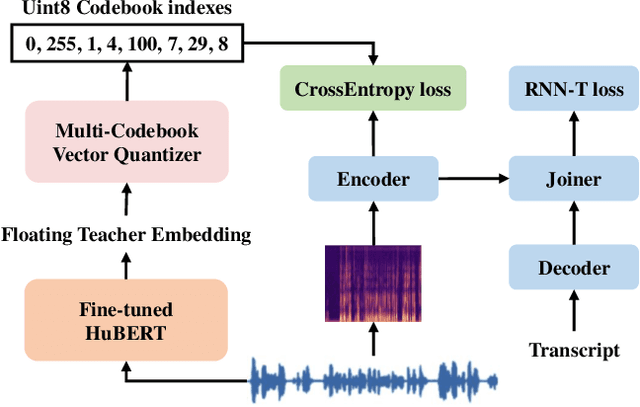

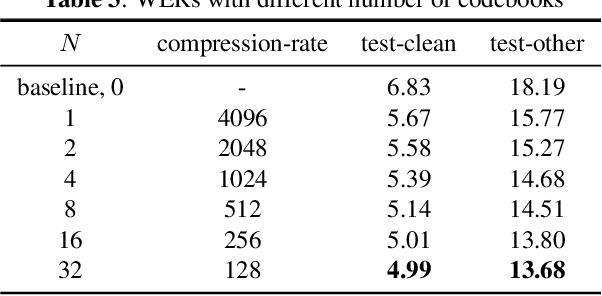
Knowledge distillation(KD) is a common approach to improve model performance in automatic speech recognition (ASR), where a student model is trained to imitate the output behaviour of a teacher model. However, traditional KD methods suffer from teacher label storage issue, especially when the training corpora are large. Although on-the-fly teacher label generation tackles this issue, the training speed is significantly slower as the teacher model has to be evaluated every batch. In this paper, we reformulate the generation of teacher label as a codec problem. We propose a novel Multi-codebook Vector Quantization (MVQ) approach that compresses teacher embeddings to codebook indexes (CI). Based on this, a KD training framework (MVQ-KD) is proposed where a student model predicts the CI generated from the embeddings of a self-supervised pre-trained teacher model. Experiments on the LibriSpeech clean-100 hour show that MVQ-KD framework achieves comparable performance as traditional KD methods (l1, l2), while requiring 256 times less storage. When the full LibriSpeech dataset is used, MVQ-KD framework results in 13.8% and 8.2% relative word error rate reductions (WERRs) for non -streaming transducer on test-clean and test-other and 4.0% and 4.9% for streaming transducer. The implementation of this work is already released as a part of the open-source project icefall.
F-T-LSTM based Complex Network for Joint Acoustic Echo Cancellation and Speech Enhancement
Jun 16, 2021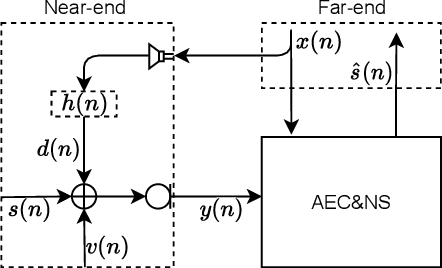
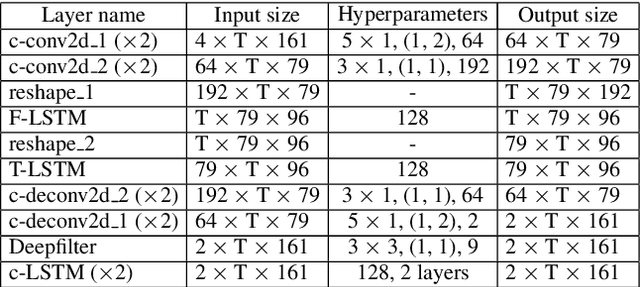
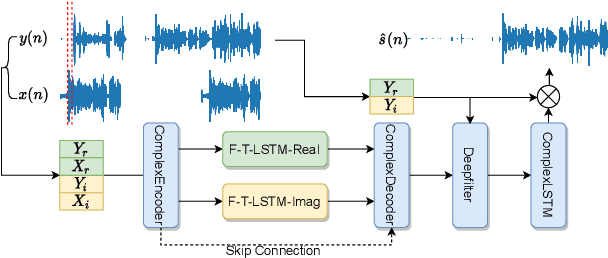
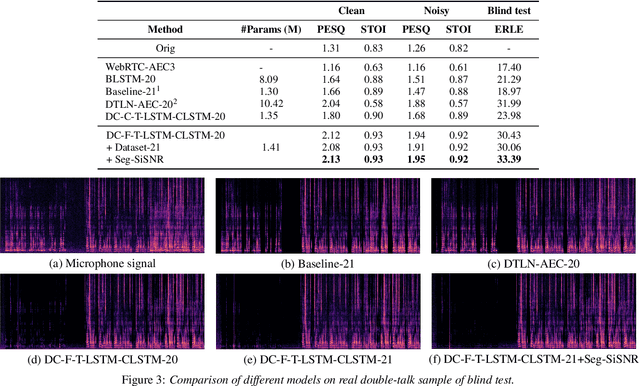
With the increasing demand for audio communication and online conference, ensuring the robustness of Acoustic Echo Cancellation (AEC) under the complicated acoustic scenario including noise, reverberation and nonlinear distortion has become a top issue. Although there have been some traditional methods that consider nonlinear distortion, they are still inefficient for echo suppression and the performance will be attenuated when noise is present. In this paper, we present a real-time AEC approach using complex neural network to better modeling the important phase information and frequency-time-LSTMs (F-T-LSTM), which scan both frequency and time axis, for better temporal modeling. Moreover, we utilize modified SI-SNR as cost function to make the model to have better echo cancellation and noise suppression (NS) performance. With only 1.4M parameters, the proposed approach outperforms the AEC-challenge baseline by 0.27 in terms of Mean Opinion Score (MOS).
AISHELL-4: An Open Source Dataset for Speech Enhancement, Separation, Recognition and Speaker Diarization in Conference Scenario
Apr 08, 2021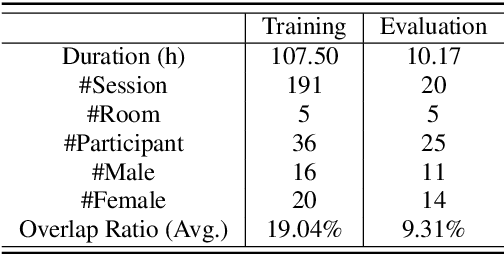
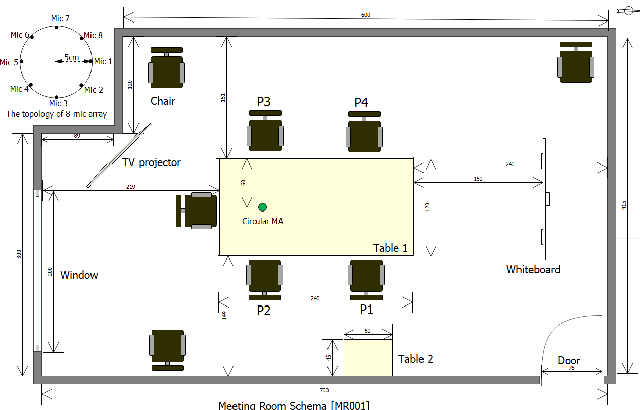

In this paper, we present AISHELL-4, a sizable real-recorded Mandarin speech dataset collected by 8-channel circular microphone array for speech processing in conference scenario. The dataset consists of 211 recorded meeting sessions, each containing 4 to 8 speakers, with a total length of 118 hours. This dataset aims to bride the advanced research on multi-speaker processing and the practical application scenario in three aspects. With real recorded meetings, AISHELL-4 provides realistic acoustics and rich natural speech characteristics in conversation such as short pause, speech overlap, quick speaker turn, noise, etc. Meanwhile, the accurate transcription and speaker voice activity are provided for each meeting in AISHELL-4. This allows the researchers to explore different aspects in meeting processing, ranging from individual tasks such as speech front-end processing, speech recognition and speaker diarization, to multi-modality modeling and joint optimization of relevant tasks. Given most open source dataset for multi-speaker tasks are in English, AISHELL-4 is the only Mandarin dataset for conversation speech, providing additional value for data diversity in speech community.