 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePHYBench: Holistic Evaluation of Physical Perception and Reasoning in Large Language Models
Apr 22, 2025



We introduce PHYBench, a novel, high-quality benchmark designed for evaluating reasoning capabilities of large language models (LLMs) in physical contexts. PHYBench consists of 500 meticulously curated physics problems based on real-world physical scenarios, designed to assess the ability of models to understand and reason about realistic physical processes. Covering mechanics, electromagnetism, thermodynamics, optics, modern physics, and advanced physics, the benchmark spans difficulty levels from high school exercises to undergraduate problems and Physics Olympiad challenges. Additionally, we propose the Expression Edit Distance (EED) Score, a novel evaluation metric based on the edit distance between mathematical expressions, which effectively captures differences in model reasoning processes and results beyond traditional binary scoring methods. We evaluate various LLMs on PHYBench and compare their performance with human experts. Our results reveal that even state-of-the-art reasoning models significantly lag behind human experts, highlighting their limitations and the need for improvement in complex physical reasoning scenarios. Our benchmark results and dataset are publicly available at https://phybench-official.github.io/phybench-demo/.
OriGen:Enhancing RTL Code Generation with Code-to-Code Augmentation and Self-Reflection
Jul 23, 2024Recent studies have illuminated that Large Language Models (LLMs) exhibit substantial potential in the realm of RTL (Register Transfer Level) code generation, with notable advancements evidenced by commercial models such as GPT-4 and Claude3-Opus. Despite their proficiency, these commercial LLMs often raise concerns regarding privacy and security. Conversely, open-source LLMs, which offer solutions to these concerns, have inferior performance in RTL code generation tasks to commercial models due to the lack of highquality open-source RTL datasets. To address this issue, we introduce OriGen, a fully open-source framework featuring self-reflection capabilities and a dataset augmentation methodology for generating high-quality, large-scale RTL code. We propose a novel code-to-code augmentation methodology that leverages knowledge distillation to enhance the quality of the open-source RTL code datasets. Additionally, OriGen is capable of correcting syntactic errors by leveraging a self-reflection process based on feedback from the compiler. The self-reflection ability of the model is facilitated by a carefully constructed dataset, which comprises a comprehensive collection of samples. Experimental results demonstrate that OriGen remarkably outperforms other open-source alternatives in RTL code generation, surpassing the previous best-performing LLM by 9.8% on the VerilogEval-Human benchmark. Furthermore, OriGen exhibits superior capabilities in self-reflection and error rectification, surpassing GPT-4 by 18.1% on the benchmark designed to evaluate the capability of self-reflection.
Exploring Representation Learning for Small-Footprint Keyword Spotting
Mar 20, 2023In this paper, we investigate representation learning for low-resource keyword spotting (KWS). The main challenges of KWS are limited labeled data and limited available device resources. To address those challenges, we explore representation learning for KWS by self-supervised contrastive learning and self-training with pretrained model. First, local-global contrastive siamese networks (LGCSiam) are designed to learn similar utterance-level representations for similar audio samplers by proposed local-global contrastive loss without requiring ground-truth. Second, a self-supervised pretrained Wav2Vec 2.0 model is applied as a constraint module (WVC) to force the KWS model to learn frame-level acoustic representations. By the LGCSiam and WVC modules, the proposed small-footprint KWS model can be pretrained with unlabeled data. Experiments on speech commands dataset show that the self-training WVC module and the self-supervised LGCSiam module significantly improve accuracy, especially in the case of training on a small labeled dataset.
Relate auditory speech to EEG by shallow-deep attention-based network
Mar 20, 2023


Electroencephalography (EEG) plays a vital role in detecting how brain responses to different stimulus. In this paper, we propose a novel Shallow-Deep Attention-based Network (SDANet) to classify the correct auditory stimulus evoking the EEG signal. It adopts the Attention-based Correlation Module (ACM) to discover the connection between auditory speech and EEG from global aspect, and the Shallow-Deep Similarity Classification Module (SDSCM) to decide the classification result via the embeddings learned from the shallow and deep layers. Moreover, various training strategies and data augmentation are used to boost the model robustness. Experiments are conducted on the dataset provided by Auditory EEG challenge (ICASSP Signal Processing Grand Challenge 2023). Results show that the proposed model has a significant gain over the baseline on the match-mismatch track.
Improving Weakly Supervised Sound Event Detection with Causal Intervention
Mar 10, 2023Existing weakly supervised sound event detection (WSSED) work has not explored both types of co-occurrences simultaneously, i.e., some sound events often co-occur, and their occurrences are usually accompanied by specific background sounds, so they would be inevitably entangled, causing misclassification and biased localization results with only clip-level supervision. To tackle this issue, we first establish a structural causal model (SCM) to reveal that the context is the main cause of co-occurrence confounders that mislead the model to learn spurious correlations between frames and clip-level labels. Based on the causal analysis, we propose a causal intervention (CI) method for WSSED to remove the negative impact of co-occurrence confounders by iteratively accumulating every possible context of each class and then re-projecting the contexts to the frame-level features for making the event boundary clearer. Experiments show that our method effectively improves the performance on multiple datasets and can generalize to various baseline models.
Predicting Multi-Codebook Vector Quantization Indexes for Knowledge Distillation
Oct 31, 2022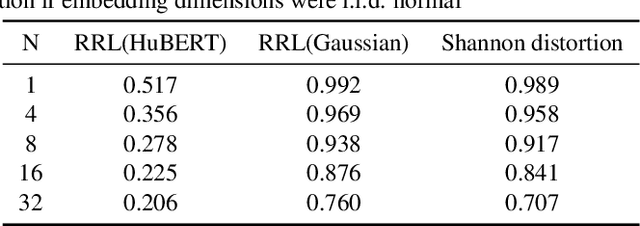
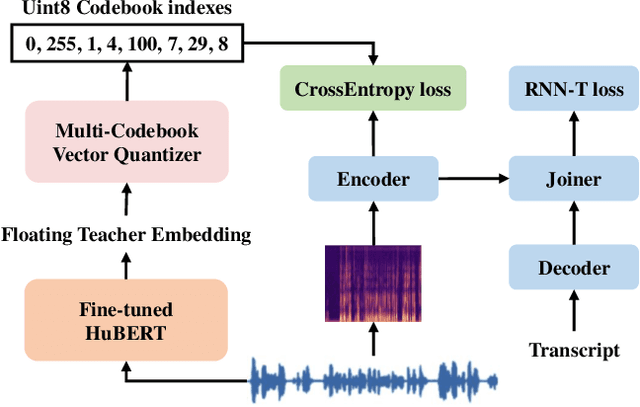

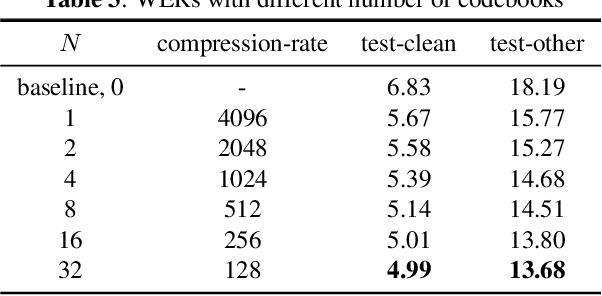
Knowledge distillation(KD) is a common approach to improve model performance in automatic speech recognition (ASR), where a student model is trained to imitate the output behaviour of a teacher model. However, traditional KD methods suffer from teacher label storage issue, especially when the training corpora are large. Although on-the-fly teacher label generation tackles this issue, the training speed is significantly slower as the teacher model has to be evaluated every batch. In this paper, we reformulate the generation of teacher label as a codec problem. We propose a novel Multi-codebook Vector Quantization (MVQ) approach that compresses teacher embeddings to codebook indexes (CI). Based on this, a KD training framework (MVQ-KD) is proposed where a student model predicts the CI generated from the embeddings of a self-supervised pre-trained teacher model. Experiments on the LibriSpeech clean-100 hour show that MVQ-KD framework achieves comparable performance as traditional KD methods (l1, l2), while requiring 256 times less storage. When the full LibriSpeech dataset is used, MVQ-KD framework results in 13.8% and 8.2% relative word error rate reductions (WERRs) for non -streaming transducer on test-clean and test-other and 4.0% and 4.9% for streaming transducer. The implementation of this work is already released as a part of the open-source project icefall.
Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training
Oct 28, 2021
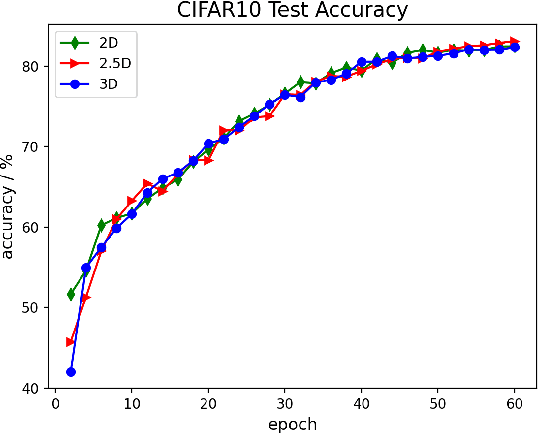
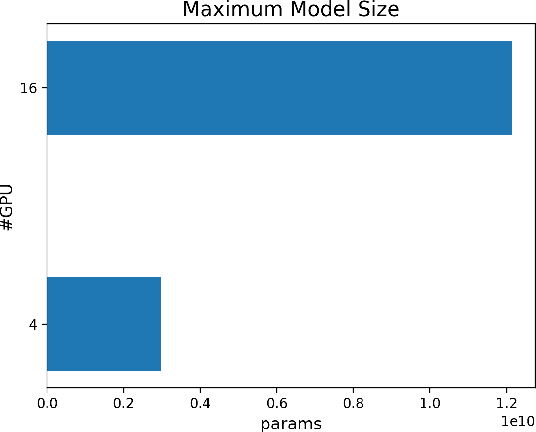
The Transformer architecture has improved the performance of deep learning models in domains such as Computer Vision and Natural Language Processing. Together with better performance come larger model sizes. This imposes challenges to the memory wall of the current accelerator hardware such as GPU. It is never ideal to train large models such as Vision Transformer, BERT, and GPT on a single GPU or a single machine. There is an urgent demand to train models in a distributed environment. However, distributed training, especially model parallelism, often requires domain expertise in computer systems and architecture. It remains a challenge for AI researchers to implement complex distributed training solutions for their models. In this paper, we introduce Colossal-AI, which is a unified parallel training system designed to seamlessly integrate different paradigms of parallelization techniques including data parallelism, pipeline parallelism, multiple tensor parallelism, and sequence parallelism. Colossal-AI aims to support the AI community to write distributed models in the same way as how they write models normally. This allows them to focus on developing the model architecture and separates the concerns of distributed training from the development process. The documentations can be found at https://www.colossalai.org and the source code can be found at https://github.com/hpcaitech/ColossalAI.
Cross-model convolutional neural network for multiple modality data representation
Nov 19, 2016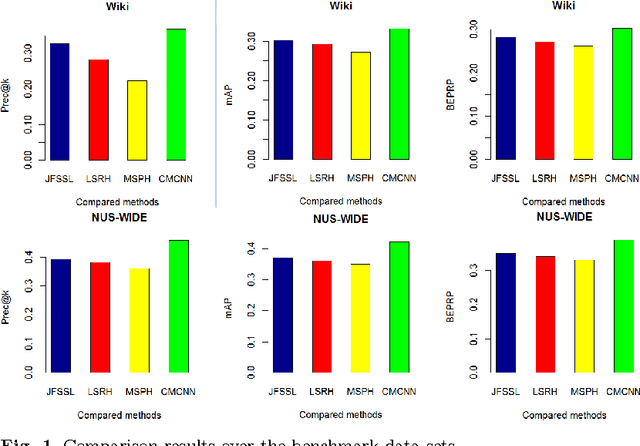
A novel data representation method of convolutional neural net- work (CNN) is proposed in this paper to represent data of different modalities. We learn a CNN model for the data of each modality to map the data of differ- ent modalities to a common space, and regularize the new representations in the common space by a cross-model relevance matrix. We further impose that the class label of data points can also be predicted from the CNN representa- tions in the common space. The learning problem is modeled as a minimiza- tion problem, which is solved by an augmented Lagrange method (ALM) with updating rules of Alternating direction method of multipliers (ADMM). The experiments over benchmark of sequence data of multiple modalities show its advantage.