 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
Mar 12, 2025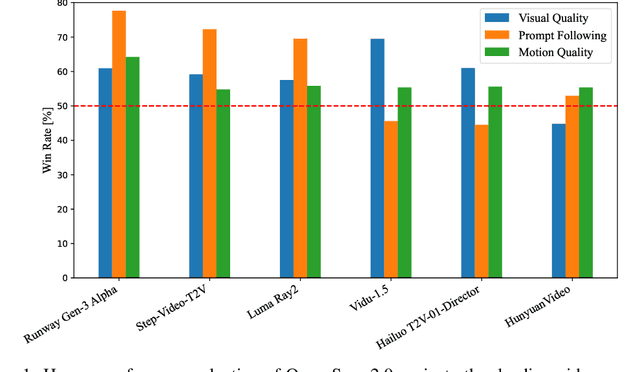

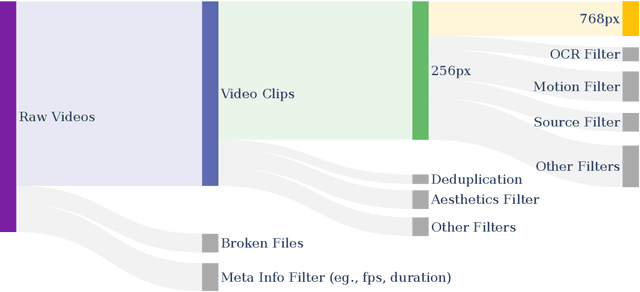

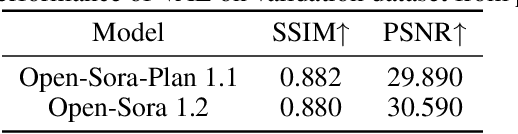
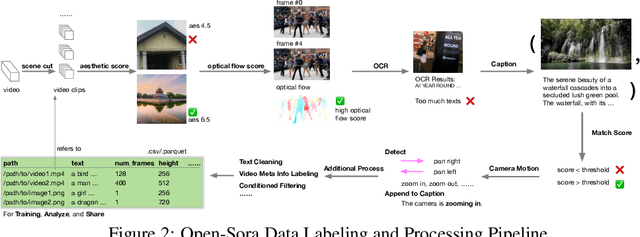
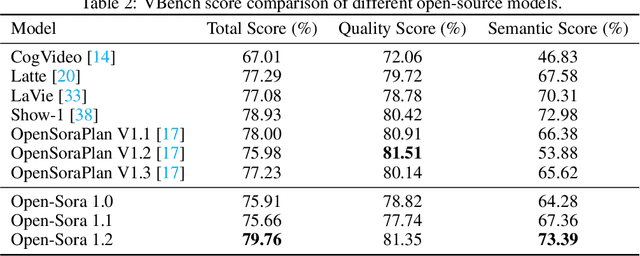
Video generation models have achieved remarkable progress in the past year. The quality of AI video continues to improve, but at the cost of larger model size, increased data quantity, and greater demand for training compute. In this report, we present Open-Sora 2.0, a commercial-level video generation model trained for only $200k. With this model, we demonstrate that the cost of training a top-performing video generation model is highly controllable. We detail all techniques that contribute to this efficiency breakthrough, including data curation, model architecture, training strategy, and system optimization. According to human evaluation results and VBench scores, Open-Sora 2.0 is comparable to global leading video generation models including the open-source HunyuanVideo and the closed-source Runway Gen-3 Alpha. By making Open-Sora 2.0 fully open-source, we aim to democratize access to advanced video generation technology, fostering broader innovation and creativity in content creation. All resources are publicly available at: https://github.com/hpcaitech/Open-Sora.
Open-Sora: Democratizing Efficient Video Production for All
Dec 29, 2024
Vision and language are the two foundational senses for humans, and they build up our cognitive ability and intelligence. While significant breakthroughs have been made in AI language ability, artificial visual intelligence, especially the ability to generate and simulate the world we see, is far lagging behind. To facilitate the development and accessibility of artificial visual intelligence, we created Open-Sora, an open-source video generation model designed to produce high-fidelity video content. Open-Sora supports a wide spectrum of visual generation tasks, including text-to-image generation, text-to-video generation, and image-to-video generation. The model leverages advanced deep learning architectures and training/inference techniques to enable flexible video synthesis, which could generate video content of up to 15 seconds, up to 720p resolution, and arbitrary aspect ratios. Specifically, we introduce Spatial-Temporal Diffusion Transformer (STDiT), an efficient diffusion framework for videos that decouples spatial and temporal attention. We also introduce a highly compressive 3D autoencoder to make representations compact and further accelerate training with an ad hoc training strategy. Through this initiative, we aim to foster innovation, creativity, and inclusivity within the community of AI content creation. By embracing the open-source principle, Open-Sora democratizes full access to all the training/inference/data preparation codes as well as model weights. All resources are publicly available at: https://github.com/hpcaitech/Open-Sora.
RIDE: Boosting 3D Object Detection for LiDAR Point Clouds via Rotation-Invariant Analysis
Aug 29, 2024



The rotation robustness property has drawn much attention to point cloud analysis, whereas it still poses a critical challenge in 3D object detection. When subjected to arbitrary rotation, most existing detectors fail to produce expected outputs due to the poor rotation robustness. In this paper, we present RIDE, a pioneering exploration of Rotation-Invariance for the 3D LiDAR-point-based object DEtector, with the key idea of designing rotation-invariant features from LiDAR scenes and then effectively incorporating them into existing 3D detectors. Specifically, we design a bi-feature extractor that extracts (i) object-aware features though sensitive to rotation but preserve geometry well, and (ii) rotation-invariant features, which lose geometric information to a certain extent but are robust to rotation. These two kinds of features complement each other to decode 3D proposals that are robust to arbitrary rotations. Particularly, our RIDE is compatible and easy to plug into the existing one-stage and two-stage 3D detectors, and boosts both detection performance and rotation robustness. Extensive experiments on the standard benchmarks showcase that the mean average precision (mAP) and rotation robustness can be significantly boosted by integrating with our RIDE, with +5.6% mAP and 53% rotation robustness improvement on KITTI, +5.1% and 28% improvement correspondingly on nuScenes. The code will be available soon.
Elixir: Train a Large Language Model on a Small GPU Cluster
Dec 10, 2022In recent years, the number of parameters of one deep learning (DL) model has been growing much faster than the growth of GPU memory space. People who are inaccessible to a large number of GPUs resort to heterogeneous training systems for storing model parameters in CPU memory. Existing heterogeneous systems are based on parallelization plans in the scope of the whole model. They apply a consistent parallel training method for all the operators in the computation. Therefore, engineers need to pay a huge effort to incorporate a new type of model parallelism and patch its compatibility with other parallelisms. For example, Mixture-of-Experts (MoE) is still incompatible with ZeRO-3 in Deepspeed. Also, current systems face efficiency problems on small scale, since they are designed and tuned for large-scale training. In this paper, we propose Elixir, a new parallel heterogeneous training system, which is designed for efficiency and flexibility. Elixir utilizes memory resources and computing resources of both GPU and CPU. For flexibility, Elixir generates parallelization plans in the granularity of operators. Any new type of model parallelism can be incorporated by assigning a parallel pattern to the operator. For efficiency, Elixir implements a hierarchical distributed memory management scheme to accelerate inter-GPU communications and CPU-GPU data transmissions. As a result, Elixir can train a 30B OPT model on an A100 with 40GB CUDA memory, meanwhile reaching 84% efficiency of Pytorch GPU training. With its super-linear scalability, the training efficiency becomes the same as Pytorch GPU training on multiple GPUs. Also, large MoE models can be trained 5.3x faster than dense models of the same size. Now Elixir is integrated into ColossalAI and is available on its main branch.
Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training
Oct 28, 2021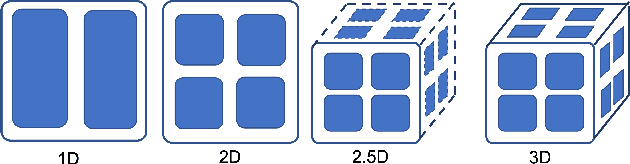
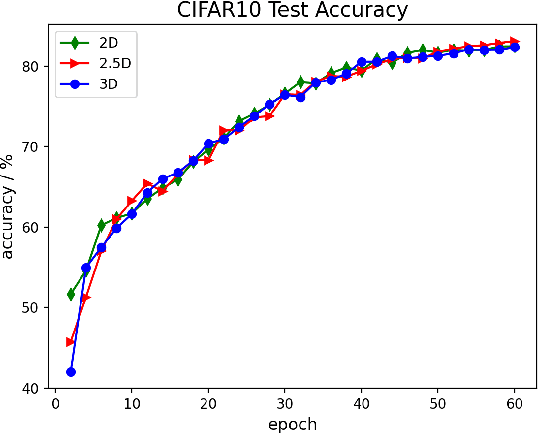
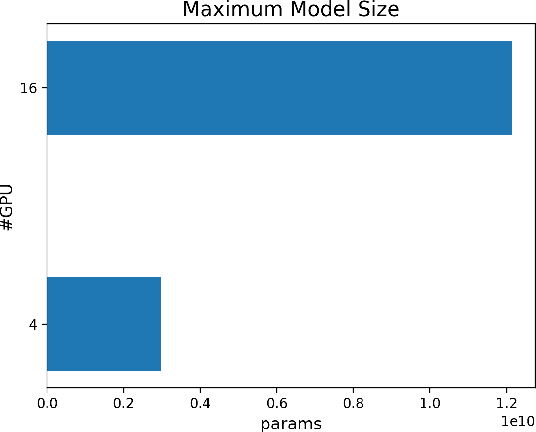
The Transformer architecture has improved the performance of deep learning models in domains such as Computer Vision and Natural Language Processing. Together with better performance come larger model sizes. This imposes challenges to the memory wall of the current accelerator hardware such as GPU. It is never ideal to train large models such as Vision Transformer, BERT, and GPT on a single GPU or a single machine. There is an urgent demand to train models in a distributed environment. However, distributed training, especially model parallelism, often requires domain expertise in computer systems and architecture. It remains a challenge for AI researchers to implement complex distributed training solutions for their models. In this paper, we introduce Colossal-AI, which is a unified parallel training system designed to seamlessly integrate different paradigms of parallelization techniques including data parallelism, pipeline parallelism, multiple tensor parallelism, and sequence parallelism. Colossal-AI aims to support the AI community to write distributed models in the same way as how they write models normally. This allows them to focus on developing the model architecture and separates the concerns of distributed training from the development process. The documentations can be found at https://www.colossalai.org and the source code can be found at https://github.com/hpcaitech/ColossalAI.