 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Urban Network Security Games: Learning Platform, Benchmark, and Challenge for AI Research
Jan 29, 2025



After the great achievement of solving two-player zero-sum games, more and more AI researchers focus on solving multiplayer games. To facilitate the development of designing efficient learning algorithms for solving multiplayer games, we propose a multiplayer game platform for solving Urban Network Security Games (\textbf{UNSG}) that model real-world scenarios. That is, preventing criminal activity is a highly significant responsibility assigned to police officers in cities, and police officers have to allocate their limited security resources to interdict the escaping criminal when a crime takes place in a city. This interaction between multiple police officers and the escaping criminal can be modeled as a UNSG. The variants of UNSGs can model different real-world settings, e.g., whether real-time information is available or not, and whether police officers can communicate or not. The main challenges of solving this game include the large size of the game and the co-existence of cooperation and competition. While previous efforts have been made to tackle UNSGs, they have been hampered by performance and scalability issues. Therefore, we propose an open-source UNSG platform (\textbf{GraphChase}) for designing efficient learning algorithms for solving UNSGs. Specifically, GraphChase offers a unified and flexible game environment for modeling various variants of UNSGs, supporting the development, testing, and benchmarking of algorithms. We believe that GraphChase not only facilitates the development of efficient algorithms for solving real-world problems but also paves the way for significant advancements in algorithmic development for solving general multiplayer games.
Open-Sora: Democratizing Efficient Video Production for All
Dec 29, 2024
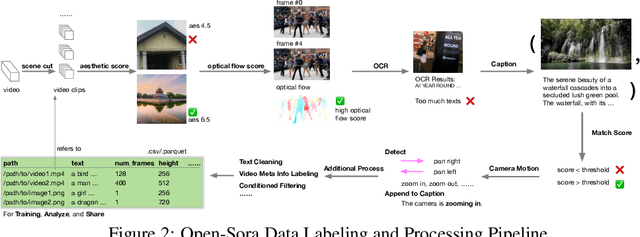
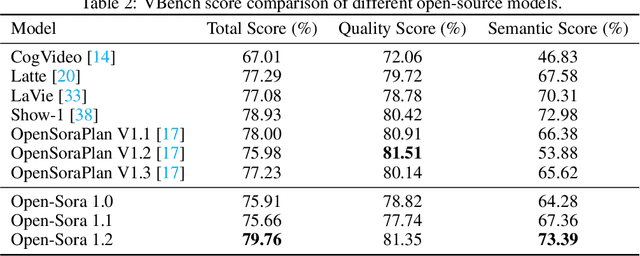
Vision and language are the two foundational senses for humans, and they build up our cognitive ability and intelligence. While significant breakthroughs have been made in AI language ability, artificial visual intelligence, especially the ability to generate and simulate the world we see, is far lagging behind. To facilitate the development and accessibility of artificial visual intelligence, we created Open-Sora, an open-source video generation model designed to produce high-fidelity video content. Open-Sora supports a wide spectrum of visual generation tasks, including text-to-image generation, text-to-video generation, and image-to-video generation. The model leverages advanced deep learning architectures and training/inference techniques to enable flexible video synthesis, which could generate video content of up to 15 seconds, up to 720p resolution, and arbitrary aspect ratios. Specifically, we introduce Spatial-Temporal Diffusion Transformer (STDiT), an efficient diffusion framework for videos that decouples spatial and temporal attention. We also introduce a highly compressive 3D autoencoder to make representations compact and further accelerate training with an ad hoc training strategy. Through this initiative, we aim to foster innovation, creativity, and inclusivity within the community of AI content creation. By embracing the open-source principle, Open-Sora democratizes full access to all the training/inference/data preparation codes as well as model weights. All resources are publicly available at: https://github.com/hpcaitech/Open-Sora.
Rethinking Data Shapley for Data Selection Tasks: Misleads and Merits
May 06, 2024



Data Shapley provides a principled approach to data valuation and plays a crucial role in data-centric machine learning (ML) research. Data selection is considered a standard application of Data Shapley. However, its data selection performance has shown to be inconsistent across settings in the literature. This study aims to deepen our understanding of this phenomenon. We introduce a hypothesis testing framework and show that Data Shapley's performance can be no better than random selection without specific constraints on utility functions. We identify a class of utility functions, monotonically transformed modular functions, within which Data Shapley optimally selects data. Based on this insight, we propose a heuristic for predicting Data Shapley's effectiveness in data selection tasks. Our experiments corroborate these findings, adding new insights into when Data Shapley may or may not succeed.