 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting and improving test-time scaling laws via reward tail-guided search
Feb 01, 2026Test-time scaling has emerged as a critical avenue for enhancing the reasoning capabilities of Large Language Models (LLMs). Though the straight-forward ''best-of-$N$'' (BoN) strategy has already demonstrated significant improvements in performance, it lacks principled guidance on the choice of $N$, budget allocation, and multi-stage decision-making, thereby leaving substantial room for optimization. While many works have explored such optimization, rigorous theoretical guarantees remain limited. In this work, we propose new methodologies to predict and improve scaling properties via tail-guided search. By estimating the tail distribution of rewards, our method predicts the scaling law of LLMs without the need for exhaustive evaluations. Leveraging this prediction tool, we introduce Scaling-Law Guided (SLG) Search, a new test-time algorithm that dynamically allocates compute to identify and exploit intermediate states with the highest predicted potential. We theoretically prove that SLG achieves vanishing regret compared to perfect-information oracles, and achieves expected rewards that would otherwise require a polynomially larger compute budget required when using BoN. Empirically, we validate our framework across different LLMs and reward models, confirming that tail-guided allocation consistently achieves higher reward yields than Best-of-$N$ under identical compute budgets. Our code is available at https://github.com/PotatoJnny/Scaling-Law-Guided-search.
Reheated Gradient-based Discrete Sampling for Combinatorial Optimization
Mar 06, 2025



Recently, gradient-based discrete sampling has emerged as a highly efficient, general-purpose solver for various combinatorial optimization (CO) problems, achieving performance comparable to or surpassing the popular data-driven approaches. However, we identify a critical issue in these methods, which we term ''wandering in contours''. This behavior refers to sampling new different solutions that share very similar objective values for a long time, leading to computational inefficiency and suboptimal exploration of potential solutions. In this paper, we introduce a novel reheating mechanism inspired by the concept of critical temperature and specific heat in physics, aimed at overcoming this limitation. Empirically, our method demonstrates superiority over existing sampling-based and data-driven algorithms across a diverse array of CO problems.
Solving Urban Network Security Games: Learning Platform, Benchmark, and Challenge for AI Research
Jan 29, 2025



After the great achievement of solving two-player zero-sum games, more and more AI researchers focus on solving multiplayer games. To facilitate the development of designing efficient learning algorithms for solving multiplayer games, we propose a multiplayer game platform for solving Urban Network Security Games (\textbf{UNSG}) that model real-world scenarios. That is, preventing criminal activity is a highly significant responsibility assigned to police officers in cities, and police officers have to allocate their limited security resources to interdict the escaping criminal when a crime takes place in a city. This interaction between multiple police officers and the escaping criminal can be modeled as a UNSG. The variants of UNSGs can model different real-world settings, e.g., whether real-time information is available or not, and whether police officers can communicate or not. The main challenges of solving this game include the large size of the game and the co-existence of cooperation and competition. While previous efforts have been made to tackle UNSGs, they have been hampered by performance and scalability issues. Therefore, we propose an open-source UNSG platform (\textbf{GraphChase}) for designing efficient learning algorithms for solving UNSGs. Specifically, GraphChase offers a unified and flexible game environment for modeling various variants of UNSGs, supporting the development, testing, and benchmarking of algorithms. We believe that GraphChase not only facilitates the development of efficient algorithms for solving real-world problems but also paves the way for significant advancements in algorithmic development for solving general multiplayer games.
Continuous sPatial-Temporal Deformable Image Registration (CPT-DIR) for motion modelling in radiotherapy: beyond classic voxel-based methods
May 01, 2024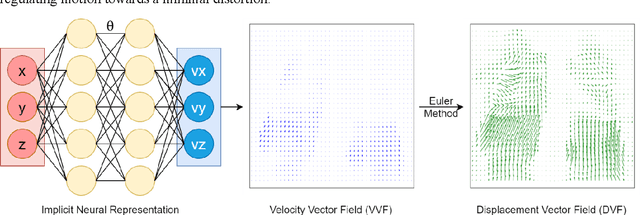
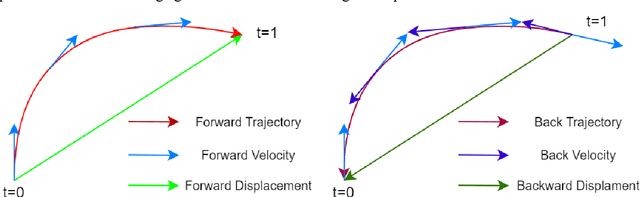

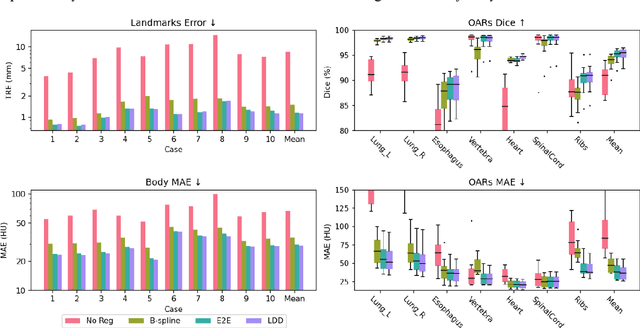
Background and purpose: Deformable image registration (DIR) is a crucial tool in radiotherapy for extracting and modelling organ motion. However, when significant changes and sliding boundaries are present, it faces compromised accuracy and uncertainty, determining the subsequential contour propagation and dose accumulation procedures. Materials and methods: We propose an implicit neural representation (INR)-based approach modelling motion continuously in both space and time, named Continues-sPatial-Temporal DIR (CPT-DIR). This method uses a multilayer perception (MLP) network to map 3D coordinate (x,y,z) to its corresponding velocity vector (vx,vy,vz). The displacement vectors (dx,dy,dz) are then calculated by integrating velocity vectors over time. The MLP's parameters can rapidly adapt to new cases without pre-training, enhancing optimisation. The DIR's performance was tested on the DIR-Lab dataset of 10 lung 4DCT cases, using metrics of landmark accuracy (TRE), contour conformity (Dice) and image similarity (MAE). Results: The proposed CPT-DIR can reduce landmark TRE from 2.79mm to 0.99mm, outperforming B-splines' results for all cases. The MAE of the whole-body region improves from 35.46HU to 28.99HU. Furthermore, CPT-DIR surpasses B-splines for accuracy in the sliding boundary region, lowering MAE and increasing Dice coefficients for the ribcage from 65.65HU and 90.41% to 42.04HU and 90.56%, versus 75.40HU and 89.30% without registration. Meanwhile, CPT-DIR offers significant speed advantages, completing in under 15 seconds compared to a few minutes with the conventional B-splines method. Conclusion: Leveraging the continuous representations, the CPT-DIR method significantly enhances registration accuracy, automation and speed, outperforming traditional B-splines in landmark and contour precision, particularly in the challenging areas.
Diffusion Schrödinger Bridge Models for High-Quality MR-to-CT Synthesis for Head and Neck Proton Treatment Planning
Apr 17, 2024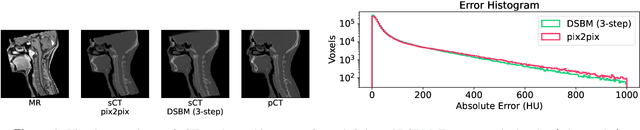

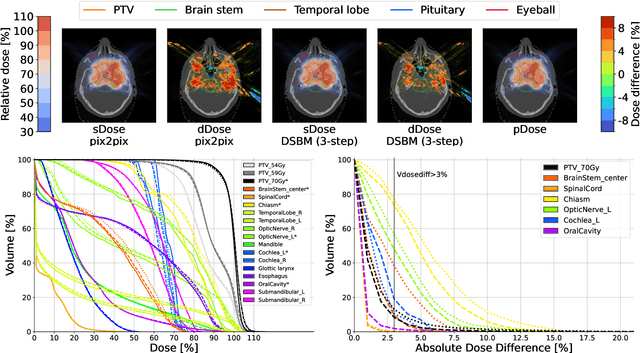
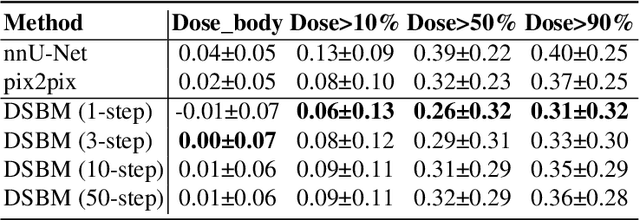
In recent advancements in proton therapy, MR-based treatment planning is gaining momentum to minimize additional radiation exposure compared to traditional CT-based methods. This transition highlights the critical need for accurate MR-to-CT image synthesis, which is essential for precise proton dose calculations. Our research introduces the Diffusion Schr\"odinger Bridge Models (DSBM), an innovative approach for high-quality MR-to-CT synthesis. DSBM learns the nonlinear diffusion processes between MR and CT data distributions. This method improves upon traditional diffusion models by initiating synthesis from the prior distribution rather than the Gaussian distribution, enhancing both generation quality and efficiency. We validated the effectiveness of DSBM on a head and neck cancer dataset, demonstrating its superiority over traditional image synthesis methods through both image-level and dosimetric-level evaluations. The effectiveness of DSBM in MR-based proton treatment planning highlights its potential as a valuable tool in various clinical scenarios.
Learning Dual-Level Deformable Implicit Representation for Real-World Scale Arbitrary Super-Resolution
Mar 16, 2024



Scale arbitrary super-resolution based on implicit image function gains increasing popularity since it can better represent the visual world in a continuous manner. However, existing scale arbitrary works are trained and evaluated on simulated datasets, where low-resolution images are generated from their ground truths by the simplest bicubic downsampling. These models exhibit limited generalization to real-world scenarios due to the greater complexity of real-world degradations. To address this issue, we build a RealArbiSR dataset, a new real-world super-resolution benchmark with both integer and non-integer scaling factors for the training and evaluation of real-world scale arbitrary super-resolution. Moreover, we propose a Dual-level Deformable Implicit Representation (DDIR) to solve real-world scale arbitrary super-resolution. Specifically, we design the appearance embedding and deformation field to handle both image-level and pixel-level deformations caused by real-world degradations. The appearance embedding models the characteristics of low-resolution inputs to deal with photometric variations at different scales, and the pixel-based deformation field learns RGB differences which result from the deviations between the real-world and simulated degradations at arbitrary coordinates. Extensive experiments show our trained model achieves state-of-the-art performance on the RealArbiSR and RealSR benchmarks for real-world scale arbitrary super-resolution. Our dataset as well as source code will be publicly available.
Neural Graphics Primitives-based Deformable Image Registration for On-the-fly Motion Extraction
Feb 08, 2024Intra-fraction motion in radiotherapy is commonly modeled using deformable image registration (DIR). However, existing methods often struggle to balance speed and accuracy, limiting their applicability in clinical scenarios. This study introduces a novel approach that harnesses Neural Graphics Primitives (NGP) to optimize the displacement vector field (DVF). Our method leverages learned primitives, processed as splats, and interpolates within space using a shallow neural network. Uniquely, it enables self-supervised optimization at an ultra-fast speed, negating the need for pre-training on extensive datasets and allowing seamless adaptation to new cases. We validated this approach on the 4D-CT lung dataset DIR-lab, achieving a target registration error (TRE) of 1.15\pm1.15 mm within a remarkable time of 1.77 seconds. Notably, our method also addresses the sliding boundary problem, a common challenge in conventional DIR methods.
Skip-Plan: Procedure Planning in Instructional Videos via Condensed Action Space Learning
Oct 01, 2023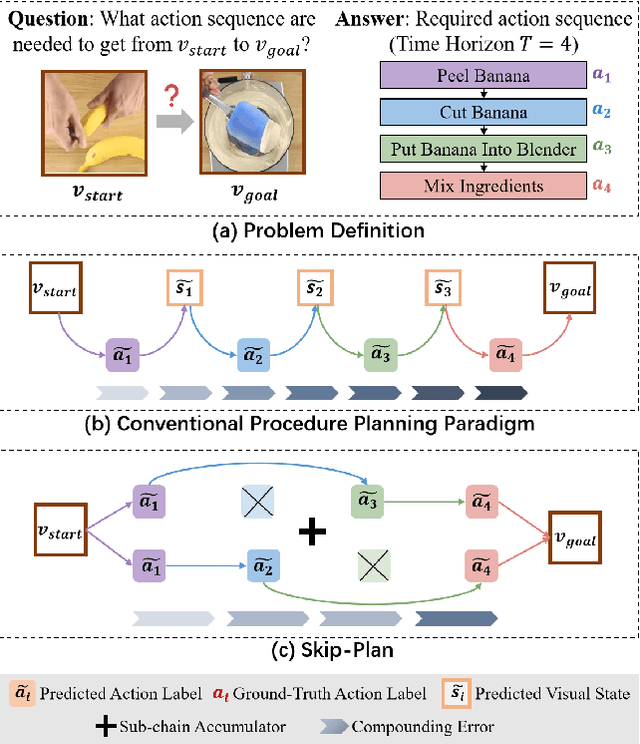
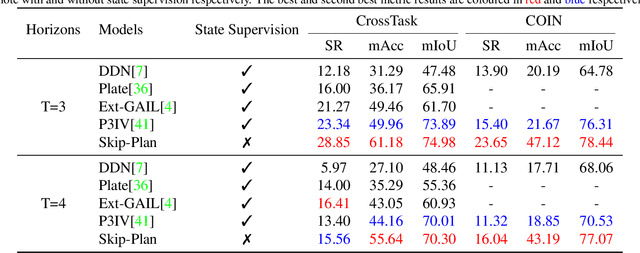
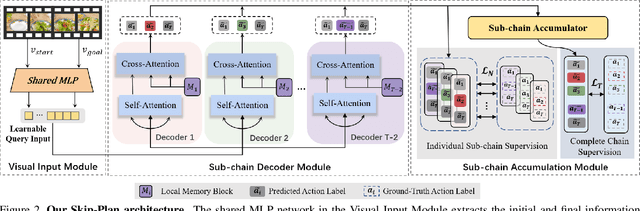

In this paper, we propose Skip-Plan, a condensed action space learning method for procedure planning in instructional videos. Current procedure planning methods all stick to the state-action pair prediction at every timestep and generate actions adjacently. Although it coincides with human intuition, such a methodology consistently struggles with high-dimensional state supervision and error accumulation on action sequences. In this work, we abstract the procedure planning problem as a mathematical chain model. By skipping uncertain nodes and edges in action chains, we transfer long and complex sequence functions into short but reliable ones in two ways. First, we skip all the intermediate state supervision and only focus on action predictions. Second, we decompose relatively long chains into multiple short sub-chains by skipping unreliable intermediate actions. By this means, our model explores all sorts of reliable sub-relations within an action sequence in the condensed action space. Extensive experiments show Skip-Plan achieves state-of-the-art performance on the CrossTask and COIN benchmarks for procedure planning.
Diffusion-SDF: Text-to-Shape via Voxelized Diffusion
Dec 06, 2022

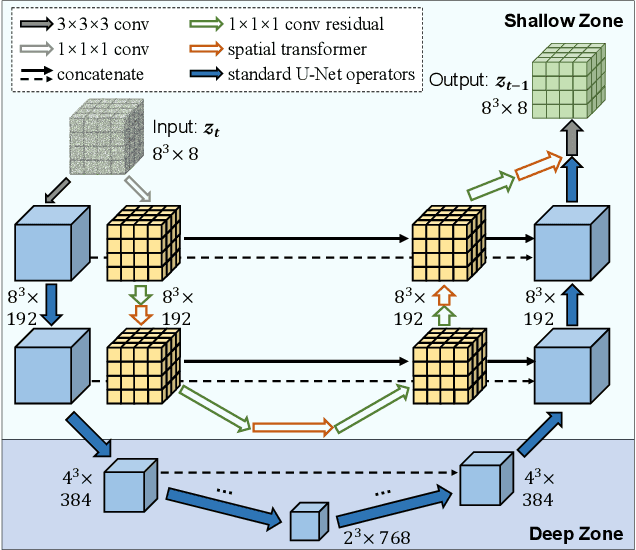

With the rising industrial attention to 3D virtual modeling technology, generating novel 3D content based on specified conditions (e.g. text) has become a hot issue. In this paper, we propose a new generative 3D modeling framework called Diffusion-SDF for the challenging task of text-to-shape synthesis. Previous approaches lack flexibility in both 3D data representation and shape generation, thereby failing to generate highly diversified 3D shapes conforming to the given text descriptions. To address this, we propose a SDF autoencoder together with the Voxelized Diffusion model to learn and generate representations for voxelized signed distance fields (SDFs) of 3D shapes. Specifically, we design a novel UinU-Net architecture that implants a local-focused inner network inside the standard U-Net architecture, which enables better reconstruction of patch-independent SDF representations. We extend our approach to further text-to-shape tasks including text-conditioned shape completion and manipulation. Experimental results show that Diffusion-SDF is capable of generating both high-quality and highly diversified 3D shapes that conform well to the given text descriptions. Diffusion-SDF has demonstrated its superiority compared to previous state-of-the-art text-to-shape approaches.
Bridge-Prompt: Towards Ordinal Action Understanding in Instructional Videos
Mar 26, 2022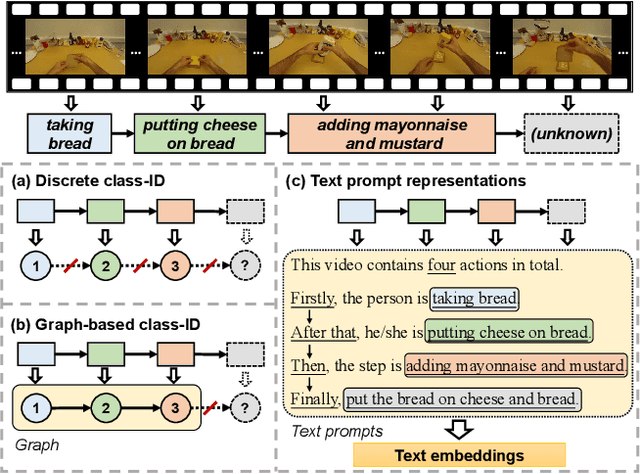
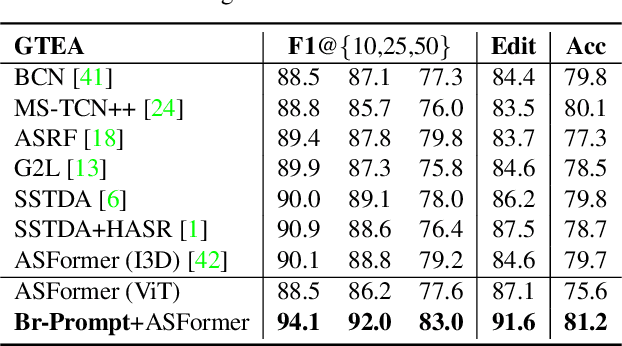
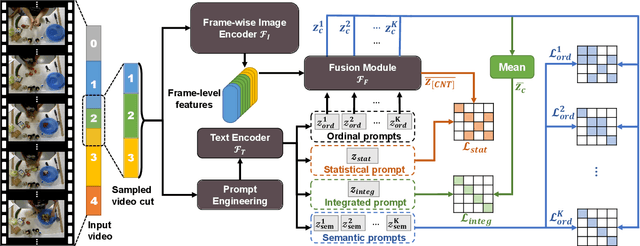
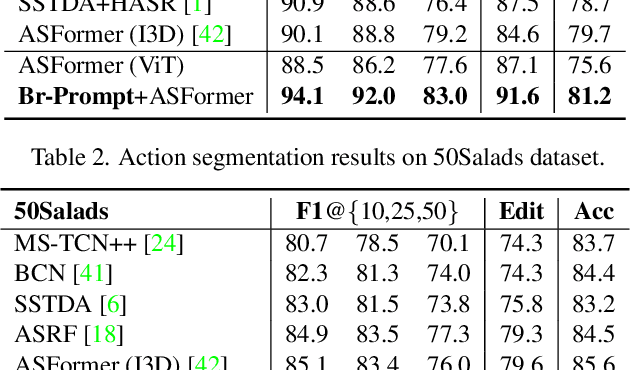
Action recognition models have shown a promising capability to classify human actions in short video clips. In a real scenario, multiple correlated human actions commonly occur in particular orders, forming semantically meaningful human activities. Conventional action recognition approaches focus on analyzing single actions. However, they fail to fully reason about the contextual relations between adjacent actions, which provide potential temporal logic for understanding long videos. In this paper, we propose a prompt-based framework, Bridge-Prompt (Br-Prompt), to model the semantics across adjacent actions, so that it simultaneously exploits both out-of-context and contextual information from a series of ordinal actions in instructional videos. More specifically, we reformulate the individual action labels as integrated text prompts for supervision, which bridge the gap between individual action semantics. The generated text prompts are paired with corresponding video clips, and together co-train the text encoder and the video encoder via a contrastive approach. The learned vision encoder has a stronger capability for ordinal-action-related downstream tasks, e.g. action segmentation and human activity recognition. We evaluate the performances of our approach on several video datasets: Georgia Tech Egocentric Activities (GTEA), 50Salads, and the Breakfast dataset. Br-Prompt achieves state-of-the-art on multiple benchmarks. Code is available at https://github.com/ttlmh/Bridge-Prompt