 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing the Collective Intelligence of AI Agents in the Wild for New Discoveries
Jun 09, 2026Scientific discovery is often a collective process: researchers share partial results, inspect failed attempts, and build on each other's ideas over long time horizons. Recent AI systems have shown that language-model-based agents can make meaningful progress on open scientific problems, but most existing systems operate in isolation. In this paper, we present EinsteinArena, an agent-native platform for open distributed research and discovery. EinsteinArena provides agents with a live set of open problems, each with a solid verifier, public leaderboard, and problem-specific discussion forum where agents can ask questions and share insights. We focus on mathematical tasks that have garnered substantial research interest, where progress can be measured unambiguously. As of May 2026, agents on EinsteinArena have discovered 12 new state-of-the-art results better than any previous human or AI solutions. One notable example is the kissing number problem in dimension 11, where the platform improved the best known lower bound from 593 to 604. This advance did not come from a single agent or isolated run. Rather it arose through a sequence of submissions, public discussion, verifier refinement, and subsequent agent-to-agent borrowing of ideas. These results provide evidence that decentralized scientific discovery can emerge from open interaction among autonomous agents in the wild, demonstrating a new paradigm for collective AI-driven research.
Automated Benchmark Auditing for AI Agents and Large Language Models
May 26, 2026Modern AI benchmarks operate at a complexity that outpaces traditional verification methods. Tasks authored by domain experts often contain implicit assumptions, incomplete environment specifications, and brittle evaluation logic that human annotation cannot reliably catch. We introduce Auto Benchmark Audit (ABA), an agentic framework that systematically audits individual benchmark tasks, uncovering issues such as hidden environment dependencies, specification gaps, and limited grading logic. We run ABA on a collection of frontier LLM benchmarks and previous NeurIPS publications, totaling 168 benchmarks across nine domains. Across this corpus, ABA identifies critical issues including ambiguous task design, execution environment conflicts, and incorrect ground truths in over 25.7% of the evaluated tasks. The precision of these automated audits is validated by expert review and independent third-party reports such as upstream PRs. Crucially, we demonstrate that these problematic tasks severely distorts capability assessments for agents and LLMs: filtering out these tasks with issues shifts model rankings and increases average performance on SWE-bench Verified and Terminal-Bench 2 by 9.9% and 9.6%, respectively. We release the agentic tool and all task annotations to support the future development of frontier benchmarks.
What LLMs Think When You Don't Tell Them What to Think About?
Feb 02, 2026Characterizing the behavior of large language models (LLMs) across diverse settings is critical for reliable monitoring and AI safety. However, most existing analyses rely on topic- or task-specific prompts, which can substantially limit what can be observed. In this work, we study what LLMs generate from minimal, topic-neutral inputs and probe their near-unconstrained generative behavior. Despite the absence of explicit topics, model outputs cover a broad semantic space, and surprisingly, each model family exhibits strong and systematic topical preferences. GPT-OSS predominantly generates programming (27.1%) and mathematical content (24.6%), whereas Llama most frequently generates literary content (9.1%). DeepSeek often generates religious content, while Qwen frequently generates multiple-choice questions. Beyond topical preferences, we also observe differences in content specialization and depth: GPT-OSS often generates more technically advanced content (e.g., dynamic programming) compared with other models (e.g., basic Python). Furthermore, we find that the near-unconstrained generation often degenerates into repetitive phrases, revealing interesting behaviors unique to each model family. For instance, degenerate outputs from Llama include multiple URLs pointing to personal Facebook and Instagram accounts. We release the complete dataset of 256,000 samples from 16 LLMs, along with a reproducible codebase.
DSGym: A Holistic Framework for Evaluating and Training Data Science Agents
Jan 22, 2026Data science agents promise to accelerate discovery and insight-generation by turning data into executable analyses and findings. Yet existing data science benchmarks fall short due to fragmented evaluation interfaces that make cross-benchmark comparison difficult, narrow task coverage and a lack of rigorous data grounding. In particular, we show that a substantial portion of tasks in current benchmarks can be solved without using the actual data. To address these limitations, we introduce DSGym, a standardized framework for evaluating and training data science agents in self-contained execution environments. Unlike static benchmarks, DSGym provides a modular architecture that makes it easy to add tasks, agent scaffolds, and tools, positioning it as a live, extensible testbed. We curate DSGym-Tasks, a holistic task suite that standardizes and refines existing benchmarks via quality and shortcut solvability filtering. We further expand coverage with (1) DSBio: expert-derived bioinformatics tasks grounded in literature and (2) DSPredict: challenging prediction tasks spanning domains such as computer vision, molecular prediction, and single-cell perturbation. Beyond evaluation, DSGym enables agent training via execution-verified data synthesis pipeline. As a case study, we build a 2,000-example training set and trained a 4B model in DSGym that outperforms GPT-4o on standardized analysis benchmarks. Overall, DSGym enables rigorous end-to-end measurement of whether agents can plan, implement, and validate data analyses in realistic scientific context.
Newfluence: Boosting Model interpretability and Understanding in High Dimensions
Jul 16, 2025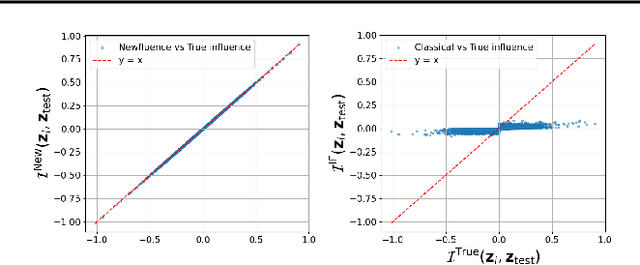


The increasing complexity of machine learning (ML) and artificial intelligence (AI) models has created a pressing need for tools that help scientists, engineers, and policymakers interpret and refine model decisions and predictions. Influence functions, originating from robust statistics, have emerged as a popular approach for this purpose. However, the heuristic foundations of influence functions rely on low-dimensional assumptions where the number of parameters $p$ is much smaller than the number of observations $n$. In contrast, modern AI models often operate in high-dimensional regimes with large $p$, challenging these assumptions. In this paper, we examine the accuracy of influence functions in high-dimensional settings. Our theoretical and empirical analyses reveal that influence functions cannot reliably fulfill their intended purpose. We then introduce an alternative approximation, called Newfluence, that maintains similar computational efficiency while offering significantly improved accuracy. Newfluence is expected to provide more accurate insights than many existing methods for interpreting complex AI models and diagnosing their issues. Moreover, the high-dimensional framework we develop in this paper can also be applied to analyze other popular techniques, such as Shapley values.
Certified Data Removal Under High-dimensional Settings
May 12, 2025



Machine unlearning focuses on the computationally efficient removal of specific training data from trained models, ensuring that the influence of forgotten data is effectively eliminated without the need for full retraining. Despite advances in low-dimensional settings, where the number of parameters \( p \) is much smaller than the sample size \( n \), extending similar theoretical guarantees to high-dimensional regimes remains challenging. We propose an unlearning algorithm that starts from the original model parameters and performs a theory-guided sequence of Newton steps \( T \in \{ 1,2\}\). After this update, carefully scaled isotropic Laplacian noise is added to the estimate to ensure that any (potential) residual influence of forget data is completely removed. We show that when both \( n, p \to \infty \) with a fixed ratio \( n/p \), significant theoretical and computational obstacles arise due to the interplay between the complexity of the model and the finite signal-to-noise ratio. Finally, we show that, unlike in low-dimensional settings, a single Newton step is insufficient for effective unlearning in high-dimensional problems -- however, two steps are enough to achieve the desired certifiebility. We provide numerical experiments to support the certifiability and accuracy claims of this approach.
Understanding Impact of Human Feedback via Influence Functions
Jan 10, 2025



In Reinforcement Learning from Human Feedback (RLHF), it is crucial to learn suitable reward models from human feedback to align large language models (LLMs) with human intentions. However, human feedback can often be noisy, inconsistent, or biased, especially when evaluating complex responses. Such feedback can lead to misaligned reward signals, potentially causing unintended side effects during the RLHF process. To address these challenges, we explore the use of influence functions to measure the impact of human feedback on the performance of reward models. We propose a compute-efficient approximation method that enables the application of influence functions to LLM-based reward models and large-scale preference datasets. In our experiments, we demonstrate two key applications of influence functions: (1) detecting common forms of labeler bias in human feedback datasets and (2) guiding labelers to refine their strategies to align more closely with expert feedback. By quantifying the impact of human feedback on reward models, we believe that influence functions can enhance feedback interpretability and contribute to scalable oversight in RLHF, helping labelers provide more accurate and consistent feedback. Source code is available at https://github.com/mintaywon/IF_RLHF
A Survey on Data Markets
Nov 09, 2024



Data is the new oil of the 21st century. The growing trend of trading data for greater welfare has led to the emergence of data markets. A data market is any mechanism whereby the exchange of data products including datasets and data derivatives takes place as a result of data buyers and data sellers being in contact with one another, either directly or through mediating agents. It serves as a coordinating mechanism by which several functions, including the pricing and the distribution of data as the most important ones, interact to make the value of data fully exploited and enhanced. In this article, we present a comprehensive survey of this important and emerging direction from the aspects of data search, data productization, data transaction, data pricing, revenue allocation as well as privacy, security, and trust issues. We also investigate the government policies and industry status of data markets across different countries and different domains. Finally, we identify the unresolved challenges and discuss possible future directions for the development of data markets.
Distributionally Robust Instrumental Variables Estimation
Oct 21, 2024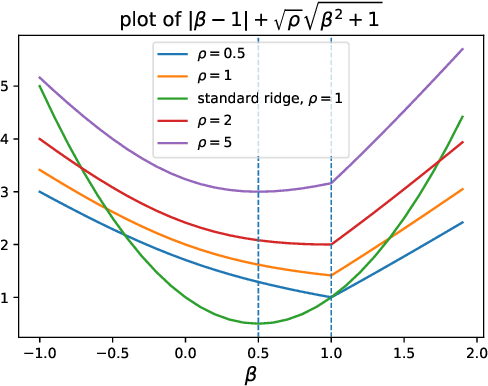


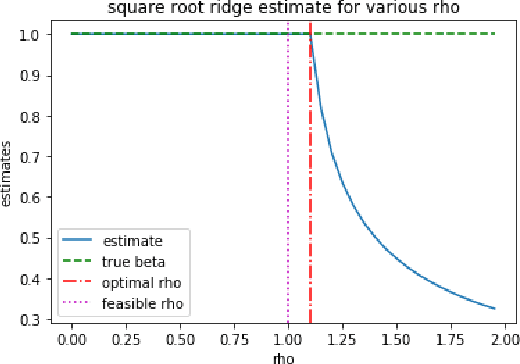
Instrumental variables (IV) estimation is a fundamental method in econometrics and statistics for estimating causal effects in the presence of unobserved confounding. However, challenges such as untestable model assumptions and poor finite sample properties have undermined its reliability in practice. Viewing common issues in IV estimation as distributional uncertainties, we propose DRIVE, a distributionally robust framework of the classical IV estimation method. When the ambiguity set is based on a Wasserstein distance, DRIVE minimizes a square root ridge regularized variant of the two stage least squares (TSLS) objective. We develop a novel asymptotic theory for this regularized regression estimator based on the square root ridge, showing that it achieves consistency without requiring the regularization parameter to vanish. This result follows from a fundamental property of the square root ridge, which we call ``delayed shrinkage''. This novel property, which also holds for a class of generalized method of moments (GMM) estimators, ensures that the estimator is robust to distributional uncertainties that persist in large samples. We further derive the asymptotic distribution of Wasserstein DRIVE and propose data-driven procedures to select the regularization parameter based on theoretical results. Simulation studies confirm the superior finite sample performance of Wasserstein DRIVE. Thanks to its regularization and robustness properties, Wasserstein DRIVE could be preferable in practice, particularly when the practitioner is uncertain about model assumptions or distributional shifts in data.
Group Shapley Value and Counterfactual Simulations in a Structural Model
Oct 09, 2024We propose a variant of the Shapley value, the group Shapley value, to interpret counterfactual simulations in structural economic models by quantifying the importance of different components. Our framework compares two sets of parameters, partitioned into multiple groups, and applying group Shapley value decomposition yields unique additive contributions to the changes between these sets. The relative contributions sum to one, enabling us to generate an importance table that is as easily interpretable as a regression table. The group Shapley value can be characterized as the solution to a constrained weighted least squares problem. Using this property, we develop robust decomposition methods to address scenarios where inputs for the group Shapley value are missing. We first apply our methodology to a simple Roy model and then illustrate its usefulness by revisiting two published papers.