 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Generalist Agents Automate Data Curation?
Jun 02, 2026Curating training data is among the most consequential yet labor-intensive parts of modern AI development: practitioners iteratively propose, implement, evaluate, and revise data policies against noisy benchmark feedback. We ask whether generalist coding agents can automate this data-curation loop. We introduce *Curation-Bench*, an agent-centric benchmark that fixes the model, training recipe, and evaluation suite while giving agents command-line access to inspect data, implement policies, submit them to a fixed training/evaluation pipeline, and revise. In a vision-language instruction-tuning instantiation, out-of-the-box agents reach strong published data-selection baselines within ten iterations. However, trajectory analysis reveals a persistent *execution-research gap*: agents mainly tune local policy variants rather than explore new policy families, even when given strategy guides and paper references. Scaffolds requiring each iteration to cite, instantiate, and adapt a prior method shift agents toward method-guided exploration. The scaffolded agent autonomously composes -- without human design input -- a data-selection policy that outperforms strong published baselines at one-tenth their data budget. Overall, current agents can run the curation loop, but reliable data research requires scaffolded method adaptation, not open-ended prompting alone. Code and benchmark are open-sourced.
Characterizing Model-Native Skills
Apr 19, 2026Skills are a natural unit for describing what a language model can do and how its behavior can be changed. However, existing characterizations rely on human-written taxonomies, textual descriptions, or manual profiling pipelines--all external hypotheses about what matters that need not align with the model's internal representations. We argue that when the goal is to intervene on model behavior, skill characterization should be *model-native*: grounded in the model's own representations rather than imposed through external ontologies. We instantiate this view by recovering a compact orthogonal basis from sequence-level activations. The resulting basis is semantically interpretable but need not correspond to any predefined human ontology; instead, it captures axes of behavioral variation that the model itself organizes around. We validate this characterization on reasoning post-training, using the recovered basis for both SFT data selection and inference-time steering. We develop lightweight proxy interventions to identify which directions are most useful for a given model. Across Llama3-8B and Qwen2.5-3B, selecting data along those directions improves Pass@1 by up to 20% on MATH and 41% on AMC, outperforming data selection based on human-characterized skills. Because the basis lives in activation space, the same directions also serve as steering vectors at inference time, improving Pass@8 by up to 4.8% on MATH--an intervention that human-characterized skills cannot support. We further validate the characterization on safety alignment, where selecting adversarial training data for model-native skill coverage rather than textual diversity yields more sample-efficient learning. These results suggest that recovering skills from the model's own representations, rather than imposing them externally, provides a more effective foundation for intervening on model behavior. Codes are open-sourced.
A Sustainable AI Economy Needs Data Deals That Work for Generators
Jan 15, 2026We argue that the machine learning value chain is structurally unsustainable due to an economic data processing inequality: each state in the data cycle from inputs to model weights to synthetic outputs refines technical signal but strips economic equity from data generators. We show, by analyzing seventy-three public data deals, that the majority of value accrues to aggregators, with documented creator royalties rounding to zero and widespread opacity of deal terms. This is not just an economic welfare concern: as data and its derivatives become economic assets, the feedback loop that sustains current learning algorithms is at risk. We identify three structural faults - missing provenance, asymmetric bargaining power, and non-dynamic pricing - as the operational machinery of this inequality. In our analysis, we trace these problems along the machine learning value chain and propose an Equitable Data-Value Exchange (EDVEX) Framework to enable a minimal market that benefits all participants. Finally, we outline research directions where our community can make concrete contributions to data deals and contextualize our position with related and orthogonal viewpoints.
Quagmires in SFT-RL Post-Training: When High SFT Scores Mislead and What to Use Instead
Oct 02, 2025In post-training for reasoning Large Language Models (LLMs), the current state of practice trains LLMs in two independent stages: Supervised Fine-Tuning (SFT) and Reinforcement Learning with Verifiable Rewards (RLVR, shortened as ``RL'' below). In this work, we challenge whether high SFT scores translate to improved performance after RL. We provide extensive counter-examples where this is not true. We find high SFT scores can be biased toward simpler or more homogeneous data and are not reliably predictive of subsequent RL gains or scaled-up post-training effectiveness. In some cases, RL training on models with improved SFT performance could lead to substantially worse outcome compared to RL on the base model without SFT. We study alternative metrics and identify generalization loss on held-out reasoning examples and Pass@large k performance to provide strong proxies for the RL outcome. We trained hundreds of models up to 12B-parameter with SFT and RLVR via GRPO and ran extensive evaluations on 7 math benchmarks with up to 256 repetitions, spending $>$1M GPU hours. Experiments include models from Llama3, Mistral-Nemo, Qwen3 and multiple state-of-the-art SFT/RL datasets. Compared to directly predicting from pre-RL performance, prediction based on generalization loss and Pass@large k achieves substantial higher precision, improving $R^2$ coefficient and Spearman's rank correlation coefficient by up to 0.5 (2x). This provides strong utility for broad use cases. For example, in most experiments, we find SFT training on unique examples for a one epoch underperforms training on half examples for two epochs, either after SFT or SFT-then-RL; With the same SFT budget, training only on short examples may lead to better SFT performance, though, it often leads to worse outcome after RL compared to training on examples with varying lengths. Evaluation tool will be open-sourced.
Demystifying Synthetic Data in LLM Pre-training: A Systematic Study of Scaling Laws, Benefits, and Pitfalls
Oct 02, 2025Training data plays a crucial role in Large Language Models (LLM) scaling, yet high quality data is of limited supply. Synthetic data techniques offer a potential path toward sidestepping these limitations. We conduct a large-scale empirical investigation (>1000 LLMs with >100k GPU hours) using a unified protocol and scaling laws, comparing natural web data, diverse synthetic types (rephrased text, generated textbooks), and mixtures of natural and synthetic data. Specifically, we found pre-training on rephrased synthetic data \textit{alone} is not faster than pre-training on natural web texts; while pre-training on 1/3 rephrased synthetic data mixed with 2/3 natural web texts can speed up 5-10x (to reach the same validation loss) at larger data budgets. Pre-training on textbook-style synthetic data \textit{alone} results in notably higher loss on many downstream domains especially at small data budgets. "Good" ratios of synthetic data in training data mixtures depend on the model size and data budget, empirically converging to ~30% for rephrased synthetic data. Larger generator models do not necessarily yield better pre-training data than ~8B-param models. These results contribute mixed evidence on "model collapse" during large-scale single-round (n=1) model training on synthetic data--training on rephrased synthetic data shows no degradation in performance in foreseeable scales whereas training on mixtures of textbook-style pure-generated synthetic data shows patterns predicted by "model collapse". Our work demystifies synthetic data in pre-training, validates its conditional benefits, and offers practical guidance.
AutoScale: Automatic Prediction of Compute-optimal Data Composition for Training LLMs
Jul 29, 2024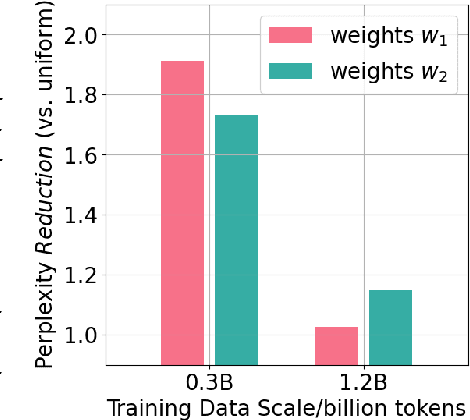
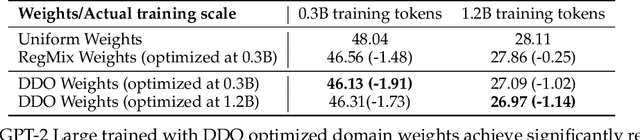
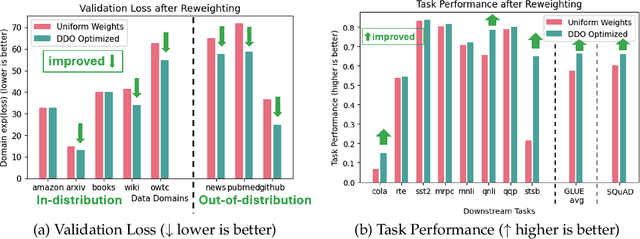
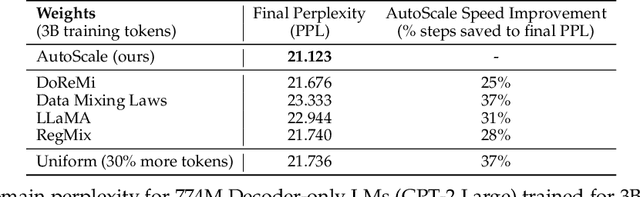
To ensure performance on a diverse set of downstream tasks, LLMs are pretrained via data mixtures over different domains. In this work, we demonstrate that the optimal data composition for a fixed compute budget varies depending on the scale of the training data, suggesting that the common practice of empirically determining an optimal composition using small-scale experiments will not yield the optimal data mixtures when scaling up to the final model. To address this challenge, we propose *AutoScale*, an automated tool that finds a compute-optimal data composition for training at any desired target scale. AutoScale first determines the optimal composition at a small scale using a novel bilevel optimization framework, Direct Data Optimization (*DDO*), and then fits a predictor to estimate the optimal composition at larger scales. The predictor's design is inspired by our theoretical analysis of scaling laws related to data composition, which could be of independent interest. In empirical studies with pre-training 774M Decoder-only LMs (GPT-2 Large) on RedPajama dataset, AutoScale decreases validation perplexity at least 25% faster than any baseline with up to 38% speed up compared to without reweighting, achieving the best overall performance across downstream tasks. On pre-training Encoder-only LMs (BERT) with masked language modeling, DDO is shown to decrease loss on all domains while visibly improving average task performance on GLUE benchmark by 8.7% and on large-scale QA dataset (SQuAD) by 5.9% compared with without reweighting. AutoScale speeds up training by up to 28%. Our codes are open-sourced.
Get more for less: Principled Data Selection for Warming Up Fine-Tuning in LLMs
May 05, 2024



This work focuses on leveraging and selecting from vast, unlabeled, open data to pre-fine-tune a pre-trained language model. The goal is to minimize the need for costly domain-specific data for subsequent fine-tuning while achieving desired performance levels. While many data selection algorithms have been designed for small-scale applications, rendering them unsuitable for our context, some emerging methods do cater to language data scales. However, they often prioritize data that aligns with the target distribution. While this strategy may be effective when training a model from scratch, it can yield limited results when the model has already been pre-trained on a different distribution. Differing from prior work, our key idea is to select data that nudges the pre-training distribution closer to the target distribution. We show the optimality of this approach for fine-tuning tasks under certain conditions. We demonstrate the efficacy of our methodology across a diverse array of tasks (NLU, NLG, zero-shot) with models up to 2.7B, showing that it consistently surpasses other selection methods. Moreover, our proposed method is significantly faster than existing techniques, scaling to millions of samples within a single GPU hour. Our code is open-sourced (Code repository: https://anonymous.4open.science/r/DV4LLM-D761/ ). While fine-tuning offers significant potential for enhancing performance across diverse tasks, its associated costs often limit its widespread adoption; with this work, we hope to lay the groundwork for cost-effective fine-tuning, making its benefits more accessible.
FASTTRACK: Fast and Accurate Fact Tracing for LLMs
Apr 22, 2024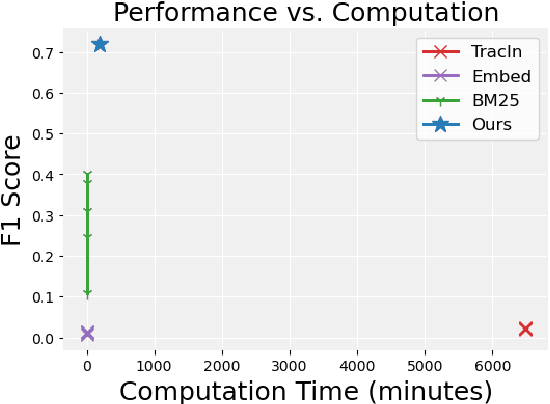



Fact tracing seeks to identify specific training examples that serve as the knowledge source for a given query. Existing approaches to fact tracing rely on assessing the similarity between each training sample and the query along a certain dimension, such as lexical similarity, gradient, or embedding space. However, these methods fall short of effectively distinguishing between samples that are merely relevant and those that actually provide supportive evidence for the information sought by the query. This limitation often results in suboptimal effectiveness. Moreover, these approaches necessitate the examination of the similarity of individual training points for each query, imposing significant computational demands and creating a substantial barrier for practical applications. This paper introduces FASTTRACK, a novel approach that harnesses the capabilities of Large Language Models (LLMs) to validate supportive evidence for queries and at the same time clusters the training database towards a reduced extent for LLMs to trace facts. Our experiments show that FASTTRACK substantially outperforms existing methods in both accuracy and efficiency, achieving more than 100\% improvement in F1 score over the state-of-the-art methods while being X33 faster than \texttt{TracIn}.
The Mirrored Influence Hypothesis: Efficient Data Influence Estimation by Harnessing Forward Passes
Feb 14, 2024

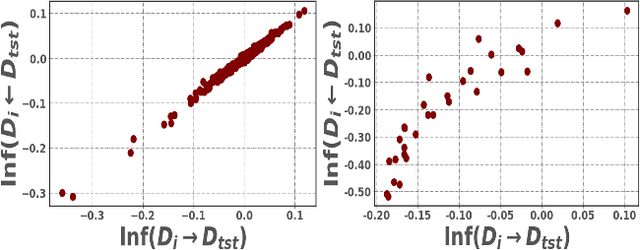

Large-scale black-box models have become ubiquitous across numerous applications. Understanding the influence of individual training data sources on predictions made by these models is crucial for improving their trustworthiness. Current influence estimation techniques involve computing gradients for every training point or repeated training on different subsets. These approaches face obvious computational challenges when scaled up to large datasets and models. In this paper, we introduce and explore the Mirrored Influence Hypothesis, highlighting a reciprocal nature of influence between training and test data. Specifically, it suggests that evaluating the influence of training data on test predictions can be reformulated as an equivalent, yet inverse problem: assessing how the predictions for training samples would be altered if the model were trained on specific test samples. Through both empirical and theoretical validations, we demonstrate the wide applicability of our hypothesis. Inspired by this, we introduce a new method for estimating the influence of training data, which requires calculating gradients for specific test samples, paired with a forward pass for each training point. This approach can capitalize on the common asymmetry in scenarios where the number of test samples under concurrent examination is much smaller than the scale of the training dataset, thus gaining a significant improvement in efficiency compared to existing approaches. We demonstrate the applicability of our method across a range of scenarios, including data attribution in diffusion models, data leakage detection, analysis of memorization, mislabeled data detection, and tracing behavior in language models. Our code will be made available at https://github.com/ruoxi-jia-group/Forward-INF.
Data Acquisition: A New Frontier in Data-centric AI
Nov 22, 2023



As Machine Learning (ML) systems continue to grow, the demand for relevant and comprehensive datasets becomes imperative. There is limited study on the challenges of data acquisition due to ad-hoc processes and lack of consistent methodologies. We first present an investigation of current data marketplaces, revealing lack of platforms offering detailed information about datasets, transparent pricing, standardized data formats. With the objective of inciting participation from the data-centric AI community, we then introduce the DAM challenge, a benchmark to model the interaction between the data providers and acquirers. The benchmark was released as a part of DataPerf. Our evaluation of the submitted strategies underlines the need for effective data acquisition strategies in ML.