 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGet more for less: Principled Data Selection for Warming Up Fine-Tuning in LLMs
May 05, 2024



This work focuses on leveraging and selecting from vast, unlabeled, open data to pre-fine-tune a pre-trained language model. The goal is to minimize the need for costly domain-specific data for subsequent fine-tuning while achieving desired performance levels. While many data selection algorithms have been designed for small-scale applications, rendering them unsuitable for our context, some emerging methods do cater to language data scales. However, they often prioritize data that aligns with the target distribution. While this strategy may be effective when training a model from scratch, it can yield limited results when the model has already been pre-trained on a different distribution. Differing from prior work, our key idea is to select data that nudges the pre-training distribution closer to the target distribution. We show the optimality of this approach for fine-tuning tasks under certain conditions. We demonstrate the efficacy of our methodology across a diverse array of tasks (NLU, NLG, zero-shot) with models up to 2.7B, showing that it consistently surpasses other selection methods. Moreover, our proposed method is significantly faster than existing techniques, scaling to millions of samples within a single GPU hour. Our code is open-sourced (Code repository: https://anonymous.4open.science/r/DV4LLM-D761/ ). While fine-tuning offers significant potential for enhancing performance across diverse tasks, its associated costs often limit its widespread adoption; with this work, we hope to lay the groundwork for cost-effective fine-tuning, making its benefits more accessible.
How to Sift Out a Clean Data Subset in the Presence of Data Poisoning?
Oct 12, 2022


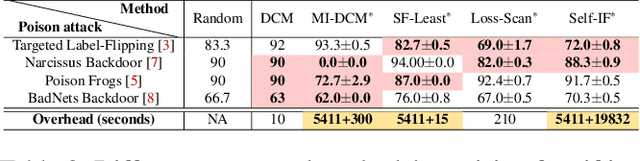
Given the volume of data needed to train modern machine learning models, external suppliers are increasingly used. However, incorporating external data poses data poisoning risks, wherein attackers manipulate their data to degrade model utility or integrity. Most poisoning defenses presume access to a set of clean data (or base set). While this assumption has been taken for granted, given the fast-growing research on stealthy poisoning attacks, a question arises: can defenders really identify a clean subset within a contaminated dataset to support defenses? This paper starts by examining the impact of poisoned samples on defenses when they are mistakenly mixed into the base set. We analyze five defenses and find that their performance deteriorates dramatically with less than 1% poisoned points in the base set. These findings suggest that sifting out a base set with high precision is key to these defenses' performance. Motivated by these observations, we study how precise existing automated tools and human inspection are at identifying clean data in the presence of data poisoning. Unfortunately, neither effort achieves the precision needed. Worse yet, many of the outcomes are worse than random selection. In addition to uncovering the challenge, we propose a practical countermeasure, Meta-Sift. Our method is based on the insight that existing attacks' poisoned samples shifts from clean data distributions. Hence, training on the clean portion of a dataset and testing on the corrupted portion will result in high prediction loss. Leveraging the insight, we formulate a bilevel optimization to identify clean data and further introduce a suite of techniques to improve efficiency and precision. Our evaluation shows that Meta-Sift can sift a clean base set with 100% precision under a wide range of poisoning attacks. The selected base set is large enough to give rise to successful defenses.