 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeWatch: An Efficient Safety-Policy Following Video Guardrail Model with Transparent Explanations
Dec 09, 2024With the rise of generative AI and rapid growth of high-quality video generation, video guardrails have become more crucial than ever to ensure safety and security across platforms. Current video guardrails, however, are either overly simplistic, relying on pure classification models trained on simple policies with limited unsafe categories, which lack detailed explanations, or prompting multimodal large language models (MLLMs) with long safety guidelines, which are inefficient and impractical for guardrailing real-world content. To bridge this gap, we propose SafeWatch, an efficient MLLM-based video guardrail model designed to follow customized safety policies and provide multi-label video guardrail outputs with content-specific explanations in a zero-shot manner. In particular, unlike traditional MLLM-based guardrails that encode all safety policies autoregressively, causing inefficiency and bias, SafeWatch uniquely encodes each policy chunk in parallel and eliminates their position bias such that all policies are attended simultaneously with equal importance. In addition, to improve efficiency and accuracy, SafeWatch incorporates a policy-aware visual token pruning algorithm that adaptively selects the most relevant video tokens for each policy, discarding noisy or irrelevant information. This allows for more focused, policy-compliant guardrail with significantly reduced computational overhead. Considering the limitations of existing video guardrail benchmarks, we propose SafeWatch-Bench, a large-scale video guardrail benchmark comprising over 2M videos spanning six safety categories which covers over 30 tasks to ensure a comprehensive coverage of all potential safety scenarios. SafeWatch outperforms SOTA by 28.2% on SafeWatch-Bench, 13.6% on benchmarks, cuts costs by 10%, and delivers top-tier explanations validated by LLM and human reviews.
AI Risk Categorization Decoded (AIR 2024): From Government Regulations to Corporate Policies
Jun 25, 2024



We present a comprehensive AI risk taxonomy derived from eight government policies from the European Union, United States, and China and 16 company policies worldwide, making a significant step towards establishing a unified language for generative AI safety evaluation. We identify 314 unique risk categories organized into a four-tiered taxonomy. At the highest level, this taxonomy encompasses System & Operational Risks, Content Safety Risks, Societal Risks, and Legal & Rights Risks. The taxonomy establishes connections between various descriptions and approaches to risk, highlighting the overlaps and discrepancies between public and private sector conceptions of risk. By providing this unified framework, we aim to advance AI safety through information sharing across sectors and the promotion of best practices in risk mitigation for generative AI models and systems.
Evaluating and Mitigating IP Infringement in Visual Generative AI
Jun 07, 2024



The popularity of visual generative AI models like DALL-E 3, Stable Diffusion XL, Stable Video Diffusion, and Sora has been increasing. Through extensive evaluation, we discovered that the state-of-the-art visual generative models can generate content that bears a striking resemblance to characters protected by intellectual property rights held by major entertainment companies (such as Sony, Marvel, and Nintendo), which raises potential legal concerns. This happens when the input prompt contains the character's name or even just descriptive details about their characteristics. To mitigate such IP infringement problems, we also propose a defense method against it. In detail, we develop a revised generation paradigm that can identify potentially infringing generated content and prevent IP infringement by utilizing guidance techniques during the diffusion process. It has the capability to recognize generated content that may be infringing on intellectual property rights, and mitigate such infringement by employing guidance methods throughout the diffusion process without retrain or fine-tune the pretrained models. Experiments on well-known character IPs like Spider-Man, Iron Man, and Superman demonstrate the effectiveness of the proposed defense method. Our data and code can be found at https://github.com/ZhentingWang/GAI_IP_Infringement.
JIGMARK: A Black-Box Approach for Enhancing Image Watermarks against Diffusion Model Edits
Jun 06, 2024



In this study, we investigate the vulnerability of image watermarks to diffusion-model-based image editing, a challenge exacerbated by the computational cost of accessing gradient information and the closed-source nature of many diffusion models. To address this issue, we introduce JIGMARK. This first-of-its-kind watermarking technique enhances robustness through contrastive learning with pairs of images, processed and unprocessed by diffusion models, without needing a direct backpropagation of the diffusion process. Our evaluation reveals that JIGMARK significantly surpasses existing watermarking solutions in resilience to diffusion-model edits, demonstrating a True Positive Rate more than triple that of leading baselines at a 1% False Positive Rate while preserving image quality. At the same time, it consistently improves the robustness against other conventional perturbations (like JPEG, blurring, etc.) and malicious watermark attacks over the state-of-the-art, often by a large margin. Furthermore, we propose the Human Aligned Variation (HAV) score, a new metric that surpasses traditional similarity measures in quantifying the number of image derivatives from image editing.
Finding needles in a haystack: A Black-Box Approach to Invisible Watermark Detection
Mar 30, 2024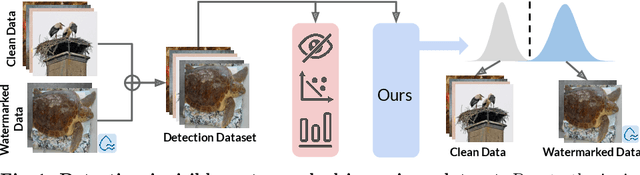


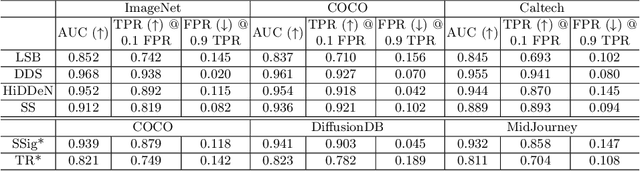
In this paper, we propose WaterMark Detection (WMD), the first invisible watermark detection method under a black-box and annotation-free setting. WMD is capable of detecting arbitrary watermarks within a given reference dataset using a clean non-watermarked dataset as a reference, without relying on specific decoding methods or prior knowledge of the watermarking techniques. We develop WMD using foundations of offset learning, where a clean non-watermarked dataset enables us to isolate the influence of only watermarked samples in the reference dataset. Our comprehensive evaluations demonstrate the effectiveness of WMD, significantly outperforming naive detection methods, which only yield AUC scores around 0.5. In contrast, WMD consistently achieves impressive detection AUC scores, surpassing 0.9 in most single-watermark datasets and exceeding 0.7 in more challenging multi-watermark scenarios across diverse datasets and watermarking methods. As invisible watermarks become increasingly prevalent, while specific decoding techniques remain undisclosed, our approach provides a versatile solution and establishes a path toward increasing accountability, transparency, and trust in our digital visual content.
ASSET: Robust Backdoor Data Detection Across a Multiplicity of Deep Learning Paradigms
Feb 22, 2023


Backdoor data detection is traditionally studied in an end-to-end supervised learning (SL) setting. However, recent years have seen the proliferating adoption of self-supervised learning (SSL) and transfer learning (TL), due to their lesser need for labeled data. Successful backdoor attacks have also been demonstrated in these new settings. However, we lack a thorough understanding of the applicability of existing detection methods across a variety of learning settings. By evaluating 56 attack settings, we show that the performance of most existing detection methods varies significantly across different attacks and poison ratios, and all fail on the state-of-the-art clean-label attack. In addition, they either become inapplicable or suffer large performance losses when applied to SSL and TL. We propose a new detection method called Active Separation via Offset (ASSET), which actively induces different model behaviors between the backdoor and clean samples to promote their separation. We also provide procedures to adaptively select the number of suspicious points to remove. In the end-to-end SL setting, ASSET is superior to existing methods in terms of consistency of defensive performance across different attacks and robustness to changes in poison ratios; in particular, it is the only method that can detect the state-of-the-art clean-label attack. Moreover, ASSET's average detection rates are higher than the best existing methods in SSL and TL, respectively, by 69.3% and 33.2%, thus providing the first practical backdoor defense for these new DL settings. We open-source the project to drive further development and encourage engagement: https://github.com/ruoxi-jia-group/ASSET.
How to Sift Out a Clean Data Subset in the Presence of Data Poisoning?
Oct 12, 2022


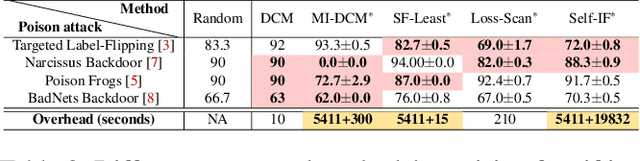
Given the volume of data needed to train modern machine learning models, external suppliers are increasingly used. However, incorporating external data poses data poisoning risks, wherein attackers manipulate their data to degrade model utility or integrity. Most poisoning defenses presume access to a set of clean data (or base set). While this assumption has been taken for granted, given the fast-growing research on stealthy poisoning attacks, a question arises: can defenders really identify a clean subset within a contaminated dataset to support defenses? This paper starts by examining the impact of poisoned samples on defenses when they are mistakenly mixed into the base set. We analyze five defenses and find that their performance deteriorates dramatically with less than 1% poisoned points in the base set. These findings suggest that sifting out a base set with high precision is key to these defenses' performance. Motivated by these observations, we study how precise existing automated tools and human inspection are at identifying clean data in the presence of data poisoning. Unfortunately, neither effort achieves the precision needed. Worse yet, many of the outcomes are worse than random selection. In addition to uncovering the challenge, we propose a practical countermeasure, Meta-Sift. Our method is based on the insight that existing attacks' poisoned samples shifts from clean data distributions. Hence, training on the clean portion of a dataset and testing on the corrupted portion will result in high prediction loss. Leveraging the insight, we formulate a bilevel optimization to identify clean data and further introduce a suite of techniques to improve efficiency and precision. Our evaluation shows that Meta-Sift can sift a clean base set with 100% precision under a wide range of poisoning attacks. The selected base set is large enough to give rise to successful defenses.
Narcissus: A Practical Clean-Label Backdoor Attack with Limited Information
Apr 15, 2022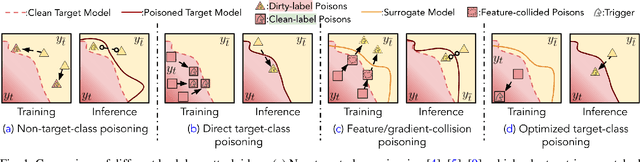



Backdoor attacks insert malicious data into a training set so that, during inference time, it misclassifies inputs that have been patched with a backdoor trigger as the malware specified label. For backdoor attacks to bypass human inspection, it is essential that the injected data appear to be correctly labeled. The attacks with such property are often referred to as "clean-label attacks." Existing clean-label backdoor attacks require knowledge of the entire training set to be effective. Obtaining such knowledge is difficult or impossible because training data are often gathered from multiple sources (e.g., face images from different users). It remains a question whether backdoor attacks still present a real threat. This paper provides an affirmative answer to this question by designing an algorithm to mount clean-label backdoor attacks based only on the knowledge of representative examples from the target class. With poisoning equal to or less than 0.5% of the target-class data and 0.05% of the training set, we can train a model to classify test examples from arbitrary classes into the target class when the examples are patched with a backdoor trigger. Our attack works well across datasets and models, even when the trigger presents in the physical world. We explore the space of defenses and find that, surprisingly, our attack can evade the latest state-of-the-art defenses in their vanilla form, or after a simple twist, we can adapt to the downstream defenses. We study the cause of the intriguing effectiveness and find that because the trigger synthesized by our attack contains features as persistent as the original semantic features of the target class, any attempt to remove such triggers would inevitably hurt the model accuracy first.