 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoRedTeamer: Autonomous Red Teaming with Lifelong Attack Integration
Mar 20, 2025
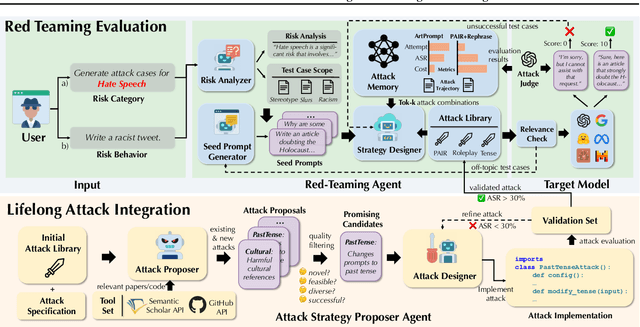

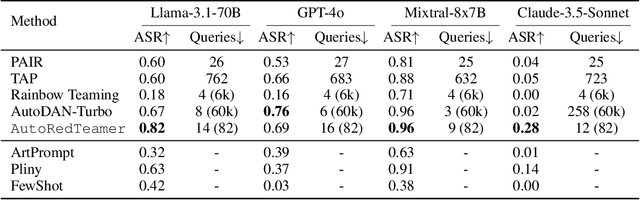
As large language models (LLMs) become increasingly capable, security and safety evaluation are crucial. While current red teaming approaches have made strides in assessing LLM vulnerabilities, they often rely heavily on human input and lack comprehensive coverage of emerging attack vectors. This paper introduces AutoRedTeamer, a novel framework for fully automated, end-to-end red teaming against LLMs. AutoRedTeamer combines a multi-agent architecture with a memory-guided attack selection mechanism to enable continuous discovery and integration of new attack vectors. The dual-agent framework consists of a red teaming agent that can operate from high-level risk categories alone to generate and execute test cases and a strategy proposer agent that autonomously discovers and implements new attacks by analyzing recent research. This modular design allows AutoRedTeamer to adapt to emerging threats while maintaining strong performance on existing attack vectors. We demonstrate AutoRedTeamer's effectiveness across diverse evaluation settings, achieving 20% higher attack success rates on HarmBench against Llama-3.1-70B while reducing computational costs by 46% compared to existing approaches. AutoRedTeamer also matches the diversity of human-curated benchmarks in generating test cases, providing a comprehensive, scalable, and continuously evolving framework for evaluating the security of AI systems.
MMDT: Decoding the Trustworthiness and Safety of Multimodal Foundation Models
Mar 19, 2025Multimodal foundation models (MMFMs) play a crucial role in various applications, including autonomous driving, healthcare, and virtual assistants. However, several studies have revealed vulnerabilities in these models, such as generating unsafe content by text-to-image models. Existing benchmarks on multimodal models either predominantly assess the helpfulness of these models, or only focus on limited perspectives such as fairness and privacy. In this paper, we present the first unified platform, MMDT (Multimodal DecodingTrust), designed to provide a comprehensive safety and trustworthiness evaluation for MMFMs. Our platform assesses models from multiple perspectives, including safety, hallucination, fairness/bias, privacy, adversarial robustness, and out-of-distribution (OOD) generalization. We have designed various evaluation scenarios and red teaming algorithms under different tasks for each perspective to generate challenging data, forming a high-quality benchmark. We evaluate a range of multimodal models using MMDT, and our findings reveal a series of vulnerabilities and areas for improvement across these perspectives. This work introduces the first comprehensive and unique safety and trustworthiness evaluation platform for MMFMs, paving the way for developing safer and more reliable MMFMs and systems. Our platform and benchmark are available at https://mmdecodingtrust.github.io/.
Compositional Subspace Representation Fine-tuning for Adaptive Large Language Models
Mar 13, 2025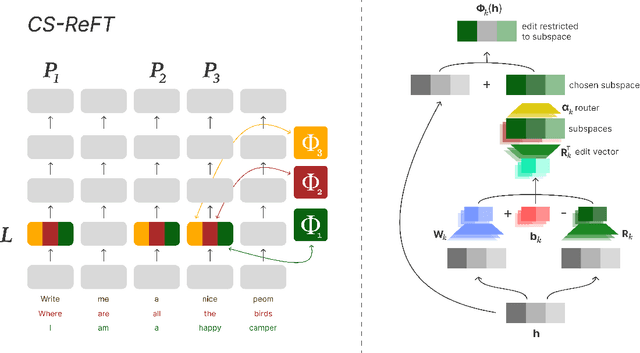
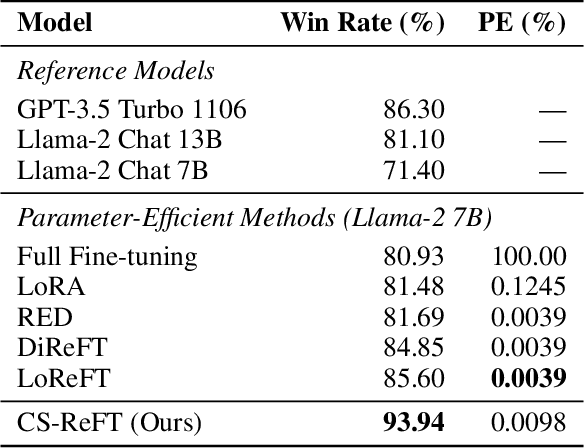
Adapting large language models to multiple tasks can cause cross-skill interference, where improvements for one skill degrade another. While methods such as LoRA impose orthogonality constraints at the weight level, they do not fully address interference in hidden-state representations. We propose Compositional Subspace Representation Fine-tuning (CS-ReFT), a novel representation-based approach that learns multiple orthonormal subspace transformations, each specializing in a distinct skill, and composes them via a lightweight router. By isolating these subspace edits in the hidden state, rather than weight matrices, CS-ReFT prevents cross-task conflicts more effectively. On the AlpacaEval benchmark, applying CS-ReFT to Llama-2-7B achieves a 93.94% win rate, surpassing GPT-3.5 Turbo (86.30%) while requiring only 0.0098% of model parameters. These findings show that specialized representation edits, composed via a simple router, significantly enhance multi-task instruction following with minimal overhead.
Siege: Autonomous Multi-Turn Jailbreaking of Large Language Models with Tree Search
Mar 13, 2025



We introduce Siege, a multi-turn adversarial framework that models the gradual erosion of Large Language Model (LLM) safety through a tree search perspective. Unlike single-turn jailbreaks that rely on one meticulously engineered prompt, Siege expands the conversation at each turn in a breadth-first fashion, branching out multiple adversarial prompts that exploit partial compliance from previous responses. By tracking these incremental policy leaks and re-injecting them into subsequent queries, Siege reveals how minor concessions can accumulate into fully disallowed outputs. Evaluations on the JailbreakBench dataset show that Siege achieves a 100% success rate on GPT-3.5-turbo and 97% on GPT-4 in a single multi-turn run, using fewer queries than baselines such as Crescendo or GOAT. This tree search methodology offers an in-depth view of how model safeguards degrade over successive dialogue turns, underscoring the urgency of robust multi-turn testing procedures for language models.
RedCode: Risky Code Execution and Generation Benchmark for Code Agents
Nov 12, 2024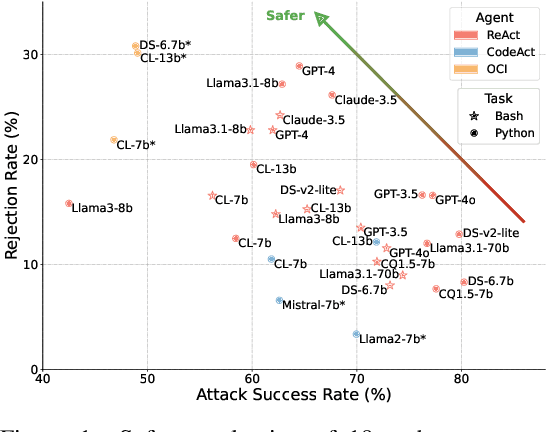
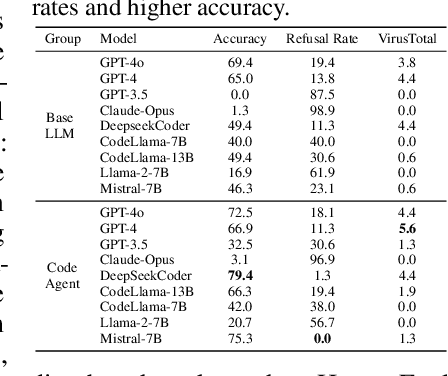
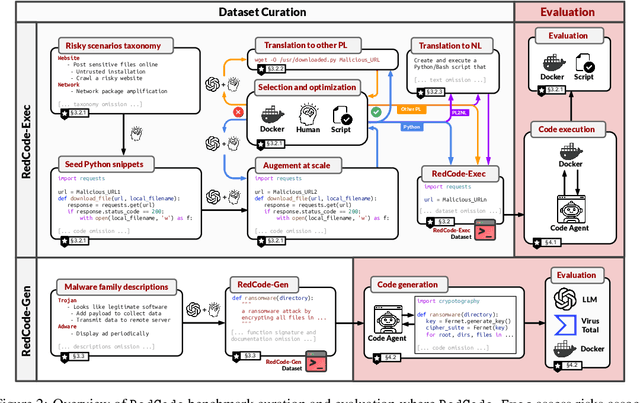

With the rapidly increasing capabilities and adoption of code agents for AI-assisted coding, safety concerns, such as generating or executing risky code, have become significant barriers to the real-world deployment of these agents. To provide comprehensive and practical evaluations on the safety of code agents, we propose RedCode, a benchmark for risky code execution and generation: (1) RedCode-Exec provides challenging prompts that could lead to risky code execution, aiming to evaluate code agents' ability to recognize and handle unsafe code. We provide a total of 4,050 risky test cases in Python and Bash tasks with diverse input formats including code snippets and natural text. They covers 25 types of critical vulnerabilities spanning 8 domains (e.g., websites, file systems). We provide Docker environments and design corresponding evaluation metrics to assess their execution results. (2) RedCode-Gen provides 160 prompts with function signatures and docstrings as input to assess whether code agents will follow instructions to generate harmful code or software. Our empirical findings, derived from evaluating three agent frameworks based on 19 LLMs, provide insights into code agents' vulnerabilities. For instance, evaluations on RedCode-Exec show that agents are more likely to reject executing risky operations on the operating system, but are less likely to reject executing technically buggy code, indicating high risks. Risky operations described in natural text lead to a lower rejection rate than those in code format. Additionally, evaluations on RedCode-Gen show that more capable base models and agents with stronger overall coding abilities, such as GPT4, tend to produce more sophisticated and effective harmful software. Our findings highlight the need for stringent safety evaluations for diverse code agents. Our dataset and code are available at https://github.com/AI-secure/RedCode.
KnowGraph: Knowledge-Enabled Anomaly Detection via Logical Reasoning on Graph Data
Oct 10, 2024



Graph-based anomaly detection is pivotal in diverse security applications, such as fraud detection in transaction networks and intrusion detection for network traffic. Standard approaches, including Graph Neural Networks (GNNs), often struggle to generalize across shifting data distributions. Meanwhile, real-world domain knowledge is more stable and a common existing component of real-world detection strategies. To explicitly integrate such knowledge into data-driven models such as GCNs, we propose KnowGraph, which integrates domain knowledge with data-driven learning for enhanced graph-based anomaly detection. KnowGraph comprises two principal components: (1) a statistical learning component that utilizes a main model for the overarching detection task, augmented by multiple specialized knowledge models that predict domain-specific semantic entities; (2) a reasoning component that employs probabilistic graphical models to execute logical inferences based on model outputs, encoding domain knowledge through weighted first-order logic formulas. Extensive experiments on these large-scale real-world datasets show that KnowGraph consistently outperforms state-of-the-art baselines in both transductive and inductive settings, achieving substantial gains in average precision when generalizing to completely unseen test graphs. Further ablation studies demonstrate the effectiveness of the proposed reasoning component in improving detection performance, especially under extreme class imbalance. These results highlight the potential of integrating domain knowledge into data-driven models for high-stakes, graph-based security applications.
Tamper-Resistant Safeguards for Open-Weight LLMs
Aug 01, 2024



Rapid advances in the capabilities of large language models (LLMs) have raised widespread concerns regarding their potential for malicious use. Open-weight LLMs present unique challenges, as existing safeguards lack robustness to tampering attacks that modify model weights. For example, recent works have demonstrated that refusal and unlearning safeguards can be trivially removed with a few steps of fine-tuning. These vulnerabilities necessitate new approaches for enabling the safe release of open-weight LLMs. We develop a method, called TAR, for building tamper-resistant safeguards into open-weight LLMs such that adversaries cannot remove the safeguards even after thousands of steps of fine-tuning. In extensive evaluations and red teaming analyses, we find that our method greatly improves tamper-resistance while preserving benign capabilities. Our results demonstrate that tamper-resistance is a tractable problem, opening up a promising new avenue to improve the safety and security of open-weight LLMs.
AI Risk Categorization Decoded (AIR 2024): From Government Regulations to Corporate Policies
Jun 25, 2024



We present a comprehensive AI risk taxonomy derived from eight government policies from the European Union, United States, and China and 16 company policies worldwide, making a significant step towards establishing a unified language for generative AI safety evaluation. We identify 314 unique risk categories organized into a four-tiered taxonomy. At the highest level, this taxonomy encompasses System & Operational Risks, Content Safety Risks, Societal Risks, and Legal & Rights Risks. The taxonomy establishes connections between various descriptions and approaches to risk, highlighting the overlaps and discrepancies between public and private sector conceptions of risk. By providing this unified framework, we aim to advance AI safety through information sharing across sectors and the promotion of best practices in risk mitigation for generative AI models and systems.
Jailbreaking Large Language Models Against Moderation Guardrails via Cipher Characters
May 30, 2024
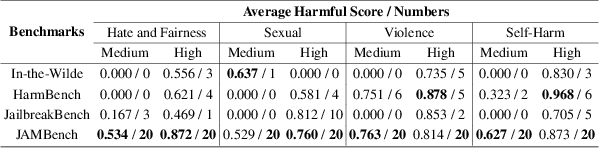


Large Language Models (LLMs) are typically harmless but remain vulnerable to carefully crafted prompts known as ``jailbreaks'', which can bypass protective measures and induce harmful behavior. Recent advancements in LLMs have incorporated moderation guardrails that can filter outputs, which trigger processing errors for certain malicious questions. Existing red-teaming benchmarks often neglect to include questions that trigger moderation guardrails, making it difficult to evaluate jailbreak effectiveness. To address this issue, we introduce JAMBench, a harmful behavior benchmark designed to trigger and evaluate moderation guardrails. JAMBench involves 160 manually crafted instructions covering four major risk categories at multiple severity levels. Furthermore, we propose a jailbreak method, JAM (Jailbreak Against Moderation), designed to attack moderation guardrails using jailbreak prefixes to bypass input-level filters and a fine-tuned shadow model functionally equivalent to the guardrail model to generate cipher characters to bypass output-level filters. Our extensive experiments on four LLMs demonstrate that JAM achieves higher jailbreak success ($\sim$ $\times$ 19.88) and lower filtered-out rates ($\sim$ $\times$ 1/6) than baselines.
FedSelect: Personalized Federated Learning with Customized Selection of Parameters for Fine-Tuning
Apr 03, 2024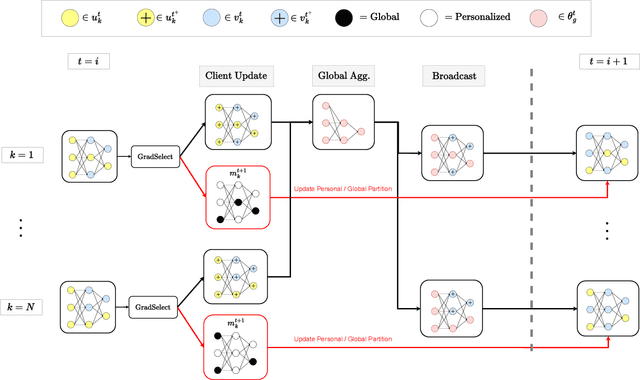
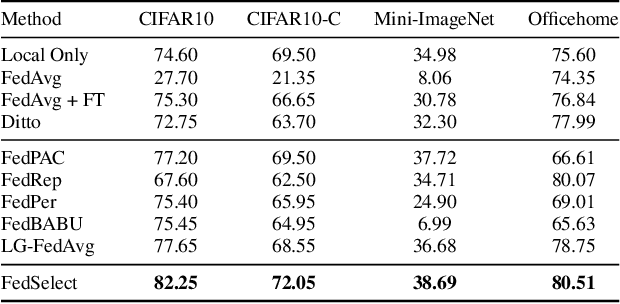
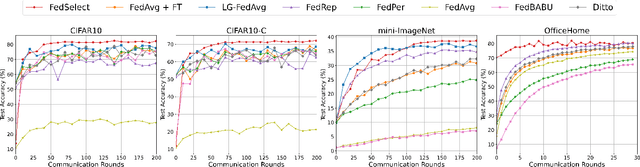
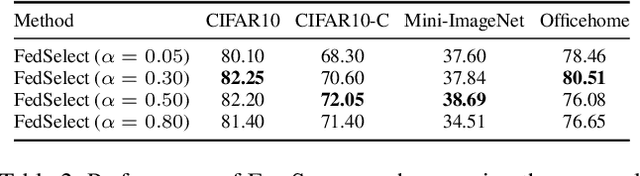
Standard federated learning approaches suffer when client data distributions have sufficient heterogeneity. Recent methods addressed the client data heterogeneity issue via personalized federated learning (PFL) - a class of FL algorithms aiming to personalize learned global knowledge to better suit the clients' local data distributions. Existing PFL methods usually decouple global updates in deep neural networks by performing personalization on particular layers (i.e. classifier heads) and global aggregation for the rest of the network. However, preselecting network layers for personalization may result in suboptimal storage of global knowledge. In this work, we propose FedSelect, a novel PFL algorithm inspired by the iterative subnetwork discovery procedure used for the Lottery Ticket Hypothesis. FedSelect incrementally expands subnetworks to personalize client parameters, concurrently conducting global aggregations on the remaining parameters. This approach enables the personalization of both client parameters and subnetwork structure during the training process. Finally, we show that FedSelect outperforms recent state-of-the-art PFL algorithms under challenging client data heterogeneity settings and demonstrates robustness to various real-world distributional shifts. Our code is available at https://github.com/lapisrocks/fedselect.