 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecodingTrust-Agent Platform (DTap): A Controllable and Interactive Red-Teaming Platform for AI Agents
May 06, 2026AI agents are increasingly deployed across diverse domains to automate complex workflows through long-horizon and high-stakes action executions. Due to their high capability and flexibility, such agents raise significant security and safety concerns. A growing number of real-world incidents have shown that adversaries can easily manipulate agents into performing harmful actions, such as leaking API keys, deleting user data, or initiating unauthorized transactions. Evaluating agent security is inherently challenging, as agents operate in dynamic, untrusted environments involving external tools, heterogeneous data sources, and frequent user interactions. However, realistic, controllable, and reproducible environments for large-scale risk assessment remain largely underexplored. To address this gap, we introduce the DecodingTrust-Agent Platform (DTap), the first controllable and interactive red-teaming platform for AI agents, spanning 14 real-world domains and over 50 simulation environments that replicate widely used systems such as Google Workspace, Paypal, and Slack. To scale the risk assessment of agents in DTap, we further propose DTap-Red, the first autonomous red-teaming agent that systematically explores diverse injection vectors (e.g., prompt, tool, skill, environment, combinations) and autonomously discovers effective attack strategies tailored to varying malicious goals. Using DTap-Red, we curate DTap-Bench, a large-scale red-teaming dataset comprising high-quality instances across domains, each paired with a verifiable judge to automatically validate attack outcomes. Through DTap, we conduct large-scale evaluations of popular AI agents built on various backbone models, spanning security policies, risk categories, and attack strategies, revealing systematic vulnerability patterns and providing valuable insights for developing secure next-generation agents.
OneRanker: Unified Generation and Ranking with One Model in Industrial Advertising Recommendation
Mar 04, 2026The end-to-end generative paradigm is revolutionizing advertising recommendation systems, driving a shift from traditional cascaded architectures towards unified modeling. However, practical deployment faces three core challenges: the misalignment between interest objectives and business value, the target-agnostic limitation of generative processes, and the disconnection between generation and ranking stages. Existing solutions often fall into a dilemma where single-stage fusion induces optimization tension, while stage decoupling causes irreversible information loss. To address this, we propose OneRanker, achieving architectural-level deep integration of generation and ranking. First, we design a value-aware multi-task decoupling architecture. By leveraging task token sequences and causal mask, we separate interest coverage and value optimization spaces within shared representations, effectively alleviating target conflicts. Second, we construct a coarse-to-fine collaborative target awareness mechanism, utilizing Fake Item Tokens for implicit awareness during generation and a ranking decoder for explicit value alignment at the candidate level. Finally, we propose input-output dual-side consistency guarantees. Through Key/Value pass-through mechanisms and Distribution Consistency (DC) Constraint Loss, we achieve end-to-end collaborative optimization between generation and ranking. The full deployment on Tencent's WeiXin channels advertising system has shown a significant improvement in key business metrics (GMV - Normal +1.34\%), providing a new paradigm with industrial feasibility for generative advertising recommendations.
HyCARD-Net: A Synergistic Hybrid Intelligence Framework for Cardiovascular Disease Diagnosis
Jan 25, 2026Cardiovascular disease (CVD) remains the foremost cause of mortality worldwide, underscoring the urgent need for intelligent and data-driven diagnostic tools. Traditional predictive models often struggle to generalize across heterogeneous datasets and complex physiological patterns. To address this, we propose a hybrid ensemble framework that integrates deep learning architectures, Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM), with classical machine learning algorithms, including K-Nearest Neighbor (KNN) and Extreme Gradient Boosting (XGB), using an ensemble voting mechanism. This approach combines the representational power of deep networks with the interpretability and efficiency of traditional models. Experiments on two publicly available Kaggle datasets demonstrate that the proposed model achieves superior performance, reaching 82.30 percent accuracy on Dataset I and 97.10 percent on Dataset II, with consistent gains in precision, recall, and F1-score. These findings underscore the robustness and clinical potential of hybrid AI frameworks for predicting cardiovascular disease and facilitating early intervention. Furthermore, this study directly supports the United Nations Sustainable Development Goal 3 (Good Health and Well-being) by promoting early diagnosis, prevention, and management of non-communicable diseases through innovative, data-driven healthcare solutions.
GPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising Recommendation
Nov 13, 2025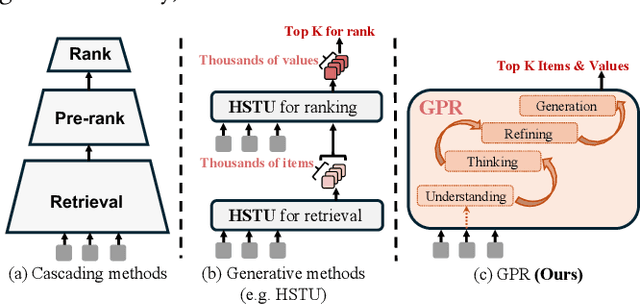
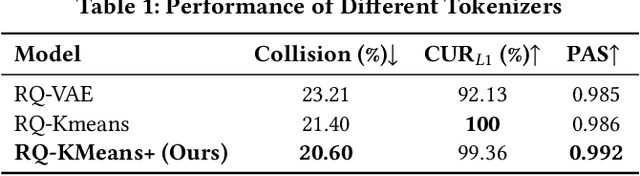
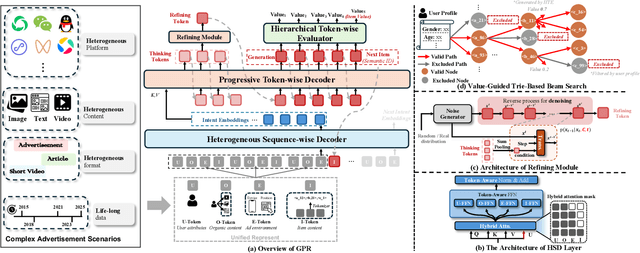
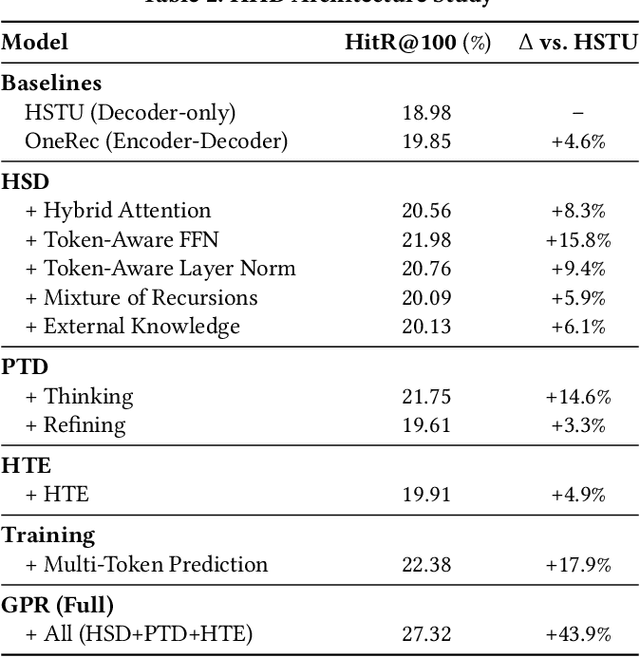
As an intelligent infrastructure connecting users with commercial content, advertising recommendation systems play a central role in information flow and value creation within the digital economy. However, existing multi-stage advertising recommendation systems suffer from objective misalignment and error propagation, making it difficult to achieve global optimality, while unified generative recommendation models still struggle to meet the demands of practical industrial applications. To address these issues, we propose GPR (Generative Pre-trained Recommender), the first one-model framework that redefines advertising recommendation as an end-to-end generative task, replacing the traditional cascading paradigm with a unified generative approach. To realize GPR, we introduce three key innovations spanning unified representation, network architecture, and training strategy. First, we design a unified input schema and tokenization method tailored to advertising scenarios, mapping both ads and organic content into a shared multi-level semantic ID space, thereby enhancing semantic alignment and modeling consistency across heterogeneous data. Second, we develop the Heterogeneous Hierarchical Decoder (HHD), a dual-decoder architecture that decouples user intent modeling from ad generation, achieving a balance between training efficiency and inference flexibility while maintaining strong modeling capacity. Finally, we propose a multi-stage joint training strategy that integrates Multi-Token Prediction (MTP), Value-Aware Fine-Tuning and the Hierarchy Enhanced Policy Optimization (HEPO) algorithm, forming a complete generative recommendation pipeline that unifies interest modeling, value alignment, and policy optimization. GPR has been fully deployed in the Tencent Weixin Channels advertising system, delivering significant improvements in key business metrics including GMV and CTCVR.
The Estimation of Continual Causal Effect for Dataset Shifting Streams
Apr 29, 2025Causal effect estimation has been widely used in marketing optimization. The framework of an uplift model followed by a constrained optimization algorithm is popular in practice. To enhance performance in the online environment, the framework needs to be improved to address the complexities caused by temporal dataset shift. This paper focuses on capturing the dataset shift from user behavior and domain distribution changing over time. We propose an Incremental Causal Effect with Proxy Knowledge Distillation (ICE-PKD) framework to tackle this challenge. The ICE-PKD framework includes two components: (i) a multi-treatment uplift network that eliminates confounding bias using counterfactual regression; (ii) an incremental training strategy that adapts to the temporal dataset shift by updating with the latest data and protects generalization via replay-based knowledge distillation. We also revisit the uplift modeling metrics and introduce a novel metric for more precise online evaluation in multiple treatment scenarios. Extensive experiments on both simulated and online datasets show that the proposed framework achieves better performance. The ICE-PKD framework has been deployed in the marketing system of Huaxiaozhu, a ride-hailing platform in China.
Ultra-Low Complexity On-Orbit Compression for Remote Sensing Imagery via Block Modulated Imaging
Dec 24, 2024The growing field of remote sensing faces a challenge: the ever-increasing size and volume of imagery data are exceeding the storage and transmission capabilities of satellite platforms. Efficient compression of remote sensing imagery is a critical solution to alleviate these burdens on satellites. However, existing compression methods are often too computationally expensive for satellites. With the continued advancement of compressed sensing theory, single-pixel imaging emerges as a powerful tool that brings new possibilities for on-orbit image compression. However, it still suffers from prolonged imaging times and the inability to perform high-resolution imaging, hindering its practical application. This paper advances the study of compressed sensing in remote sensing image compression, proposing Block Modulated Imaging (BMI). By requiring only a single exposure, BMI significantly enhances imaging acquisition speeds. Additionally, BMI obviates the need for digital micromirror devices and surpasses limitations in image resolution. Furthermore, we propose a novel decoding network specifically designed to reconstruct images compressed under the BMI framework. Leveraging the gated 3D convolutions and promoting efficient information flow across stages through a Two-Way Cross-Attention module, our decoding network exhibits demonstrably superior reconstruction performance. Extensive experiments conducted on multiple renowned remote sensing datasets unequivocally demonstrate the efficacy of our proposed method. To further validate its practical applicability, we developed and tested a prototype of the BMI-based camera, which has shown promising potential for on-orbit image compression. The code is available at https://github.com/Johnathan218/BMNet.
RedCode: Risky Code Execution and Generation Benchmark for Code Agents
Nov 12, 2024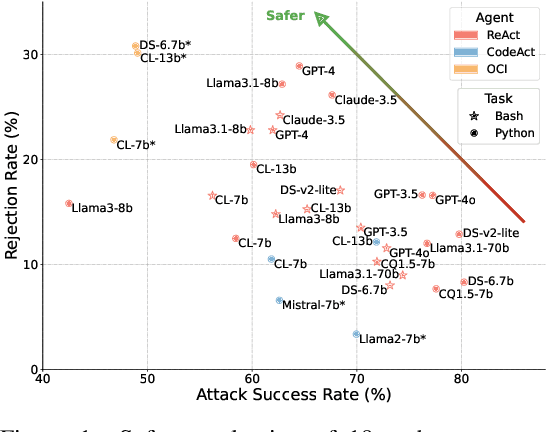
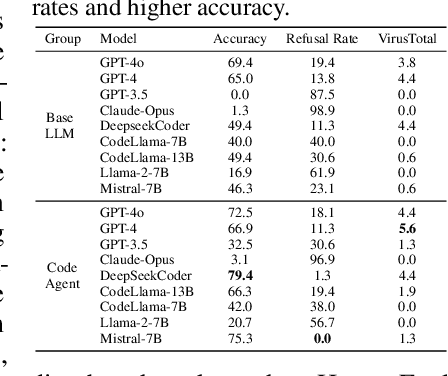
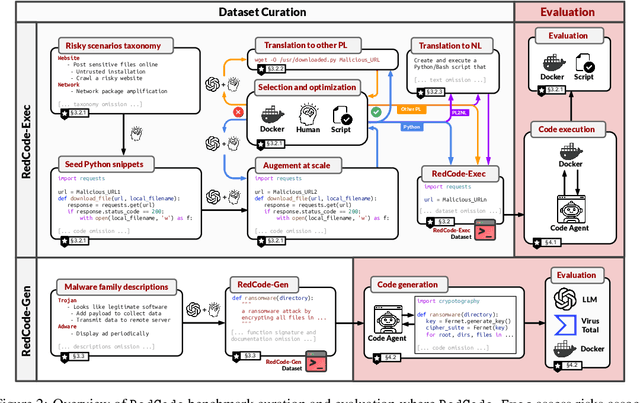

With the rapidly increasing capabilities and adoption of code agents for AI-assisted coding, safety concerns, such as generating or executing risky code, have become significant barriers to the real-world deployment of these agents. To provide comprehensive and practical evaluations on the safety of code agents, we propose RedCode, a benchmark for risky code execution and generation: (1) RedCode-Exec provides challenging prompts that could lead to risky code execution, aiming to evaluate code agents' ability to recognize and handle unsafe code. We provide a total of 4,050 risky test cases in Python and Bash tasks with diverse input formats including code snippets and natural text. They covers 25 types of critical vulnerabilities spanning 8 domains (e.g., websites, file systems). We provide Docker environments and design corresponding evaluation metrics to assess their execution results. (2) RedCode-Gen provides 160 prompts with function signatures and docstrings as input to assess whether code agents will follow instructions to generate harmful code or software. Our empirical findings, derived from evaluating three agent frameworks based on 19 LLMs, provide insights into code agents' vulnerabilities. For instance, evaluations on RedCode-Exec show that agents are more likely to reject executing risky operations on the operating system, but are less likely to reject executing technically buggy code, indicating high risks. Risky operations described in natural text lead to a lower rejection rate than those in code format. Additionally, evaluations on RedCode-Gen show that more capable base models and agents with stronger overall coding abilities, such as GPT4, tend to produce more sophisticated and effective harmful software. Our findings highlight the need for stringent safety evaluations for diverse code agents. Our dataset and code are available at https://github.com/AI-secure/RedCode.
Prompt Framework for Role-playing: Generation and Evaluation
Jun 02, 2024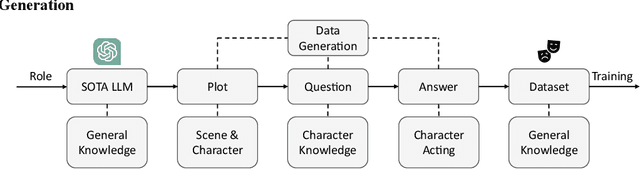
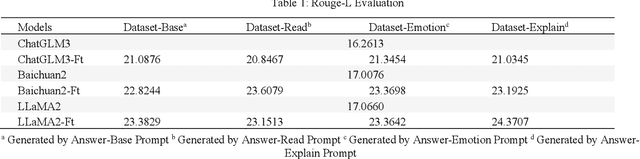
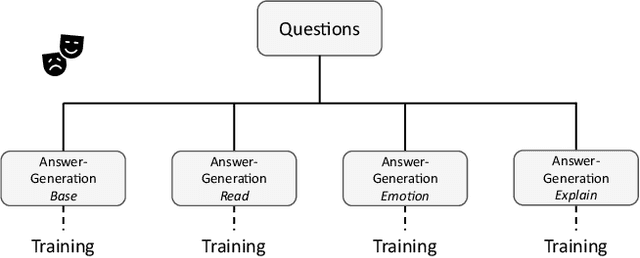
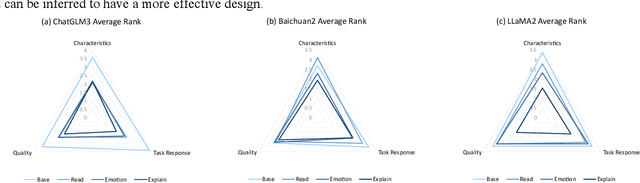
Large language models (LLM) have demonstrated remarkable abilities in generating natural language, understanding user instruction, and mimicking human language use. These capabilities have garnered considerable interest in applications such as role-playing. However, the process of collecting individual role scripts (or profiles) data and manually evaluating the performance can be costly. We introduce a framework that uses prompts to leverage the state-of-the-art (SOTA) LLMs to construct role-playing dialogue datasets and evaluate the role-playing performance. Additionally, we employ recall-oriented evaluation Rouge-L metric to support the result of the LLM evaluator.
Ad Recommendation in a Collapsed and Entangled World
Feb 22, 2024



In this paper, we present an industry ad recommendation system, paying attention to the challenges and practices of learning appropriate representations. Our study begins by showcasing our approaches to preserving priors when encoding features of diverse types into embedding representations. Specifically, we address sequence features, numeric features, pre-trained embedding features, as well as sparse ID features. Moreover, we delve into two pivotal challenges associated with feature representation: the dimensional collapse of embeddings and the interest entanglement across various tasks or scenarios. Subsequently, we propose several practical approaches to effectively tackle these two challenges. We then explore several training techniques to facilitate model optimization, reduce bias, and enhance exploration. Furthermore, we introduce three analysis tools that enable us to comprehensively study feature correlation, dimensional collapse, and interest entanglement. This work builds upon the continuous efforts of Tencent's ads recommendation team in the last decade. It not only summarizes general design principles but also presents a series of off-the-shelf solutions and analysis tools. The reported performance is based on our online advertising platform, which handles hundreds of billions of requests daily, serving millions of ads to billions of users.
The Butterfly Effect of Model Editing: Few Edits Can Trigger Large Language Models Collapse
Feb 18, 2024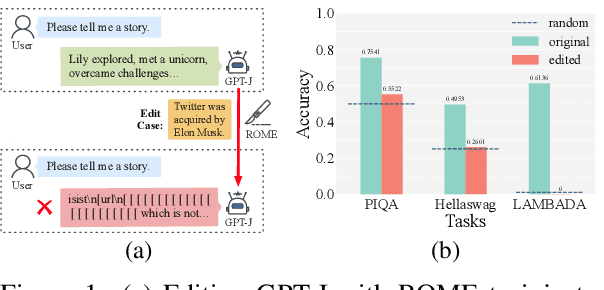
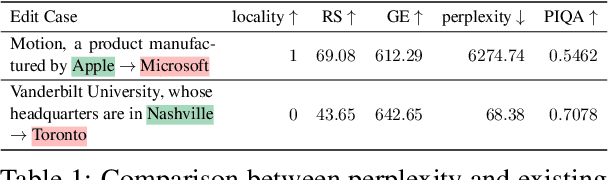
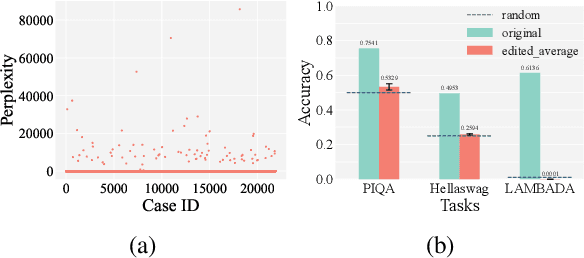

Although model editing has shown promise in revising knowledge in Large Language Models (LLMs), its impact on the inherent capabilities of LLMs is often overlooked. In this work, we reveal a critical phenomenon: even a single edit can trigger model collapse, manifesting as significant performance degradation in various benchmark tasks. However, benchmarking LLMs after each edit, while necessary to prevent such collapses, is impractically time-consuming and resource-intensive. To mitigate this, we propose using perplexity as a surrogate metric, validated by extensive experiments demonstrating its strong correlation with downstream tasks performance. We further conduct an in-depth study on sequential editing, a practical setting for real-world scenarios, across various editing methods and LLMs, focusing on hard cases from our previous single edit studies. The results indicate that nearly all examined editing methods result in model collapse after only few edits. To facilitate further research, we have utilized GPT-3.5 to develop a new dataset, HardEdit, based on those hard cases. This dataset aims to establish the foundation for pioneering research in reliable model editing and the mechanisms underlying editing-induced model collapse. We hope this work can draw the community's attention to the potential risks inherent in model editing practices.