Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Framework for Role-playing: Generation and Evaluation
Paper and Code
Jun 02, 2024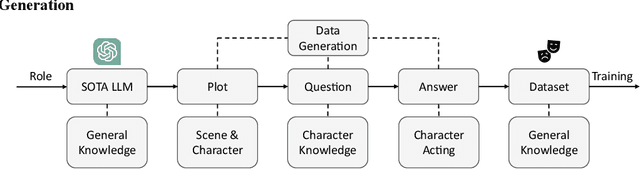
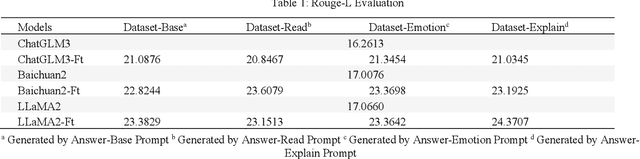
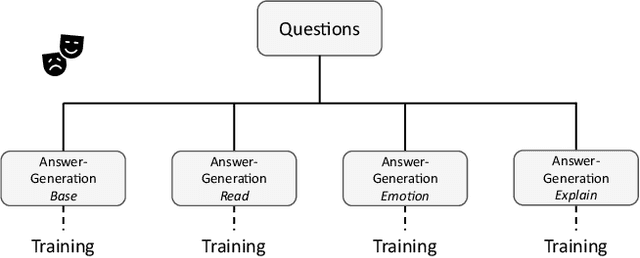
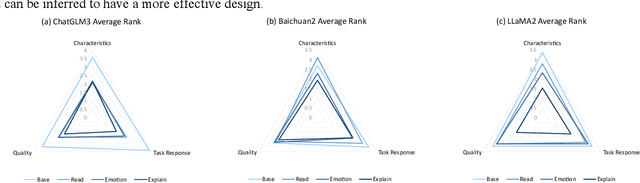
Large language models (LLM) have demonstrated remarkable abilities in generating natural language, understanding user instruction, and mimicking human language use. These capabilities have garnered considerable interest in applications such as role-playing. However, the process of collecting individual role scripts (or profiles) data and manually evaluating the performance can be costly. We introduce a framework that uses prompts to leverage the state-of-the-art (SOTA) LLMs to construct role-playing dialogue datasets and evaluate the role-playing performance. Additionally, we employ recall-oriented evaluation Rouge-L metric to support the result of the LLM evaluator.
View paper on