 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward a Sustainable Federated Learning Ecosystem: A Practical Least Core Mechanism for Payoff Allocation
Feb 03, 2026Emerging network paradigms and applications increasingly rely on federated learning (FL) to enable collaborative intelligence while preserving privacy. However, the sustainability of such collaborative environments hinges on a fair and stable payoff allocation mechanism. Focusing on coalition stability, this paper introduces a payoff allocation framework based on the least core (LC) concept. Unlike traditional methods, the LC prioritizes the cohesion of the federation by minimizing the maximum dissatisfaction among all potential subgroups, ensuring that no participant has an incentive to break away. To adapt this game-theoretic concept to practical, large-scale networks, we propose a streamlined implementation with a stack-based pruning algorithm, effectively balancing computational efficiency with allocation precision. Case studies in federated intrusion detection demonstrate that our mechanism correctly identifies pivotal contributors and strategic alliances. The results confirm that the practical LC framework promotes stable collaboration and fosters a sustainable FL ecosystem.
Prompt Framework for Role-playing: Generation and Evaluation
Jun 02, 2024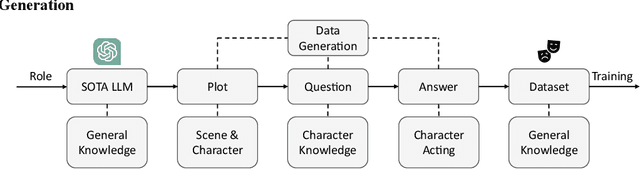
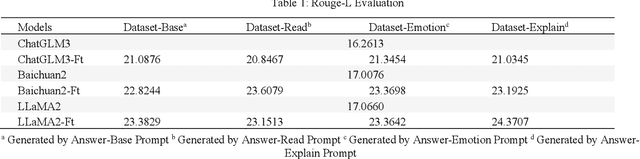
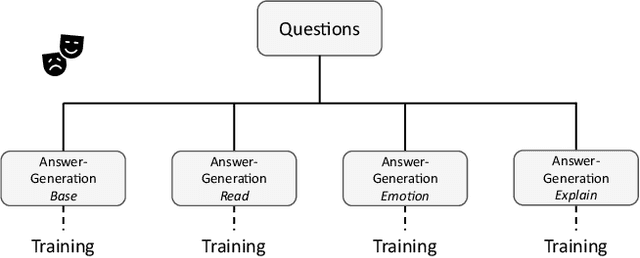
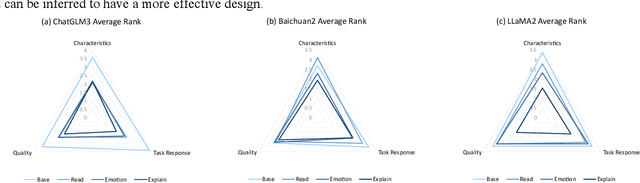
Large language models (LLM) have demonstrated remarkable abilities in generating natural language, understanding user instruction, and mimicking human language use. These capabilities have garnered considerable interest in applications such as role-playing. However, the process of collecting individual role scripts (or profiles) data and manually evaluating the performance can be costly. We introduce a framework that uses prompts to leverage the state-of-the-art (SOTA) LLMs to construct role-playing dialogue datasets and evaluate the role-playing performance. Additionally, we employ recall-oriented evaluation Rouge-L metric to support the result of the LLM evaluator.