 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlex Attention: A Programming Model for Generating Optimized Attention Kernels
Dec 07, 2024Over the past 7 years, attention has become one of the most important primitives in deep learning. The primary approach to optimize attention is FlashAttention, which fuses the operation together, drastically improving both the runtime and the memory consumption. However, the importance of FlashAttention combined with its monolithic nature poses a problem for researchers aiming to try new attention variants -- a "software lottery". This problem is exacerbated by the difficulty of writing efficient fused attention kernels, resisting traditional compiler-based approaches. We introduce FlexAttention, a novel compiler-driven programming model that allows implementing the majority of attention variants in a few lines of idiomatic PyTorch code. We demonstrate that many existing attention variants (e.g. Alibi, Document Masking, PagedAttention, etc.) can be implemented via FlexAttention, and that we achieve competitive performance compared to these handwritten kernels. Finally, we demonstrate how FlexAttention allows for easy composition of attention variants, solving the combinatorial explosion of attention variants.
Apache Submarine: A Unified Machine Learning Platform Made Simple
Aug 22, 2021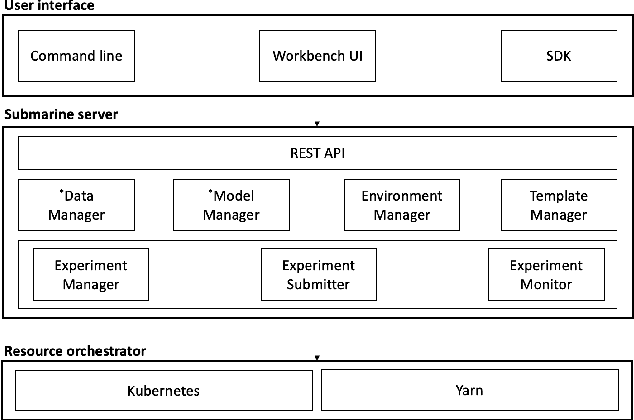
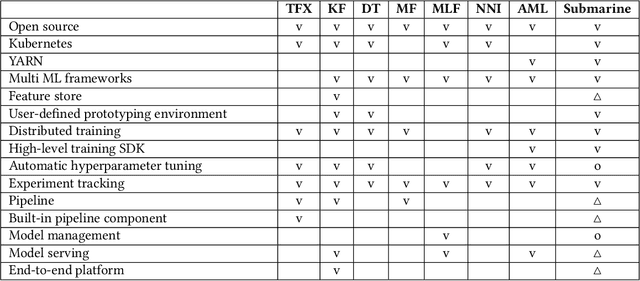
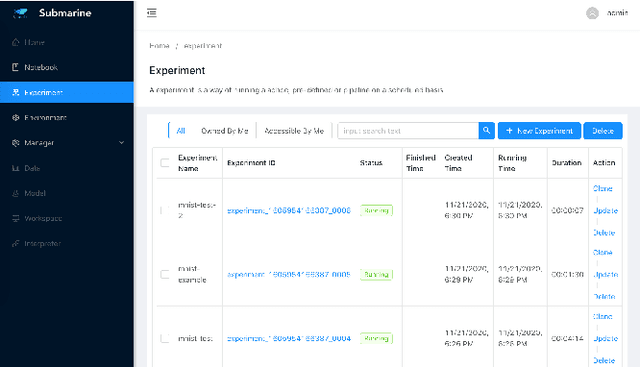
As machine learning is applied more widely, it is necessary to have a machine learning platform for both infrastructure administrators and users including expert data scientists and citizen data scientists to improve their productivity. However, existing machine learning platforms are ill-equipped to address the "Machine Learning tech debts" such as glue code, reproducibility, and portability. Furthermore, existing platforms only take expert data scientists into consideration, and thus they are inflexible for infrastructure administrators and non-user-friendly for citizen data scientists. We propose Submarine, a unified machine learning platform, to address the challenges.