 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBROTHER: Behavioral Recognition Optimized Through Heterogeneous Ensemble Regularization for Ambivalence and Hesitancy
Mar 15, 2026Recognizing complex behavioral states such as Ambivalence and Hesitancy (A/H) in naturalistic video settings remains a significant challenge in affective computing. Unlike basic facial expressions, A/H manifests as subtle, multimodal conflicts that require deep contextual and temporal understanding. In this paper, we propose a highly regularized, multimodal fusion pipeline to predict A/H at the video level. We extract robust unimodal features from visual, acoustic, and linguistic data, introducing a specialized statistical text modality explicitly designed to capture temporal speech variations and behavioral cues. To identify the most effective representations, we evaluate 15 distinct modality combinations across a committee of machine learning classifiers (MLP, Random Forest, and GBDT), selecting the most well-calibrated models based on validation Binary Cross-Entropy (BCE) loss. Furthermore, to optimally fuse these heterogeneous models without overfitting to the training distribution, we implement a Particle Swarm Optimization (PSO) hard-voting ensemble. The PSO fitness function dynamically incorporates a train-validation gap penalty (lambda) to actively suppress redundant or overfitted classifiers. Our comprehensive evaluation demonstrates that while linguistic features serve as the strongest independent predictor of A/H, our heavily regularized PSO ensemble (lambda = 0.2) effectively harnesses multimodal synergies, achieving a peak Macro F1-score of 0.7465 on the unseen test set. These results emphasize that treating ambivalence and hesitancy as a multimodal conflict, evaluated through an intelligently weighted committee, provides a robust framework for in-the-wild behavioral analysis.
All by Myself: Learning Individualized Competitive Behaviour with a Contrastive Reinforcement Learning optimization
Oct 02, 2023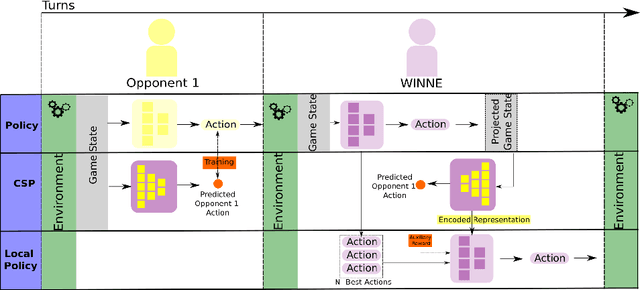
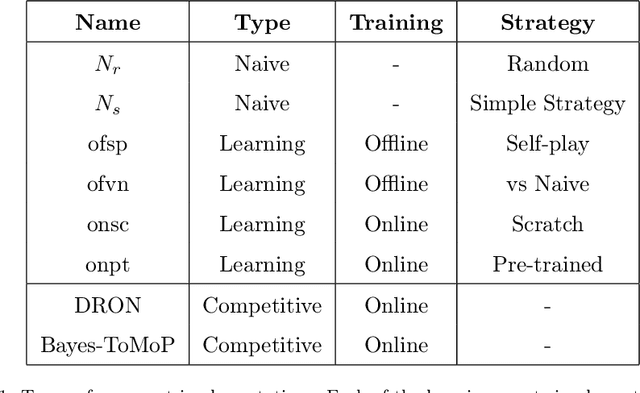
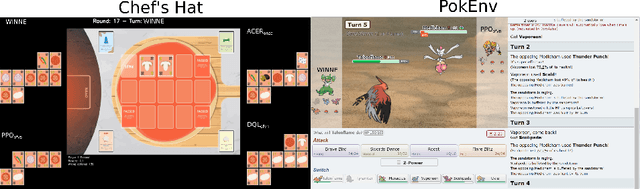
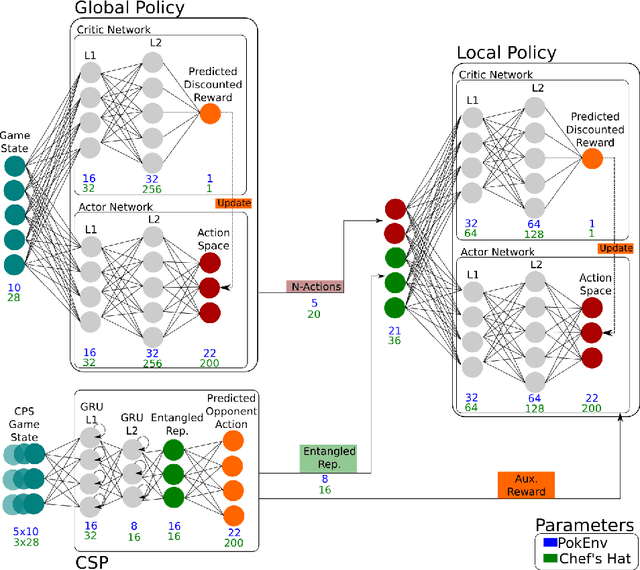
In a competitive game scenario, a set of agents have to learn decisions that maximize their goals and minimize their adversaries' goals at the same time. Besides dealing with the increased dynamics of the scenarios due to the opponents' actions, they usually have to understand how to overcome the opponent's strategies. Most of the common solutions, usually based on continual learning or centralized multi-agent experiences, however, do not allow the development of personalized strategies to face individual opponents. In this paper, we propose a novel model composed of three neural layers that learn a representation of a competitive game, learn how to map the strategy of specific opponents, and how to disrupt them. The entire model is trained online, using a composed loss based on a contrastive optimization, to learn competitive and multiplayer games. We evaluate our model on a pokemon duel scenario and the four-player competitive Chef's Hat card game. Our experiments demonstrate that our model achieves better performance when playing against offline, online, and competitive-specific models, in particular when playing against the same opponent multiple times. We also present a discussion on the impact of our model, in particular on how well it deals with on specific strategy learning for each of the two scenarios.
I am Only Happy When There is Light: The Impact of Environmental Changes on Affective Facial Expressions Recognition
Oct 28, 2022
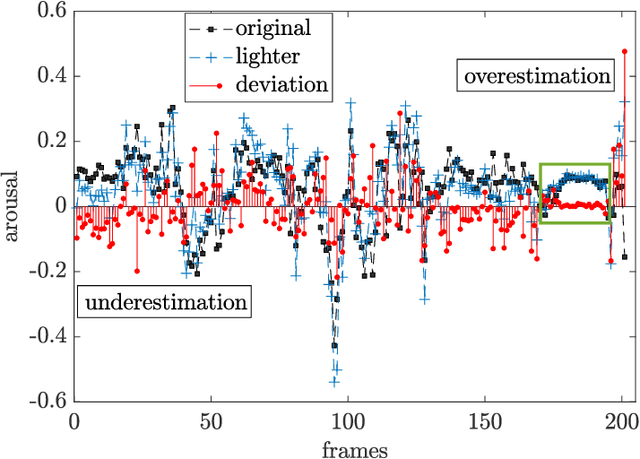
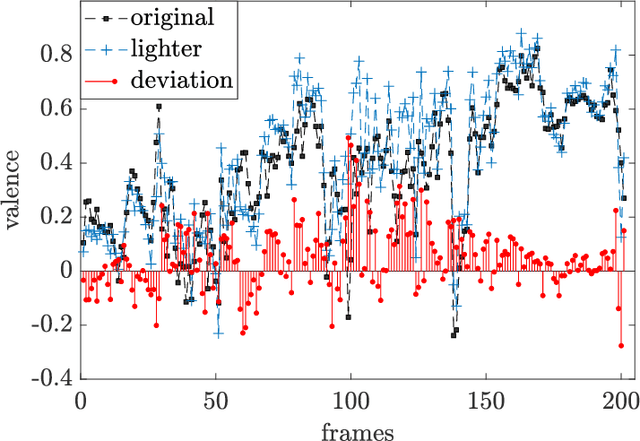
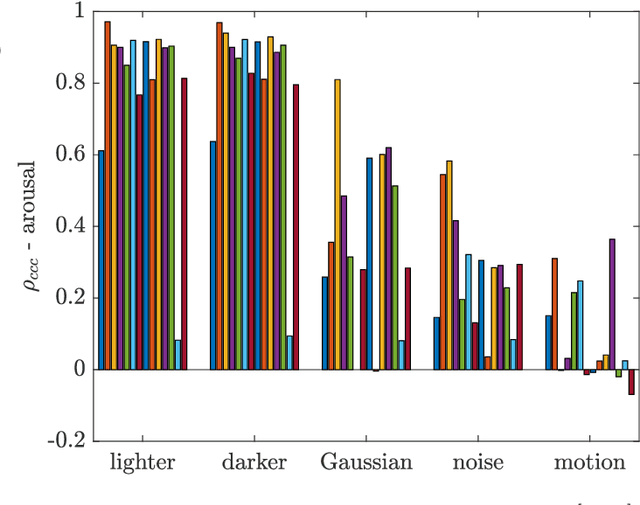
Human-robot interaction (HRI) benefits greatly from advances in the machine learning field as it allows researchers to employ high-performance models for perceptual tasks like detection and recognition. Especially deep learning models, either pre-trained for feature extraction or used for classification, are now established methods to characterize human behaviors in HRI scenarios and to have social robots that understand better those behaviors. As HRI experiments are usually small-scale and constrained to particular lab environments, the questions are how well can deep learning models generalize to specific interaction scenarios, and further, how good is their robustness towards environmental changes? These questions are important to address if the HRI field wishes to put social robotic companions into real environments acting consistently, i.e. changing lighting conditions or moving people should still produce the same recognition results. In this paper, we study the impact of different image conditions on the recognition of arousal and valence from human facial expressions using the FaceChannel framework \cite{Barro20}. Our results show how the interpretation of human affective states can differ greatly in either the positive or negative direction even when changing only slightly the image properties. We conclude the paper with important points to consider when employing deep learning models to ensure sound interpretation of HRI experiments.
Incorporating Rivalry in Reinforcement Learning for a Competitive Game
Aug 22, 2022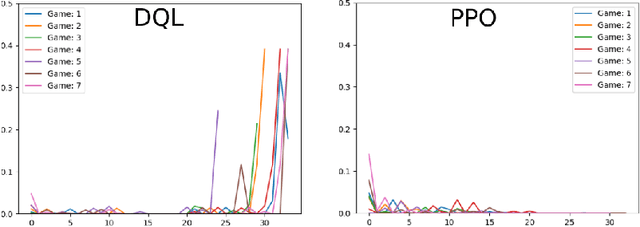
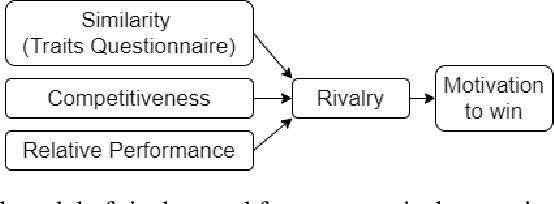
Recent advances in reinforcement learning with social agents have allowed such models to achieve human-level performance on specific interaction tasks. However, most interactive scenarios do not have a version alone as an end goal; instead, the social impact of these agents when interacting with humans is as important and largely unexplored. In this regard, this work proposes a novel reinforcement learning mechanism based on the social impact of rivalry behavior. Our proposed model aggregates objective and social perception mechanisms to derive a rivalry score that is used to modulate the learning of artificial agents. To investigate our proposed model, we design an interactive game scenario, using the Chef's Hat Card Game, and examine how the rivalry modulation changes the agent's playing style, and how this impacts the experience of human players in the game. Our results show that humans can detect specific social characteristics when playing against rival agents when compared to common agents, which directly affects the performance of the human players in subsequent games. We conclude our work by discussing how the different social and objective features that compose the artificial rivalry score contribute to our results.
CIAO! A Contrastive Adaptation Mechanism for Non-Universal Facial Expression Recognition
Aug 10, 2022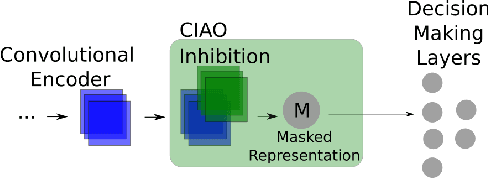
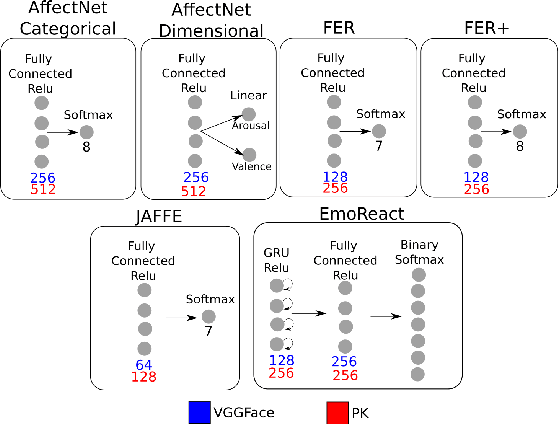
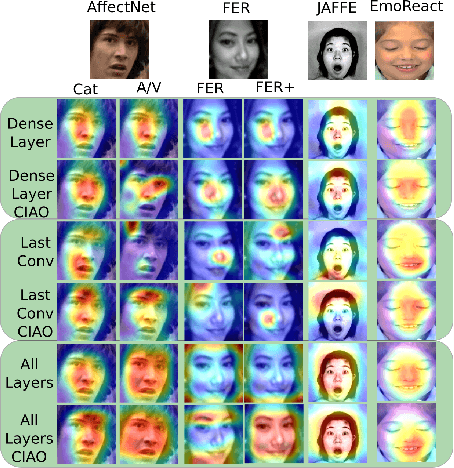
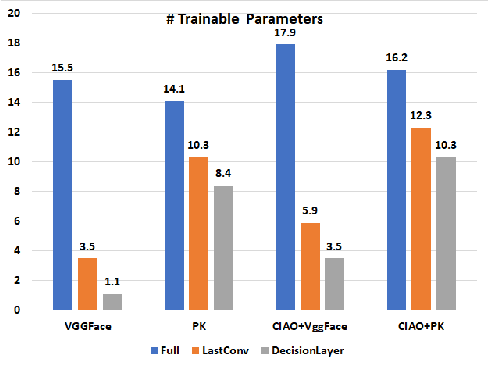
Current facial expression recognition systems demand an expensive re-training routine when deployed to different scenarios than they were trained for. Biasing them towards learning specific facial characteristics, instead of performing typical transfer learning methods, might help these systems to maintain high performance in different tasks, but with a reduced training effort. In this paper, we propose Contrastive Inhibitory Adaptati On (CIAO), a mechanism that adapts the last layer of facial encoders to depict specific affective characteristics on different datasets. CIAO presents an improvement in facial expression recognition performance over six different datasets with very unique affective representations, in particular when compared with state-of-the-art models. In our discussions, we make an in-depth analysis of how the learned high-level facial features are represented, and how they contribute to each individual dataset's characteristics. We finalize our study by discussing how CIAO positions itself within the range of recent findings on non-universal facial expressions perception, and its impact on facial expression recognition research.
How Can AI Recognize Pain and Express Empathy
Oct 08, 2021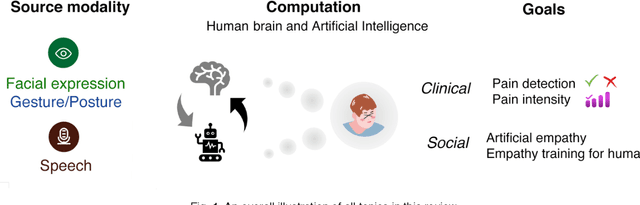
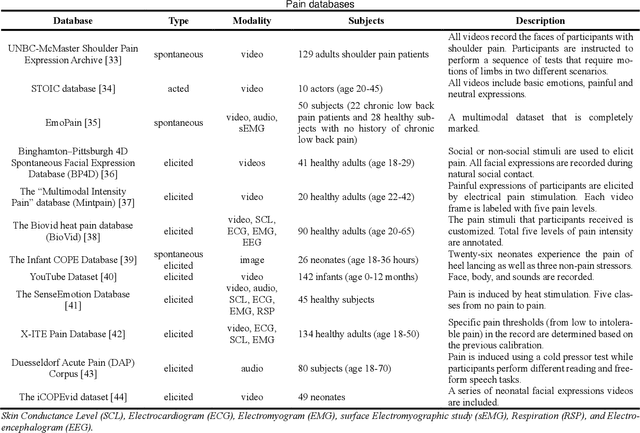
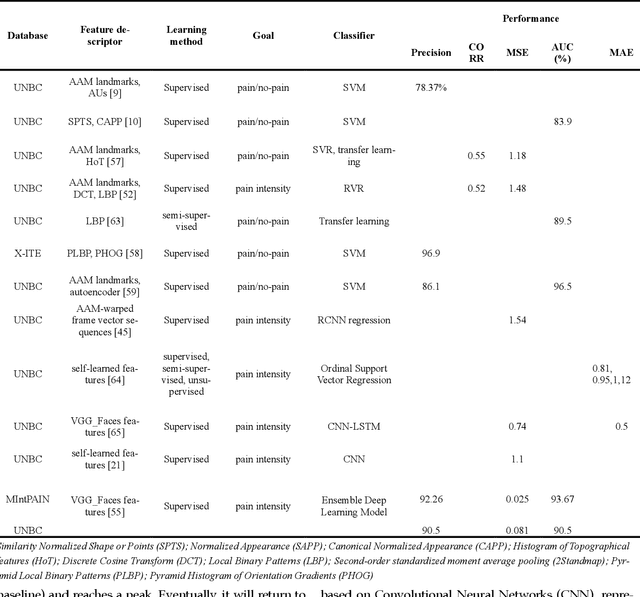
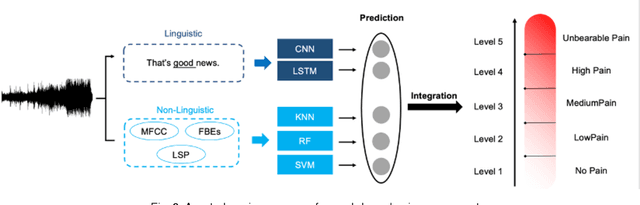
Sensory and emotional experiences such as pain and empathy are relevant to mental and physical health. The current drive for automated pain recognition is motivated by a growing number of healthcare requirements and demands for social interaction make it increasingly essential. Despite being a trending area, they have not been explored in great detail. Over the past decades, behavioral science and neuroscience have uncovered mechanisms that explain the manifestations of pain. Recently, also artificial intelligence research has allowed empathic machine learning methods to be approachable. Generally, the purpose of this paper is to review the current developments for computational pain recognition and artificial empathy implementation. Our discussion covers the following topics: How can AI recognize pain from unimodality and multimodality? Is it necessary for AI to be empathic? How can we create an AI agent with proactive and reactive empathy? This article explores the challenges and opportunities of real-world multimodal pain recognition from a psychological, neuroscientific, and artificial intelligence perspective. Finally, we identify possible future implementations of artificial empathy and analyze how humans might benefit from an AI agent equipped with empathy.
Generating Data Augmentation samples for Semantic Segmentation of Salt Bodies in a Synthetic Seismic Image Dataset
Jun 17, 2021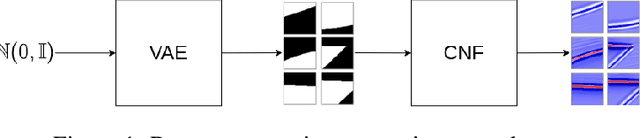
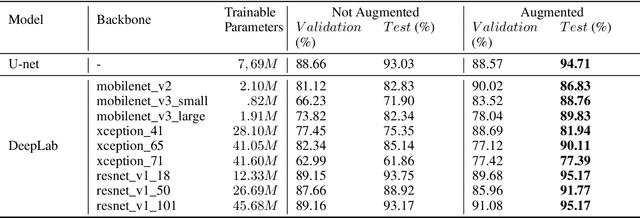
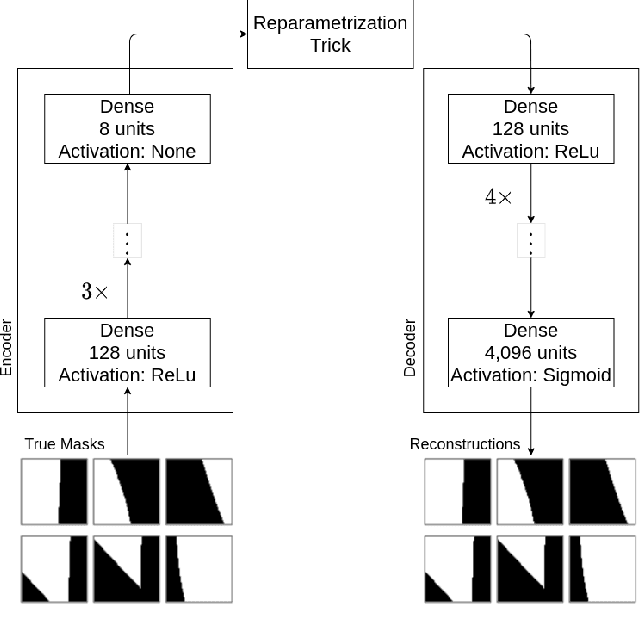
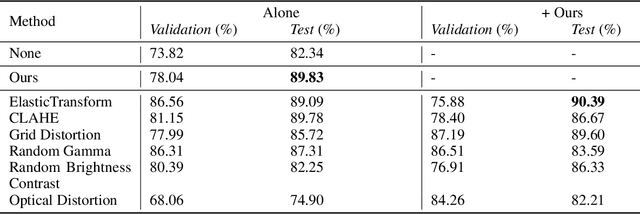
Nowadays, subsurface salt body localization and delineation, also called semantic segmentation of salt bodies, are among the most challenging geophysicist tasks. Thus, identifying large salt bodies is notoriously tricky and is crucial for identifying hydrocarbon reservoirs and drill path planning. This work proposes a Data Augmentation method based on training two generative models to augment the number of samples in a seismic image dataset for the semantic segmentation of salt bodies. Our method uses deep learning models to generate pairs of seismic image patches and their respective salt masks for the Data Augmentation. The first model is a Variational Autoencoder and is responsible for generating patches of salt body masks. The second is a Conditional Normalizing Flow model, which receives the generated masks as inputs and generates the associated seismic image patches. We evaluate the proposed method by comparing the performance of ten distinct state-of-the-art models for semantic segmentation, trained with and without the generated augmentations, in a dataset from two synthetic seismic images. The proposed methodology yields an average improvement of 8.57% in the IoU metric across all compared models. The best result is achieved by a DeeplabV3+ model variant, which presents an IoU score of 95.17% when trained with our augmentations. Additionally, our proposal outperformed six selected data augmentation methods, and the most significant improvement in the comparison, of 9.77%, is achieved by composing our DA with augmentations from an elastic transformation. At last, we show that the proposed method is adaptable for a larger context size by achieving results comparable to the obtained on the smaller context size.
I Only Have Eyes for You: The Impact of Masks On Convolutional-Based Facial Expression Recognition
Apr 16, 2021
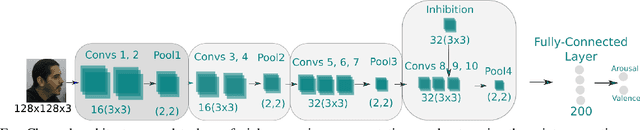
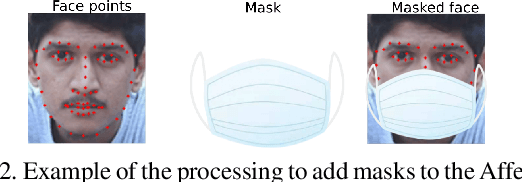

The current COVID-19 pandemic has shown us that we are still facing unpredictable challenges in our society. The necessary constrain on social interactions affected heavily how we envision and prepare the future of social robots and artificial agents in general. Adapting current affective perception models towards constrained perception based on the hard separation between facial perception and affective understanding would help us to provide robust systems. In this paper, we perform an in-depth analysis of how recognizing affect from persons with masks differs from general facial expression perception. We evaluate how the recently proposed FaceChannel adapts towards recognizing facial expressions from persons with masks. In Our analysis, we evaluate different training and fine-tuning schemes to understand better the impact of masked facial expressions. We also perform specific feature-level visualization to demonstrate how the inherent capabilities of the FaceChannel to learn and combine facial features change when in a constrained social interaction scenario.
A Sub-Layered Hierarchical Pyramidal Neural Architecture for Facial Expression Recognition
Mar 23, 2021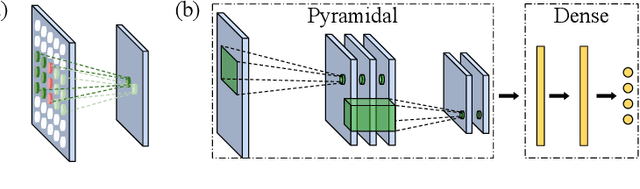

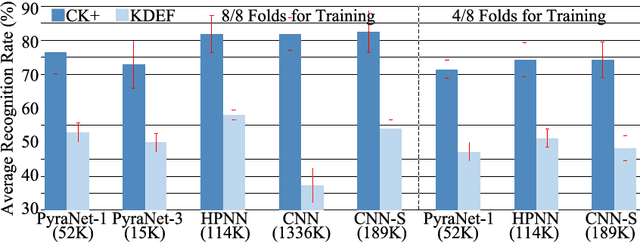

In domains where computational resources and labeled data are limited, such as in robotics, deep networks with millions of weights might not be the optimal solution. In this paper, we introduce a connectivity scheme for pyramidal architectures to increase their capacity for learning features. Experiments on facial expression recognition of unseen people demonstrate that our approach is a potential candidate for applications with restricted resources, due to good generalization performance and low computational cost. We show that our approach generalizes as well as convolutional architectures in this task but uses fewer trainable parameters and is more robust for low-resolution faces.
Disambiguating Affective Stimulus Associations for Robot Perception and Dialogue
Mar 05, 2021

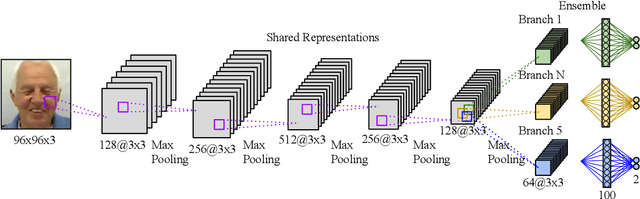
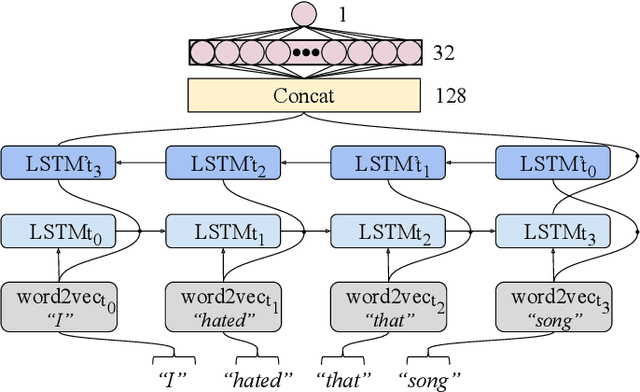
Effectively recognising and applying emotions to interactions is a highly desirable trait for social robots. Implicitly understanding how subjects experience different kinds of actions and objects in the world is crucial for natural HRI interactions, with the possibility to perform positive actions and avoid negative actions. In this paper, we utilize the NICO robot's appearance and capabilities to give the NICO the ability to model a coherent affective association between a perceived auditory stimulus and a temporally asynchronous emotion expression. This is done by combining evaluations of emotional valence from vision and language. NICO uses this information to make decisions about when to extend conversations in order to accrue more affective information if the representation of the association is not coherent. Our primary contribution is providing a NICO robot with the ability to learn the affective associations between a perceived auditory stimulus and an emotional expression. NICO is able to do this for both individual subjects and specific stimuli, with the aid of an emotion-driven dialogue system that rectifies emotional expression incoherences. The robot is then able to use this information to determine a subject's enjoyment of perceived auditory stimuli in a real HRI scenario.