 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Data Augmentation samples for Semantic Segmentation of Salt Bodies in a Synthetic Seismic Image Dataset
Jun 17, 2021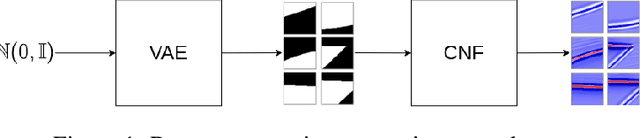
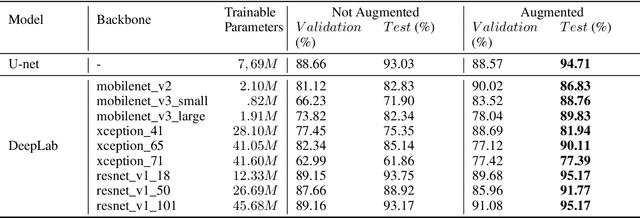
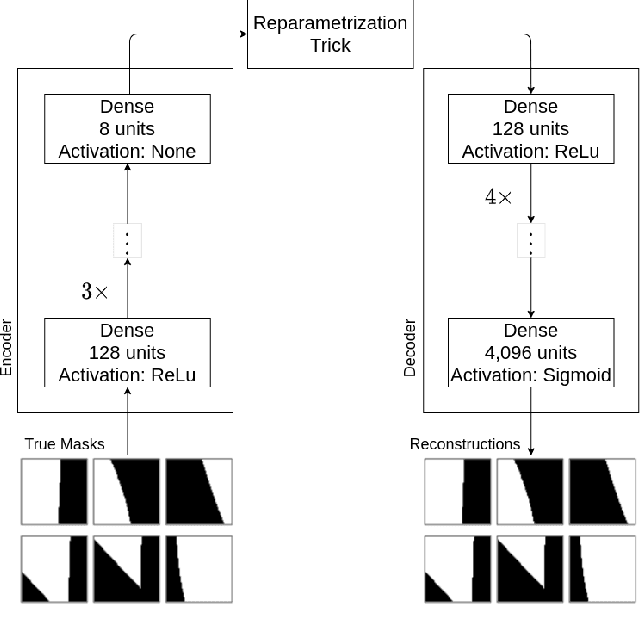
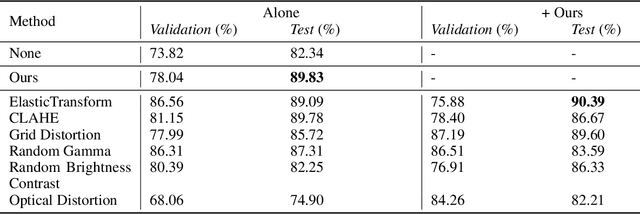
Nowadays, subsurface salt body localization and delineation, also called semantic segmentation of salt bodies, are among the most challenging geophysicist tasks. Thus, identifying large salt bodies is notoriously tricky and is crucial for identifying hydrocarbon reservoirs and drill path planning. This work proposes a Data Augmentation method based on training two generative models to augment the number of samples in a seismic image dataset for the semantic segmentation of salt bodies. Our method uses deep learning models to generate pairs of seismic image patches and their respective salt masks for the Data Augmentation. The first model is a Variational Autoencoder and is responsible for generating patches of salt body masks. The second is a Conditional Normalizing Flow model, which receives the generated masks as inputs and generates the associated seismic image patches. We evaluate the proposed method by comparing the performance of ten distinct state-of-the-art models for semantic segmentation, trained with and without the generated augmentations, in a dataset from two synthetic seismic images. The proposed methodology yields an average improvement of 8.57% in the IoU metric across all compared models. The best result is achieved by a DeeplabV3+ model variant, which presents an IoU score of 95.17% when trained with our augmentations. Additionally, our proposal outperformed six selected data augmentation methods, and the most significant improvement in the comparison, of 9.77%, is achieved by composing our DA with augmentations from an elastic transformation. At last, we show that the proposed method is adaptable for a larger context size by achieving results comparable to the obtained on the smaller context size.
Prior Flow Variational Autoencoder: A density estimation model for Non-Intrusive Load Monitoring
Nov 30, 2020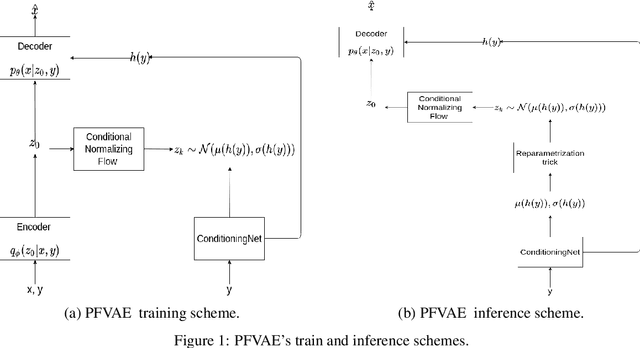
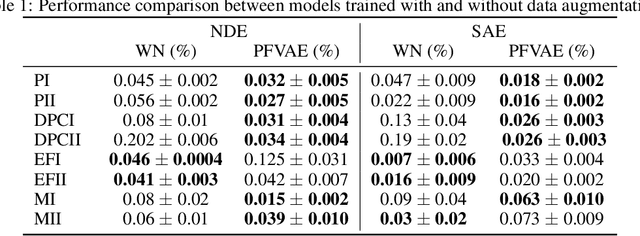
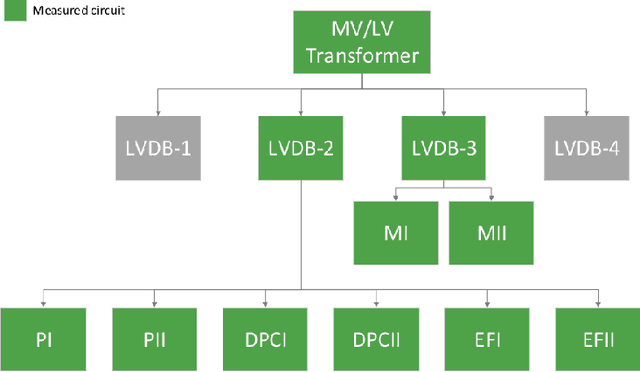
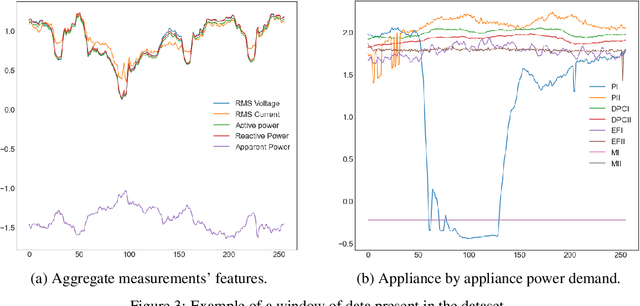
Non-Intrusive Load Monitoring (NILM) is a computational technique to estimate the power loads' appliance-by-appliance from the whole consumption measured by a single meter. In this paper, we propose a conditional density estimation model, based on deep neural networks, that joins a Conditional Variational Autoencoder with a Conditional Invertible Normalizing Flow model to estimate the individual appliance's power demand. The resulting model is called Prior Flow Variational Autoencoder or, for simplicity PFVAE. Thus, instead of having one model per appliance, the resulting model is responsible for estimating the power demand, appliance-by-appliance, at once. We train and evaluate our proposed model in a publicly available dataset composed of power demand measures from a poultry feed factory located in Brazil. The proposed model's quality is evaluated by comparing the obtained normalized disaggregation error (NDE) and signal aggregated error (SAE) with the previous work values on the same dataset. Our proposal achieves highly competitive results, and for six of the eight machines belonging to the dataset, we observe consistent improvements that go from 28% up to 81% in NDE and from 27% up to 86% in SAE.
SeismoFlow -- Data augmentation for the class imbalance problem
Sep 02, 2020



In several application areas, such as medical diagnosis, spam filtering, fraud detection, and seismic data analysis, it is very usual to find relevant classification tasks where some class occurrences are rare. This is the so called class imbalance problem, which is a challenge in machine learning. In this work, we propose the SeismoFlow a flow-based generative model to create synthetic samples, aiming to address the class imbalance. Inspired by the Glow model, it uses interpolation on the learned latent space to produce synthetic samples for one rare class. We apply our approach to the development of a seismogram signal quality classifier. We introduce a dataset composed of5.223seismograms that are distributed between the good, medium, and bad classes and with their respective frequencies of 66.68%,31.54%, and 1.76%. Our methodology is evaluated on a stratified 10-fold cross-validation setting, using the Miniceptionmodel as a baseline, and assessing the effects of adding the generated samples on the training set of each iteration. In our experiments, we achieve an improvement of 13.9% on the rare class F1-score, while not hurting the metric value for the other classes and thus observing the overall accuracy improvement. Our empirical findings indicate that our method can generate high-quality synthetic seismograms with realistic looking and sufficient plurality to help the Miniception model to overcome the class imbalance problem. We believe that our results are a step forward in solving both the task of seismogram signal quality classification and class imbalance.
Seismic Shot Gather Noise Localization Using a Multi-Scale Feature-Fusion-Based Neural Network
May 07, 2020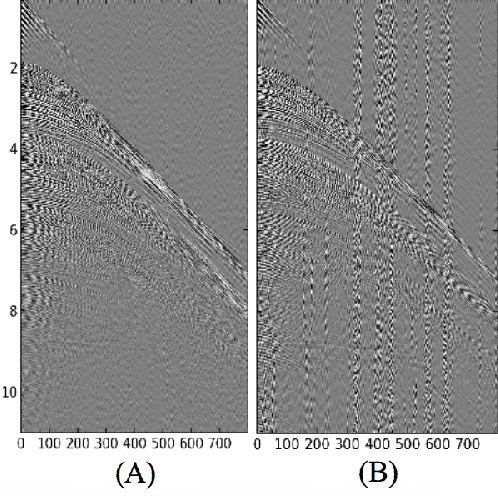

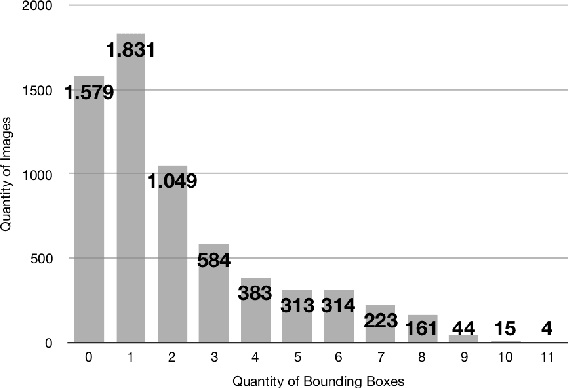
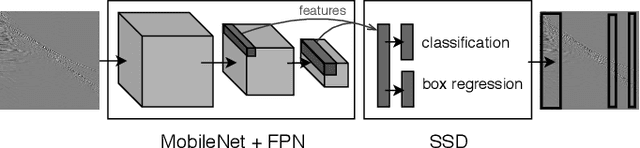
Deep learning-based models, such as convolutional neural networks, have advanced various segments of computer vision. However, this technology is rarely applied to seismic shot gather noise localization problem. This letter presents an investigation on the effectiveness of a multi-scale feature-fusion-based network for seismic shot-gather noise localization. Herein, we describe the following: (1) the construction of a real-world dataset of seismic noise localization based on 6,500 seismograms; (2) a multi-scale feature-fusion-based detector that uses the MobileNet combined with the Feature Pyramid Net as the backbone; and (3) the Single Shot multi-box detector for box classification/regression. Additionally, we propose the use of the Focal Loss function that improves the detector's prediction accuracy. The proposed detector achieves an AP@0.5 of 78.67\% in our empirical evaluation.
A Deep Convolutional Network for Seismic Shot-Gather Image Quality Classification
Dec 03, 2019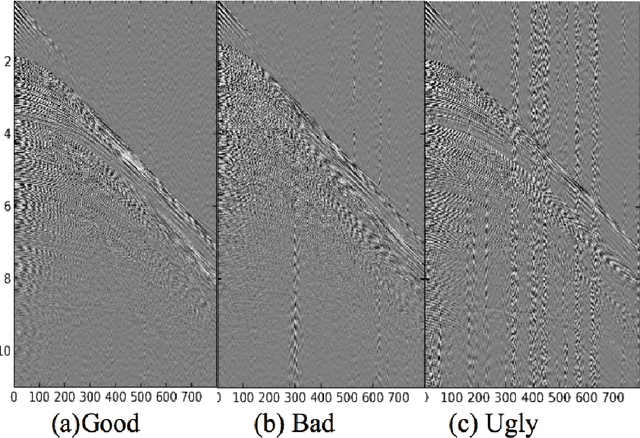

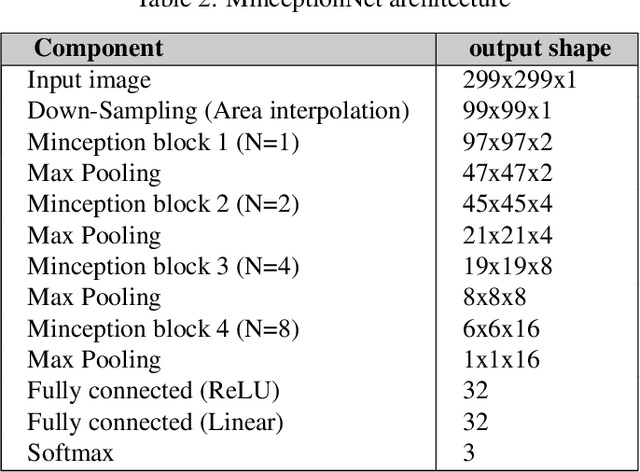
Deep Learning-based models such as Convolutional Neural Networks, have led to significant advancements in several areas of computing applications. Seismogram quality assurance is a relevant Geophysics task, since in the early stages of seismic processing, we are required to identify and fix noisy sail lines. In this work, we introduce a real-world seismogram quality classification dataset based on 6,613 examples, manually labeled by human experts as good, bad or ugly, according to their noise intensity. This dataset is used to train a CNN classifier for seismic shot-gathers quality prediction. In our empirical evaluation, we observe an F1-score of 93.56% in the test set.
Cumulative Sum Ranking
Nov 25, 2019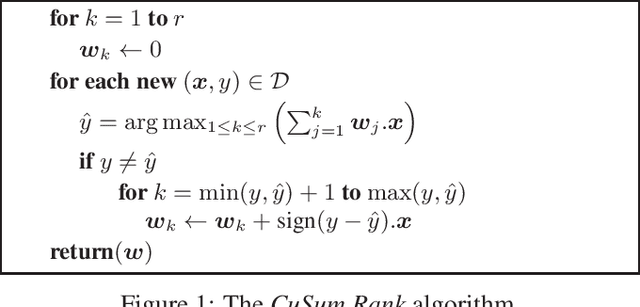
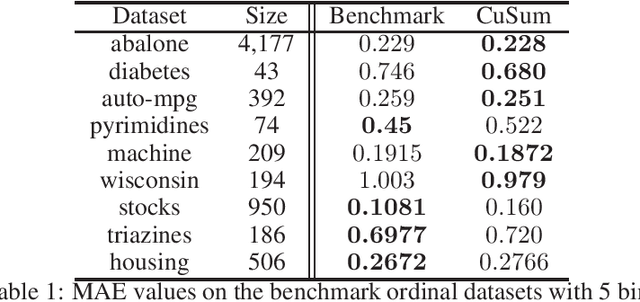
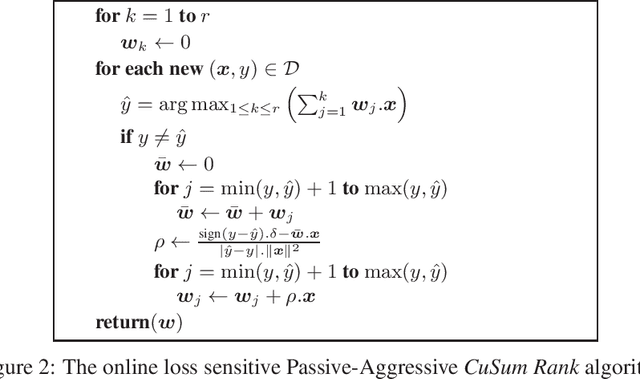

The goal of Ordinal Regression is to find a rule that ranks items from a given set. Several learning algorithms to solve this prediction problem build an ensemble of binary classifiers. Ranking by Projecting uses interdependent binary perceptrons. These perceptrons share the same direction vector, but use different bias values. Similar approaches use independent direction vectors and biases. To combine the binary predictions, most of them adopt a simple counting heuristics. Here, we introduce a novel cumulative sum scoring function to combine the binary predictions. The proposed score value aggregates the strength of each one of the relevant binary classifications on how large is the item's rank. We show that our modeling casts ordinal regression as a Structured Perceptron problem. As a consequence, we simplify its formulation and description, which results in two simple online learning algorithms. The second algorithm is a Passive-Aggressive version of the first algorithm. We show that under some rank separability condition both algorithms converge. Furthermore, we provide mistake bounds for each one of the two online algorithms. For the Passive-Aggressive version, we assume the knowledge of a separation margin, what significantly improves the corresponding mistake bound. Additionally, we show that Ranking by Projecting is a special case of our prediction algorithm. From a neural network architecture point of view, our empirical findings suggest a layer of cusum units for ordinal regression, instead of the usual softmax layer of multiclass problems.
Building a Massive Corpus for Named Entity Recognition using Free Open Data Sources
Aug 13, 2019
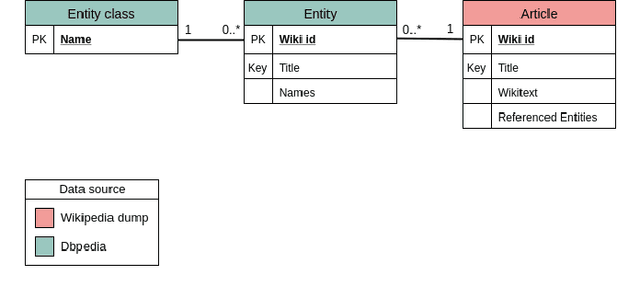
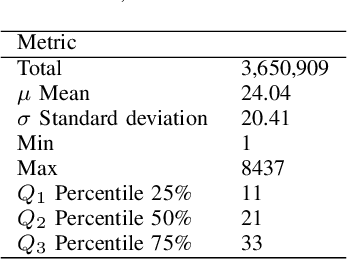
With the recent progress in machine learning, boosted by techniques such as deep learning, many tasks can be successfully solved once a large enough dataset is available for training. Nonetheless, human-annotated datasets are often expensive to produce, especially when labels are fine-grained, as is the case of Named Entity Recognition (NER), a task that operates with labels on a word-level. In this paper, we propose a method to automatically generate labeled datasets for NER from public data sources by exploiting links and structured data from DBpedia and Wikipedia. Due to the massive size of these data sources, the resulting dataset -- SESAME Available at https://sesame-pt.github.io -- is composed of millions of labeled sentences. We detail the method to generate the dataset, report relevant statistics, and design a baseline using a neural network, showing that our dataset helps building better NER predictors.