 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a Massive Corpus for Named Entity Recognition using Free Open Data Sources
Paper and Code
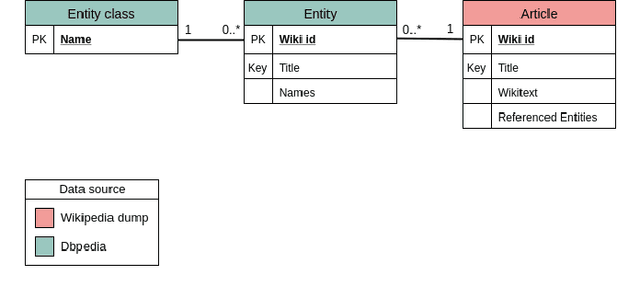
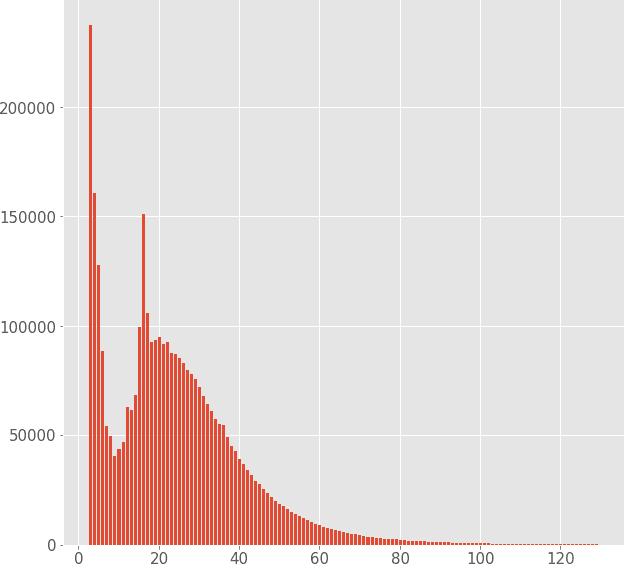
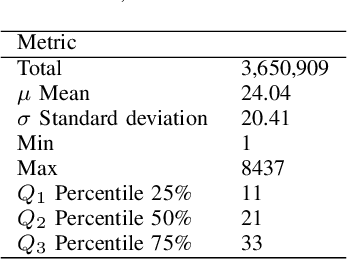
With the recent progress in machine learning, boosted by techniques such as deep learning, many tasks can be successfully solved once a large enough dataset is available for training. Nonetheless, human-annotated datasets are often expensive to produce, especially when labels are fine-grained, as is the case of Named Entity Recognition (NER), a task that operates with labels on a word-level. In this paper, we propose a method to automatically generate labeled datasets for NER from public data sources by exploiting links and structured data from DBpedia and Wikipedia. Due to the massive size of these data sources, the resulting dataset -- SESAME Available at https://sesame-pt.github.io -- is composed of millions of labeled sentences. We detail the method to generate the dataset, report relevant statistics, and design a baseline using a neural network, showing that our dataset helps building better NER predictors.