 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Classification of Financial Transactions Through Context-Fusion of Transformer-based Embeddings and Taxonomy-aware Attention Layer
Dec 12, 2023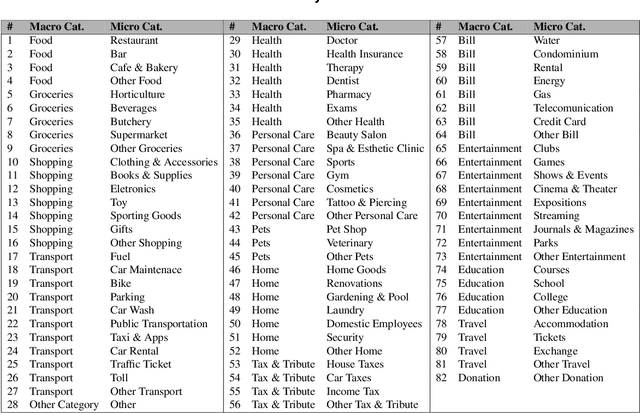
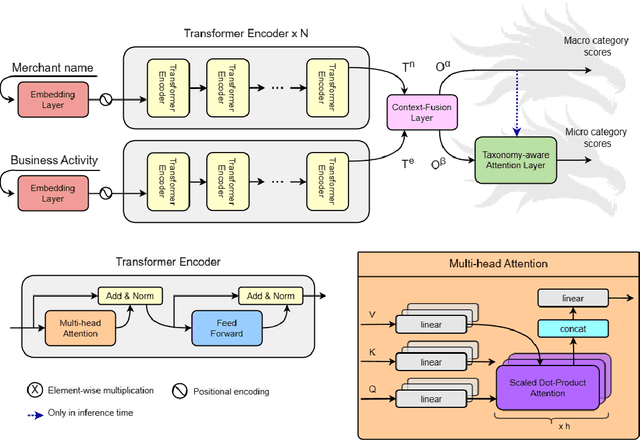
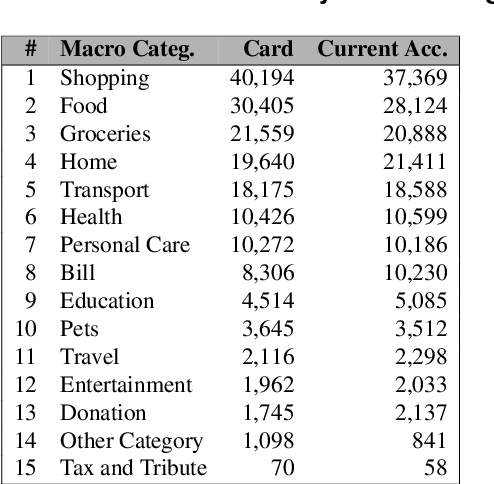
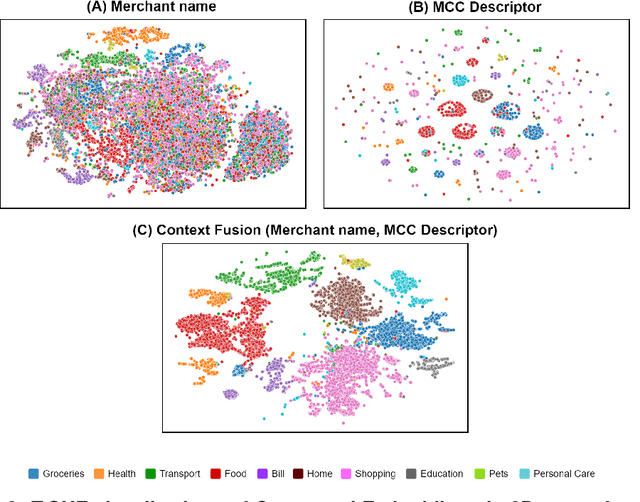
This work proposes the Two-headed DragoNet, a Transformer-based model for hierarchical multi-label classification of financial transactions. Our model is based on a stack of Transformers encoder layers that generate contextual embeddings from two short textual descriptors (merchant name and business activity), followed by a Context Fusion layer and two output heads that classify transactions according to a hierarchical two-level taxonomy (macro and micro categories). Finally, our proposed Taxonomy-aware Attention Layer corrects predictions that break categorical hierarchy rules defined in the given taxonomy. Our proposal outperforms classical machine learning methods in experiments of macro-category classification by achieving an F1-score of 93\% on a card dataset and 95% on a current account dataset.
Building a Noisy Audio Dataset to Evaluate Machine Learning Approaches for Automatic Speech Recognition Systems
Oct 04, 2021

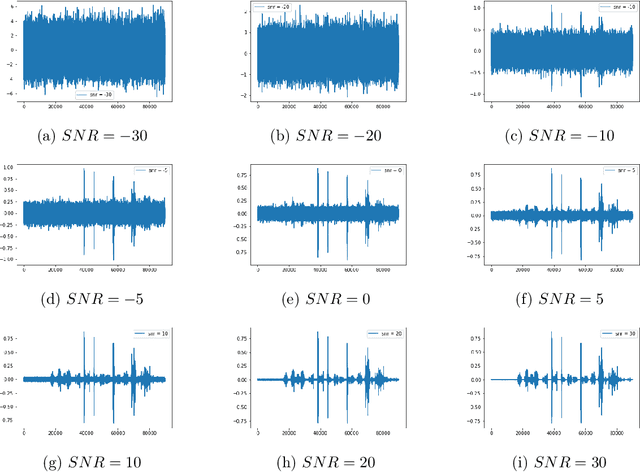
Automatic speech recognition systems are part of people's daily lives, embedded in personal assistants and mobile phones, helping as a facilitator for human-machine interaction while allowing access to information in a practically intuitive way. Such systems are usually implemented using machine learning techniques, especially with deep neural networks. Even with its high performance in the task of transcribing text from speech, few works address the issue of its recognition in noisy environments and, usually, the datasets used do not contain noisy audio examples, while only mitigating this issue using data augmentation techniques. This work aims to present the process of building a dataset of noisy audios, in a specific case of degenerated audios due to interference, commonly present in radio transmissions. Additionally, we present initial results of a classifier that uses such data for evaluation, indicating the benefits of using this dataset in the recognizer's training process. Such recognizer achieves an average result of 0.4116 in terms of character error rate in the noisy set (SNR = 30).
Generating Data Augmentation samples for Semantic Segmentation of Salt Bodies in a Synthetic Seismic Image Dataset
Jun 17, 2021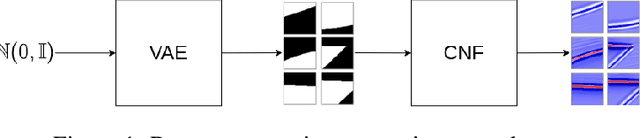
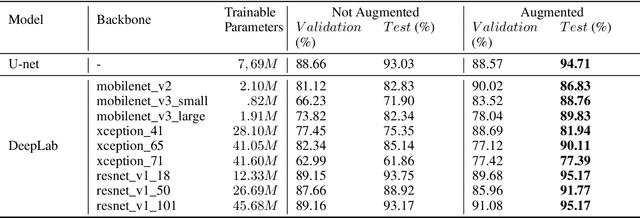
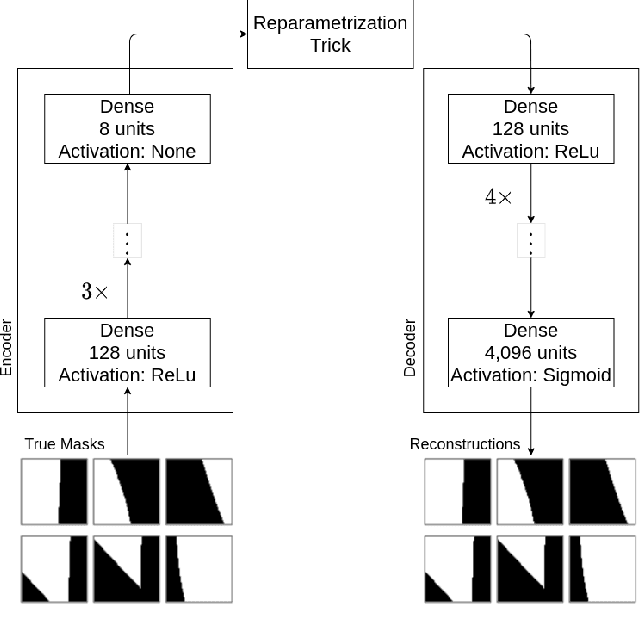
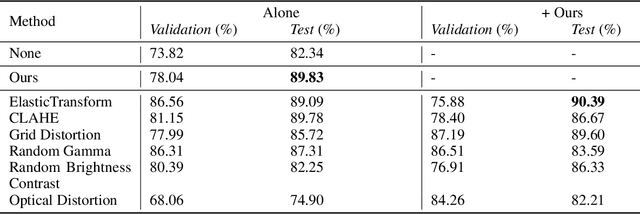
Nowadays, subsurface salt body localization and delineation, also called semantic segmentation of salt bodies, are among the most challenging geophysicist tasks. Thus, identifying large salt bodies is notoriously tricky and is crucial for identifying hydrocarbon reservoirs and drill path planning. This work proposes a Data Augmentation method based on training two generative models to augment the number of samples in a seismic image dataset for the semantic segmentation of salt bodies. Our method uses deep learning models to generate pairs of seismic image patches and their respective salt masks for the Data Augmentation. The first model is a Variational Autoencoder and is responsible for generating patches of salt body masks. The second is a Conditional Normalizing Flow model, which receives the generated masks as inputs and generates the associated seismic image patches. We evaluate the proposed method by comparing the performance of ten distinct state-of-the-art models for semantic segmentation, trained with and without the generated augmentations, in a dataset from two synthetic seismic images. The proposed methodology yields an average improvement of 8.57% in the IoU metric across all compared models. The best result is achieved by a DeeplabV3+ model variant, which presents an IoU score of 95.17% when trained with our augmentations. Additionally, our proposal outperformed six selected data augmentation methods, and the most significant improvement in the comparison, of 9.77%, is achieved by composing our DA with augmentations from an elastic transformation. At last, we show that the proposed method is adaptable for a larger context size by achieving results comparable to the obtained on the smaller context size.
A Cluster-Matching-Based Method for Video Face Recognition
Oct 20, 2020



Face recognition systems are present in many modern solutions and thousands of applications in our daily lives. However, current solutions are not easily scalable, especially when it comes to the addition of new targeted people. We propose a cluster-matching-based approach for face recognition in video. In our approach, we use unsupervised learning to cluster the faces present in both the dataset and targeted videos selected for face recognition. Moreover, we design a cluster matching heuristic to associate clusters in both sets that is also capable of identifying when a face belongs to a non-registered person. Our method has achieved a recall of 99.435% and a precision of 99.131% in the task of video face recognition. Besides performing face recognition, it can also be used to determine the video segments where each person is present.
A Clustering-Based Method for Automatic Educational Video Recommendation Using Deep Face-Features of Lecturers
Oct 09, 2020
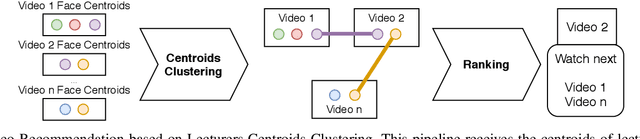
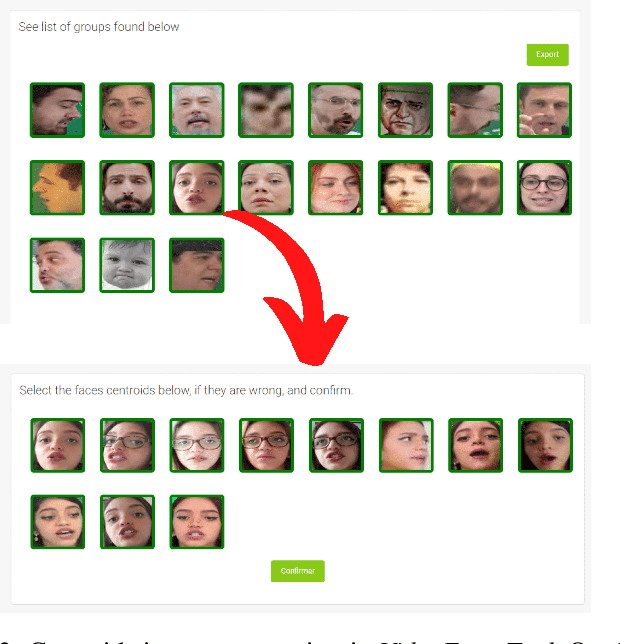

Discovering and accessing specific content within educational video bases is a challenging task, mainly because of the abundance of video content and its diversity. Recommender systems are often used to enhance the ability to find and select content. But, recommendation mechanisms, especially those based on textual information, exhibit some limitations, such as being error-prone to manually created keywords or due to imprecise speech recognition. This paper presents a method for generating educational video recommendation using deep face-features of lecturers without identifying them. More precisely, we use an unsupervised face clustering mechanism to create relations among the videos based on the lecturer's presence. Then, for a selected educational video taken as a reference, we recommend the ones where the presence of the same lecturers is detected. Moreover, we rank these recommended videos based on the amount of time the referenced lecturers were present. For this task, we achieved a mAP value of 99.165%.
Video Quality Enhancement Using Deep Learning-Based Prediction Models for Quantized DCT Coefficients in MPEG I-frames
Oct 09, 2020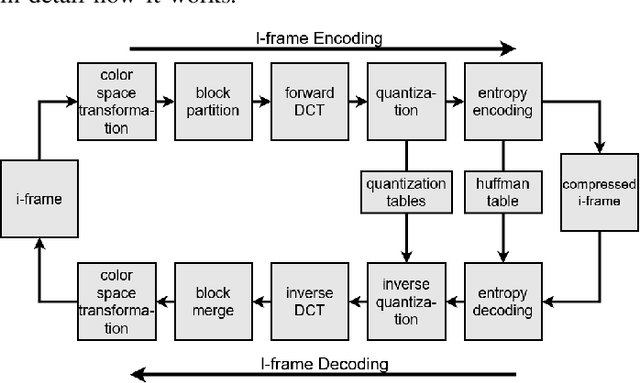


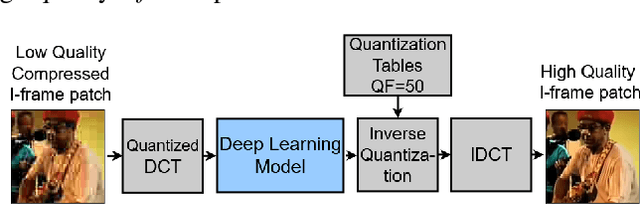
Recent works have successfully applied some types of Convolutional Neural Networks (CNNs) to reduce the noticeable distortion resulting from the lossy JPEG/MPEG compression technique. Most of them are built upon the processing made on the spatial domain. In this work, we propose a MPEG video decoder that is purely based on the frequency-to-frequency domain: it reads the quantized DCT coefficients received from a low-quality I-frames bitstream and, using a deep learning-based model, predicts the missing coefficients in order to recompose the same frames with enhanced quality. In experiments with a video dataset, our best model was able to improve from frames with quantized DCT coefficients corresponding to a Quality Factor (QF) of 10 to enhanced quality frames with QF slightly near to 20.
Seismic Shot Gather Noise Localization Using a Multi-Scale Feature-Fusion-Based Neural Network
May 07, 2020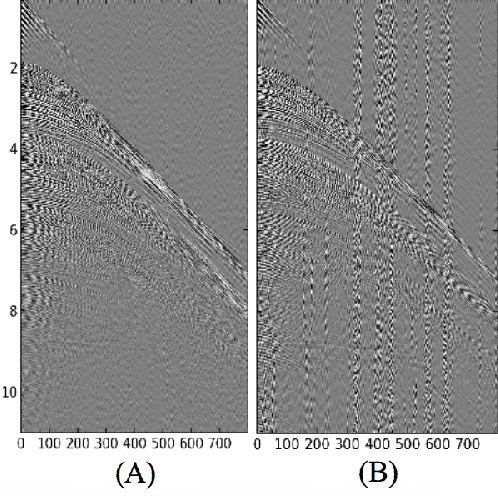

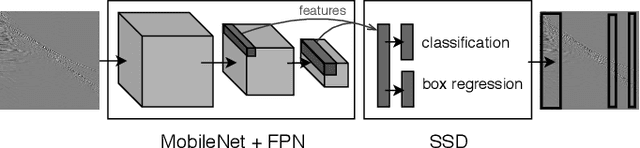
Deep learning-based models, such as convolutional neural networks, have advanced various segments of computer vision. However, this technology is rarely applied to seismic shot gather noise localization problem. This letter presents an investigation on the effectiveness of a multi-scale feature-fusion-based network for seismic shot-gather noise localization. Herein, we describe the following: (1) the construction of a real-world dataset of seismic noise localization based on 6,500 seismograms; (2) a multi-scale feature-fusion-based detector that uses the MobileNet combined with the Feature Pyramid Net as the backbone; and (3) the Single Shot multi-box detector for box classification/regression. Additionally, we propose the use of the Focal Loss function that improves the detector's prediction accuracy. The proposed detector achieves an AP@0.5 of 78.67\% in our empirical evaluation.
A Deep Convolutional Network for Seismic Shot-Gather Image Quality Classification
Dec 03, 2019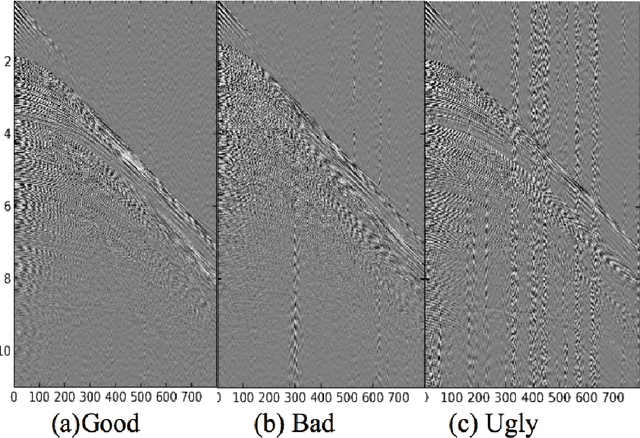
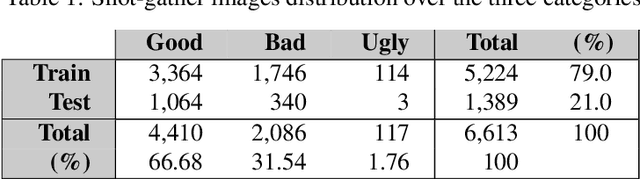

Deep Learning-based models such as Convolutional Neural Networks, have led to significant advancements in several areas of computing applications. Seismogram quality assurance is a relevant Geophysics task, since in the early stages of seismic processing, we are required to identify and fix noisy sail lines. In this work, we introduce a real-world seismogram quality classification dataset based on 6,613 examples, manually labeled by human experts as good, bad or ugly, according to their noise intensity. This dataset is used to train a CNN classifier for seismic shot-gathers quality prediction. In our empirical evaluation, we observe an F1-score of 93.56% in the test set.