 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric Hub: A metric library and practical selection workflow for use-case-driven data quality assessment in medical AI
Jan 30, 2026Machine learning (ML) in medicine has transitioned from research to concrete applications aimed at supporting several medical purposes like therapy selection, monitoring and treatment. Acceptance and effective adoption by clinicians and patients, as well as regulatory approval, require evidence of trustworthiness. A major factor for the development of trustworthy AI is the quantification of data quality for AI model training and testing. We have recently proposed the METRIC-framework for systematically evaluating the suitability (fit-for-purpose) of data for medical ML for a given task. Here, we operationalize this theoretical framework by introducing a collection of data quality metrics - the metric library - for practically measuring data quality dimensions. For each metric, we provide a metric card with the most important information, including definition, applicability, examples, pitfalls and recommendations, to support the understanding and implementation of these metrics. Furthermore, we discuss strategies and provide decision trees for choosing an appropriate set of data quality metrics from the metric library given specific use cases. We demonstrate the impact of our approach exemplarily on the PTB-XL ECG-dataset. This is a first step to enable fit-for-purpose evaluation of training and test data in practice as the base for establishing trustworthy AI in medicine.
The METRIC-framework for assessing data quality for trustworthy AI in medicine: a systematic review
Feb 21, 2024The adoption of machine learning (ML) and, more specifically, deep learning (DL) applications into all major areas of our lives is underway. The development of trustworthy AI is especially important in medicine due to the large implications for patients' lives. While trustworthiness concerns various aspects including ethical, technical and privacy requirements, we focus on the importance of data quality (training/test) in DL. Since data quality dictates the behaviour of ML products, evaluating data quality will play a key part in the regulatory approval of medical AI products. We perform a systematic review following PRISMA guidelines using the databases PubMed and ACM Digital Library. We identify 2362 studies, out of which 62 records fulfil our eligibility criteria. From this literature, we synthesise the existing knowledge on data quality frameworks and combine it with the perspective of ML applications in medicine. As a result, we propose the METRIC-framework, a specialised data quality framework for medical training data comprising 15 awareness dimensions, along which developers of medical ML applications should investigate a dataset. This knowledge helps to reduce biases as a major source of unfairness, increase robustness, facilitate interpretability and thus lays the foundation for trustworthy AI in medicine. Incorporating such systematic assessment of medical datasets into regulatory approval processes has the potential to accelerate the approval of ML products and builds the basis for new standards.
A Study of the Quality of Wikidata
Jul 23, 2021
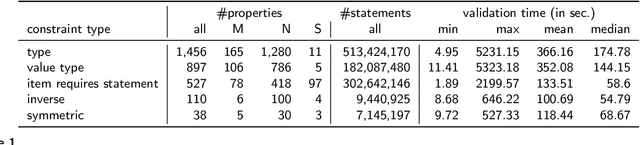
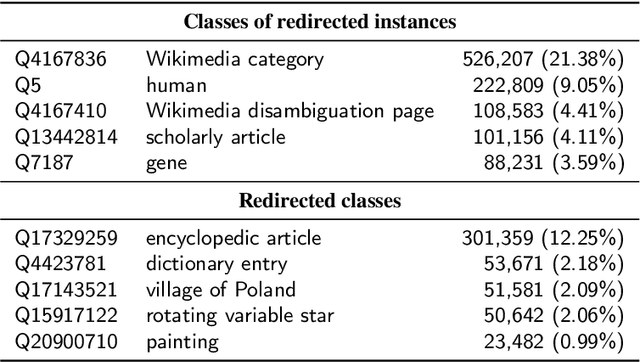
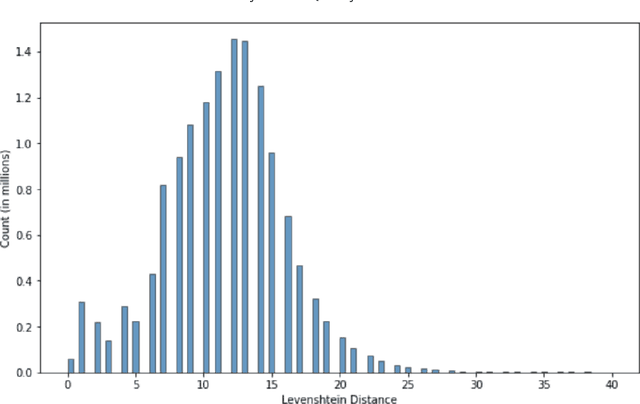
Wikidata has been increasingly adopted by many communities for a wide variety of applications, which demand high-quality knowledge to deliver successful results. In this paper, we develop a framework to detect and analyze low-quality statements in Wikidata by shedding light on the current practices exercised by the community. We explore three indicators of data quality in Wikidata, based on: 1) community consensus on the currently recorded knowledge, assuming that statements that have been removed and not added back are implicitly agreed to be of low quality; 2) statements that have been deprecated; and 3) constraint violations in the data. We combine these indicators to detect low-quality statements, revealing challenges with duplicate entities, missing triples, violated type rules, and taxonomic distinctions. Our findings complement ongoing efforts by the Wikidata community to improve data quality, aiming to make it easier for users and editors to find and correct mistakes.
A Cluster-Matching-Based Method for Video Face Recognition
Oct 20, 2020



Face recognition systems are present in many modern solutions and thousands of applications in our daily lives. However, current solutions are not easily scalable, especially when it comes to the addition of new targeted people. We propose a cluster-matching-based approach for face recognition in video. In our approach, we use unsupervised learning to cluster the faces present in both the dataset and targeted videos selected for face recognition. Moreover, we design a cluster matching heuristic to associate clusters in both sets that is also capable of identifying when a face belongs to a non-registered person. Our method has achieved a recall of 99.435% and a precision of 99.131% in the task of video face recognition. Besides performing face recognition, it can also be used to determine the video segments where each person is present.
Commonsense Knowledge in Wikidata
Aug 18, 2020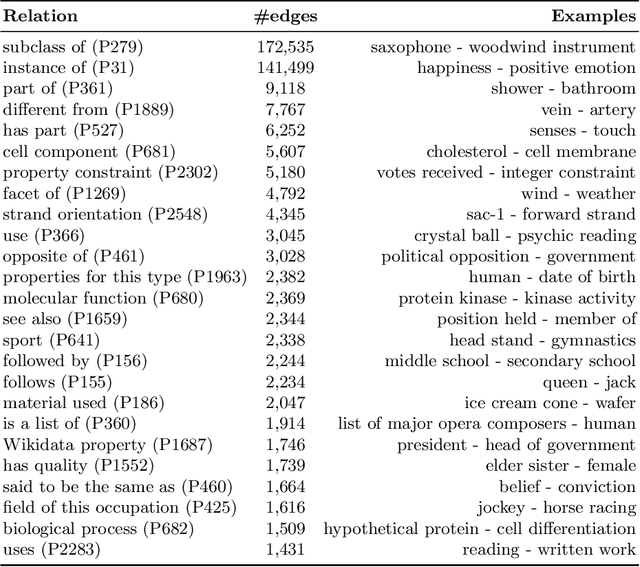
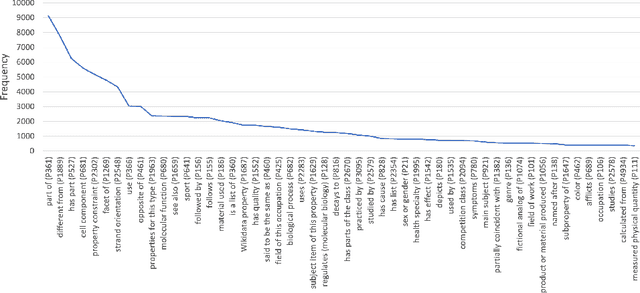
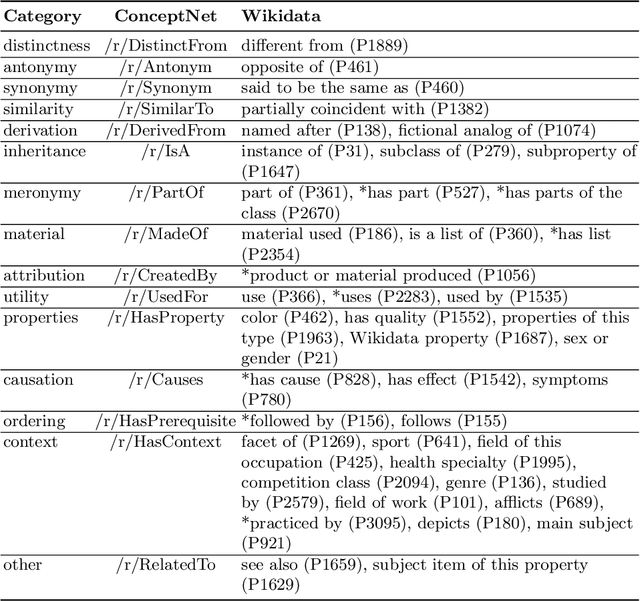

Wikidata and Wikipedia have been proven useful for reason-ing in natural language applications, like question answering or entitylinking. Yet, no existing work has studied the potential of Wikidata for commonsense reasoning. This paper investigates whether Wikidata con-tains commonsense knowledge which is complementary to existing commonsense sources. Starting from a definition of common sense, we devise three guiding principles, and apply them to generate a commonsense subgraph of Wikidata (Wikidata-CS). Within our approach, we map the relations of Wikidata to ConceptNet, which we also leverage to integrate Wikidata-CS into an existing consolidated commonsense graph. Our experiments reveal that: 1) albeit Wikidata-CS represents a small portion of Wikidata, it is an indicator that Wikidata contains relevant commonsense knowledge, which can be mapped to 15 ConceptNet relations; 2) the overlap between Wikidata-CS and other commonsense sources is low, motivating the value of knowledge integration; 3) Wikidata-CS has been evolving over time at a slightly slower rate compared to the overall Wikidata, indicating a possible lack of focus on commonsense knowledge. Based on these findings, we propose three recommended actions to improve the coverage and quality of Wikidata-CS further.
KGTK: A Toolkit for Large Knowledge Graph Manipulation and Analysis
May 29, 2020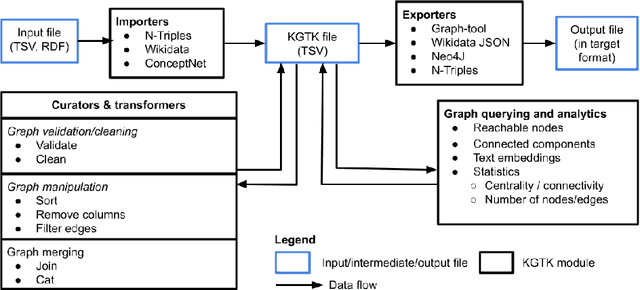
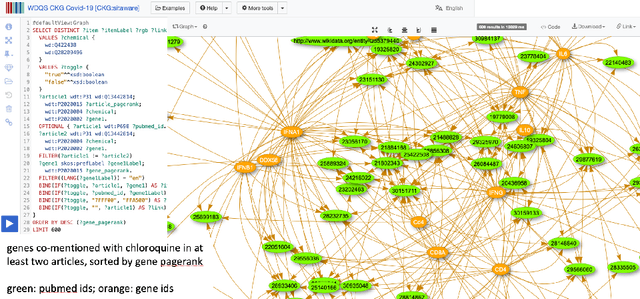
Knowledge graphs (KGs) have become the preferred technology for representing, sharing and adding knowledge to modern AI applications. While KGs have become a mainstream technology, the RDF/SPARQL-centric toolset for operating with them at scale is heterogeneous, difficult to integrate and only covers a subset of the operations that are commonly needed in data science applications. In this paper, we present KGTK, a data science-centric toolkit to represent, create, transform, enhance and analyze KGs. KGTK represents graphs in tables and leverages popular libraries developed for data science applications, enabling a wide audience of developers to easily construct knowledge graph pipelines for their applications. We illustrate KGTK with real-world scenarios in which we have used KGTK to integrate and manipulate large KGs, such as Wikidata, DBpedia and ConceptNet, in our own work.