 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric Hub: A metric library and practical selection workflow for use-case-driven data quality assessment in medical AI
Jan 30, 2026Machine learning (ML) in medicine has transitioned from research to concrete applications aimed at supporting several medical purposes like therapy selection, monitoring and treatment. Acceptance and effective adoption by clinicians and patients, as well as regulatory approval, require evidence of trustworthiness. A major factor for the development of trustworthy AI is the quantification of data quality for AI model training and testing. We have recently proposed the METRIC-framework for systematically evaluating the suitability (fit-for-purpose) of data for medical ML for a given task. Here, we operationalize this theoretical framework by introducing a collection of data quality metrics - the metric library - for practically measuring data quality dimensions. For each metric, we provide a metric card with the most important information, including definition, applicability, examples, pitfalls and recommendations, to support the understanding and implementation of these metrics. Furthermore, we discuss strategies and provide decision trees for choosing an appropriate set of data quality metrics from the metric library given specific use cases. We demonstrate the impact of our approach exemplarily on the PTB-XL ECG-dataset. This is a first step to enable fit-for-purpose evaluation of training and test data in practice as the base for establishing trustworthy AI in medicine.
The METRIC-framework for assessing data quality for trustworthy AI in medicine: a systematic review
Feb 21, 2024The adoption of machine learning (ML) and, more specifically, deep learning (DL) applications into all major areas of our lives is underway. The development of trustworthy AI is especially important in medicine due to the large implications for patients' lives. While trustworthiness concerns various aspects including ethical, technical and privacy requirements, we focus on the importance of data quality (training/test) in DL. Since data quality dictates the behaviour of ML products, evaluating data quality will play a key part in the regulatory approval of medical AI products. We perform a systematic review following PRISMA guidelines using the databases PubMed and ACM Digital Library. We identify 2362 studies, out of which 62 records fulfil our eligibility criteria. From this literature, we synthesise the existing knowledge on data quality frameworks and combine it with the perspective of ML applications in medicine. As a result, we propose the METRIC-framework, a specialised data quality framework for medical training data comprising 15 awareness dimensions, along which developers of medical ML applications should investigate a dataset. This knowledge helps to reduce biases as a major source of unfairness, increase robustness, facilitate interpretability and thus lays the foundation for trustworthy AI in medicine. Incorporating such systematic assessment of medical datasets into regulatory approval processes has the potential to accelerate the approval of ML products and builds the basis for new standards.
Uncertainty-aware Evaluation of Time-Series Classification for Online Handwriting Recognition with Domain Shift
Jun 17, 2022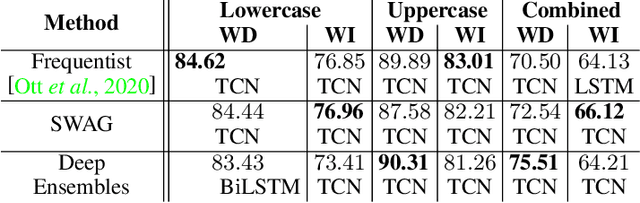
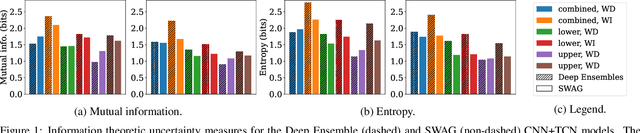
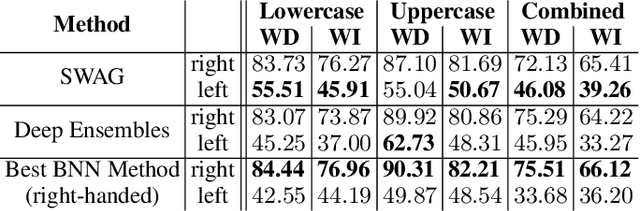
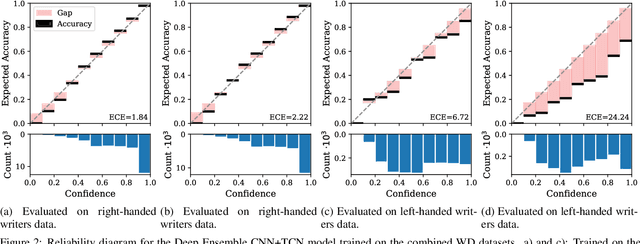
For many applications, analyzing the uncertainty of a machine learning model is indispensable. While research of uncertainty quantification (UQ) techniques is very advanced for computer vision applications, UQ methods for spatio-temporal data are less studied. In this paper, we focus on models for online handwriting recognition, one particular type of spatio-temporal data. The data is observed from a sensor-enhanced pen with the goal to classify written characters. We conduct a broad evaluation of aleatoric (data) and epistemic (model) UQ based on two prominent techniques for Bayesian inference, Stochastic Weight Averaging-Gaussian (SWAG) and Deep Ensembles. Next to a better understanding of the model, UQ techniques can detect out-of-distribution data and domain shifts when combining right-handed and left-handed writers (an underrepresented group).