 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilient Channel Charting Under Varying Radio Link Availability
Feb 04, 2026Channel charting (CC) has become a key technology for RF-based localization, enabling unsupervised radio fingerprinting, even in non line of sight scenarios, with a minimum of reference position labels. However, most CC models assume fixed-size inputs, such as a constant number of antennas or channel measurements. In practical systems, antennas may fail, signals may be blocked, or antenna sets may change during handovers, making fixed-input architectures fragile. Existing radio-fingerprinting approaches address this by training separate models for each antenna configuration, but the resulting training effort scales prohibitively with the array size. We propose Adaptive Positioning (AdaPos), a CC architecture that natively handles variable numbers of channel measurements. AdaPos combines convolutional feature extraction with a transformer-based encoder using learnable antenna identifiers and self-attention to fuse arbitrary subsets of CSI inputs. Experiments on two public real-world datasets (SISO and MIMO) show that AdaPos maintains state-of-the-art accuracy under missing-antenna conditions and replaces roughly 57 configuration-specific models with a single unified model. With AdaPos and our novel training strategies, we provide resilience to both individual antenna failures and full-array outages.
Position Paper: Rethinking AI/ML for Air Interface in Wireless Networks
Jun 13, 2025AI/ML research has predominantly been driven by domains such as computer vision, natural language processing, and video analysis. In contrast, the application of AI/ML to wireless networks, particularly at the air interface, remains in its early stages. Although there are emerging efforts to explore this intersection, fully realizing the potential of AI/ML in wireless communications requires a deep interdisciplinary understanding of both fields. We provide an overview of AI/ML-related discussions in 3GPP standardization, highlighting key use cases, architectural considerations, and technical requirements. We outline open research challenges and opportunities where academic and industrial communities can contribute to shaping the future of AI-enabled wireless systems.
Learning Encodings by Maximizing State Distinguishability: Variational Quantum Error Correction
Jun 13, 2025Quantum error correction is crucial for protecting quantum information against decoherence. Traditional codes like the surface code require substantial overhead, making them impractical for near-term, early fault-tolerant devices. We propose a novel objective function for tailoring error correction codes to specific noise structures by maximizing the distinguishability between quantum states after a noise channel, ensuring efficient recovery operations. We formalize this concept with the distinguishability loss function, serving as a machine learning objective to discover resource-efficient encoding circuits optimized for given noise characteristics. We implement this methodology using variational techniques, termed variational quantum error correction (VarQEC). Our approach yields codes with desirable theoretical and practical properties and outperforms standard codes in various scenarios. We also provide proof-of-concept demonstrations on IBM and IQM hardware devices, highlighting the practical relevance of our procedure.
5G-DIL: Domain Incremental Learning with Similarity-Aware Sampling for Dynamic 5G Indoor Localization
May 23, 2025Indoor positioning based on 5G data has achieved high accuracy through the adoption of recent machine learning (ML) techniques. However, the performance of learning-based methods degrades significantly when environmental conditions change, thereby hindering their applicability to new scenarios. Acquiring new training data for each environmental change and fine-tuning ML models is both time-consuming and resource-intensive. This paper introduces a domain incremental learning (DIL) approach for dynamic 5G indoor localization, called 5G-DIL, enabling rapid adaptation to environmental changes. We present a novel similarity-aware sampling technique based on the Chebyshev distance, designed to efficiently select specific exemplars from the previous environment while training only on the modified regions of the new environment. This avoids the need to train on the entire region, significantly reducing the time and resources required for adaptation without compromising localization accuracy. This approach requires as few as 50 exemplars from adaptation domains, significantly reducing training time while maintaining high positioning accuracy in previous environments. Comparative evaluations against state-of-the-art DIL techniques on a challenging real-world indoor dataset demonstrate the effectiveness of the proposed sample selection method. Our approach is adaptable to real-world non-line-of-sight propagation scenarios and achieves an MAE positioning error of 0.261 meters, even under dynamic environmental conditions. Code: https://gitlab.cc-asp.fraunhofer.de/5g-pos/5g-dil
Simplicity is Key: An Unsupervised Pretraining Approach for Sparse Radio Channels
May 19, 2025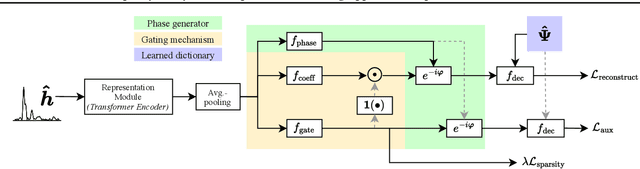

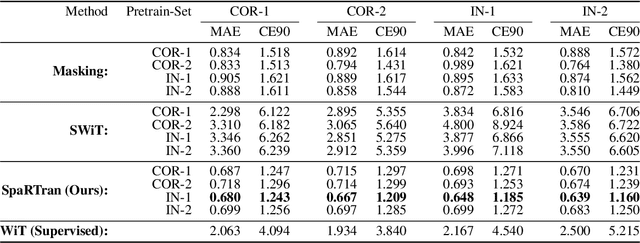
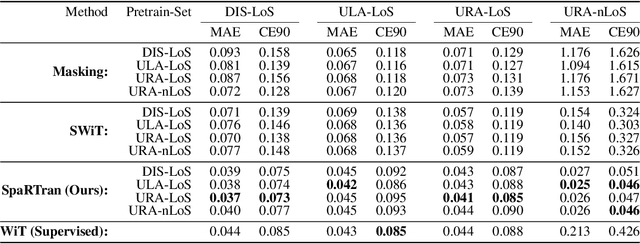
We introduce the Sparse pretrained Radio Transformer (SpaRTran), an unsupervised representation learning approach based on the concept of compressed sensing for radio channels. Our approach learns embeddings that focus on the physical properties of radio propagation, to create the optimal basis for fine-tuning on radio-based downstream tasks. SpaRTran uses a sparse gated autoencoder that induces a simplicity bias to the learned representations, resembling the sparse nature of radio propagation. For signal reconstruction, it learns a dictionary that holds atomic features, which increases flexibility across signal waveforms and spatiotemporal signal patterns. Our experiments show that SpaRTran reduces errors by up to 85 % compared to state-of-the-art methods when fine-tuned on radio fingerprinting, a challenging downstream task. In addition, our method requires less pretraining effort and offers greater flexibility, as we train it solely on individual radio signals. SpaRTran serves as an excellent base model that can be fine-tuned for various radio-based downstream tasks, effectively reducing the cost for labeling. In addition, it is significantly more versatile than existing methods and demonstrates superior generalization.
VAE-based Feature Disentanglement for Data Augmentation and Compression in Generalized GNSS Interference Classification
Apr 14, 2025Distributed learning and Edge AI necessitate efficient data processing, low-latency communication, decentralized model training, and stringent data privacy to facilitate real-time intelligence on edge devices while reducing dependency on centralized infrastructure and ensuring high model performance. In the context of global navigation satellite system (GNSS) applications, the primary objective is to accurately monitor and classify interferences that degrade system performance in distributed environments, thereby enhancing situational awareness. To achieve this, machine learning (ML) models can be deployed on low-resource devices, ensuring minimal communication latency and preserving data privacy. The key challenge is to compress ML models while maintaining high classification accuracy. In this paper, we propose variational autoencoders (VAEs) for disentanglement to extract essential latent features that enable accurate classification of interferences. We demonstrate that the disentanglement approach can be leveraged for both data compression and data augmentation by interpolating the lower-dimensional latent representations of signal power. To validate our approach, we evaluate three VAE variants - vanilla, factorized, and conditional generative - on four distinct datasets, including two collected in controlled indoor environments and two real-world highway datasets. Additionally, we conduct extensive hyperparameter searches to optimize performance. Our proposed VAE achieves a data compression rate ranging from 512 to 8,192 and achieves an accuracy up to 99.92%.
Optimizing Quantum Circuits via ZX Diagrams using Reinforcement Learning and Graph Neural Networks
Apr 04, 2025Quantum computing is currently strongly limited by the impact of noise, in particular introduced by the application of two-qubit gates. For this reason, reducing the number of two-qubit gates is of paramount importance on noisy intermediate-scale quantum hardware. To advance towards more reliable quantum computing, we introduce a framework based on ZX calculus, graph-neural networks and reinforcement learning for quantum circuit optimization. By combining reinforcement learning and tree search, our method addresses the challenge of selecting optimal sequences of ZX calculus rewrite rules. Instead of relying on existing heuristic rules for minimizing circuits, our method trains a novel reinforcement learning policy that directly operates on ZX-graphs, therefore allowing us to search through the space of all possible circuit transformations to find a circuit significantly minimizing the number of CNOT gates. This way we can scale beyond hard-coded rules towards discovering arbitrary optimization rules. We demonstrate our method's competetiveness with state-of-the-art circuit optimizers and generalization capabilities on large sets of diverse random circuits.
Benchmarking Quantum Reinforcement Learning
Jan 27, 2025Benchmarking and establishing proper statistical validation metrics for reinforcement learning (RL) remain ongoing challenges, where no consensus has been established yet. The emergence of quantum computing and its potential applications in quantum reinforcement learning (QRL) further complicate benchmarking efforts. To enable valid performance comparisons and to streamline current research in this area, we propose a novel benchmarking methodology, which is based on a statistical estimator for sample complexity and a definition of statistical outperformance. Furthermore, considering QRL, our methodology casts doubt on some previous claims regarding its superiority. We conducted experiments on a novel benchmarking environment with flexible levels of complexity. While we still identify possible advantages, our findings are more nuanced overall. We discuss the potential limitations of these results and explore their implications for empirical research on quantum advantage in QRL.
Robustness and Generalization in Quantum Reinforcement Learning via Lipschitz Regularization
Oct 28, 2024Quantum machine learning leverages quantum computing to enhance accuracy and reduce model complexity compared to classical approaches, promising significant advancements in various fields. Within this domain, quantum reinforcement learning has garnered attention, often realized using variational quantum circuits to approximate the policy function. This paper addresses the robustness and generalization of quantum reinforcement learning by combining principles from quantum computing and control theory. Leveraging recent results on robust quantum machine learning, we utilize Lipschitz bounds to propose a regularized version of a quantum policy gradient approach, named the RegQPG algorithm. We show that training with RegQPG improves the robustness and generalization of the resulting policies. Furthermore, we introduce an algorithmic variant that incorporates curriculum learning, which minimizes failures during training. Our findings are validated through numerical experiments, demonstrating the practical benefits of our approach.
Federated Learning with MMD-based Early Stopping for Adaptive GNSS Interference Classification
Oct 21, 2024



Federated learning (FL) enables multiple devices to collaboratively train a global model while maintaining data on local servers. Each device trains the model on its local server and shares only the model updates (i.e., gradient weights) during the aggregation step. A significant challenge in FL is managing the feature distribution of novel, unbalanced data across devices. In this paper, we propose an FL approach using few-shot learning and aggregation of the model weights on a global server. We introduce a dynamic early stopping method to balance out-of-distribution classes based on representation learning, specifically utilizing the maximum mean discrepancy of feature embeddings between local and global models. An exemplary application of FL is orchestrating machine learning models along highways for interference classification based on snapshots from global navigation satellite system (GNSS) receivers. Extensive experiments on four GNSS datasets from two real-world highways and controlled environments demonstrate that our FL method surpasses state-of-the-art techniques in adapting to both novel interference classes and multipath scenarios.